SVM分类基于花授粉算法优化实现SVM数据分类matlab源码
Posted 博主企鹅号1575304183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SVM分类基于花授粉算法优化实现SVM数据分类matlab源码相关的知识,希望对你有一定的参考价值。
一、神经网络-支持向量机
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。 1 数学部分 1.1 二维空间 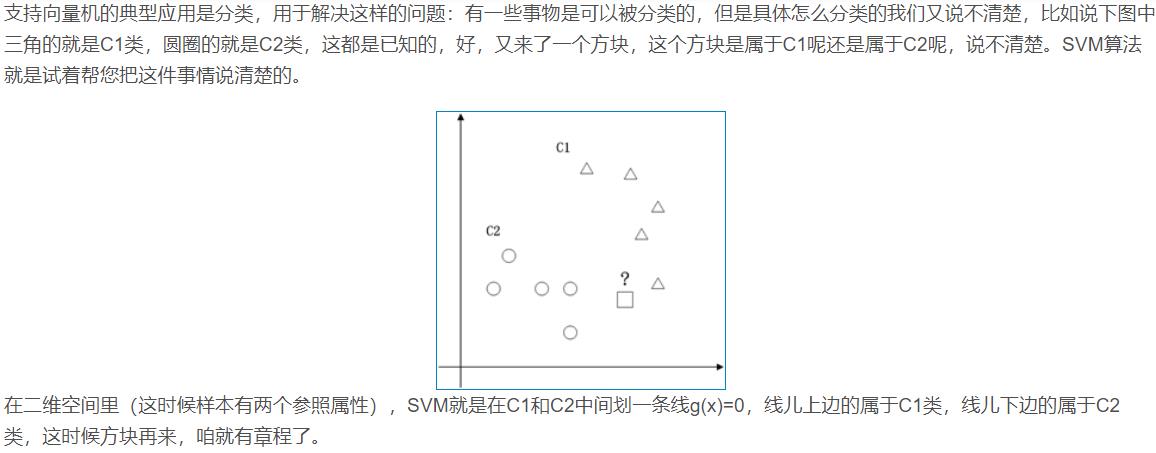
![]()

![]()

![]()
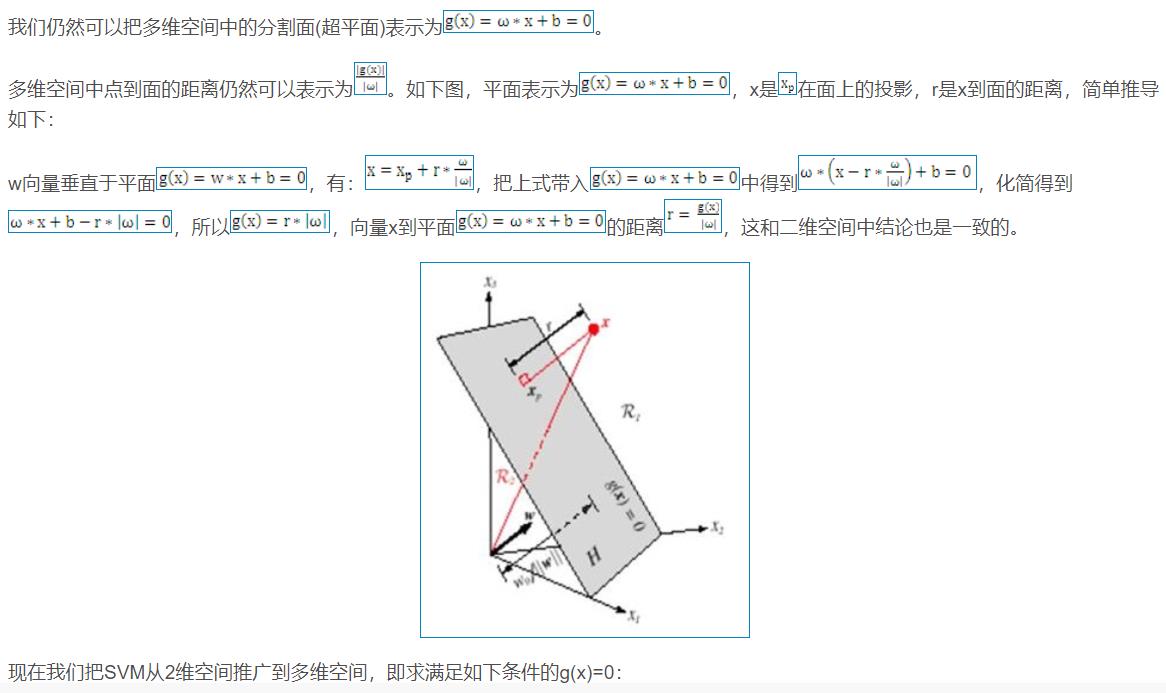
![]()

![]()

![]()

![]()

![]()

![]() 2 算法部分
2 算法部分 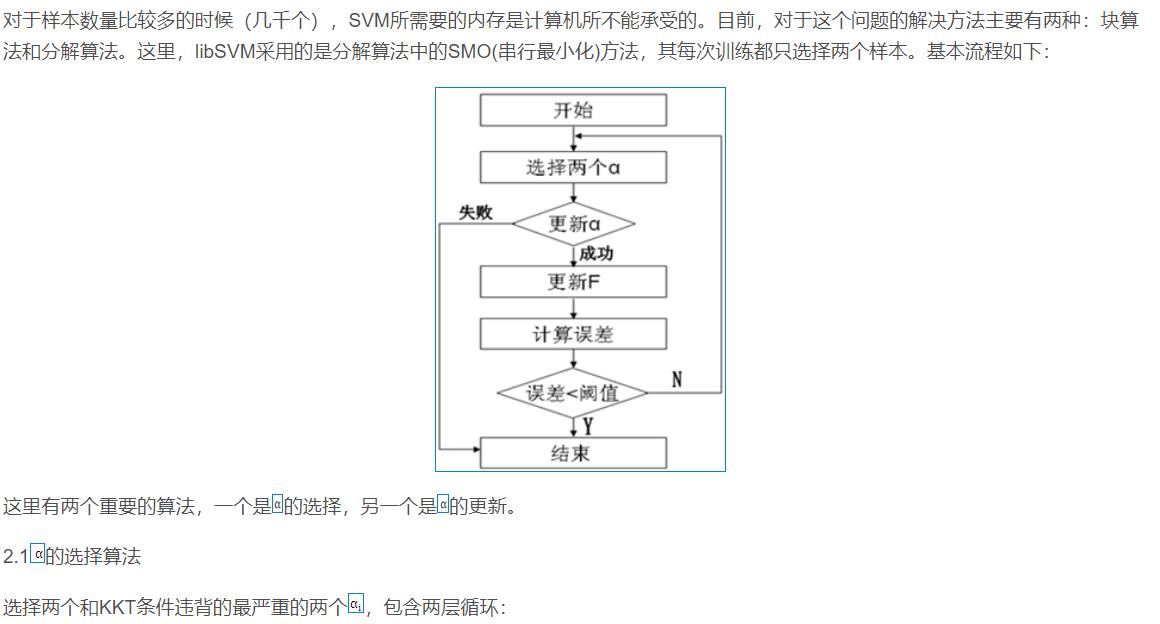
![]()
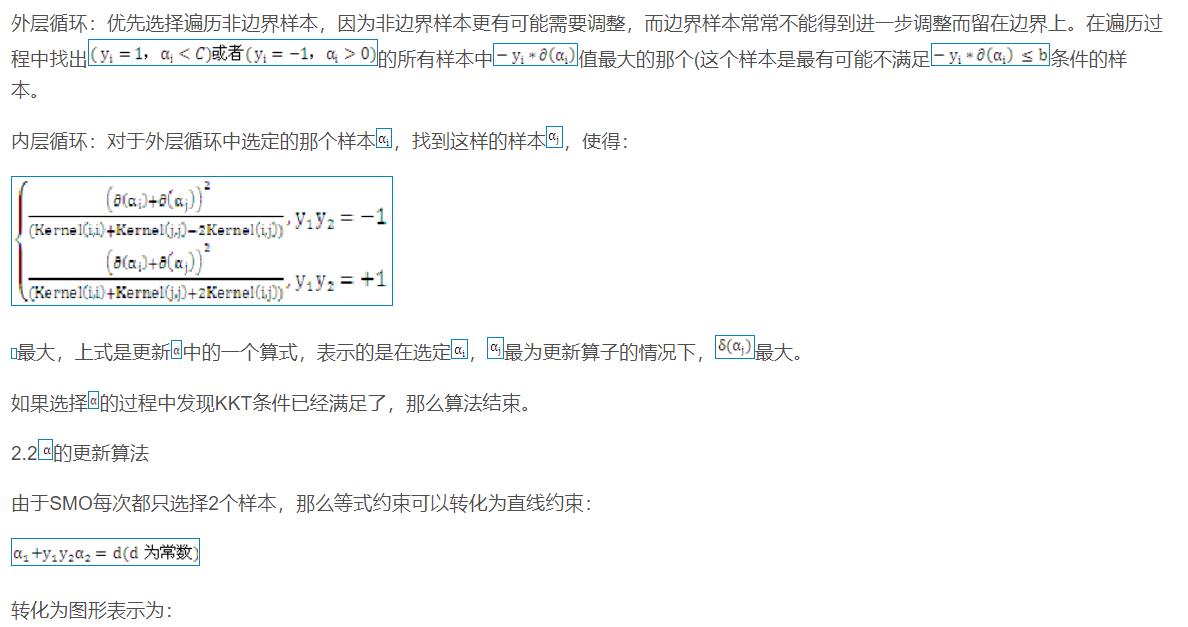
![]()
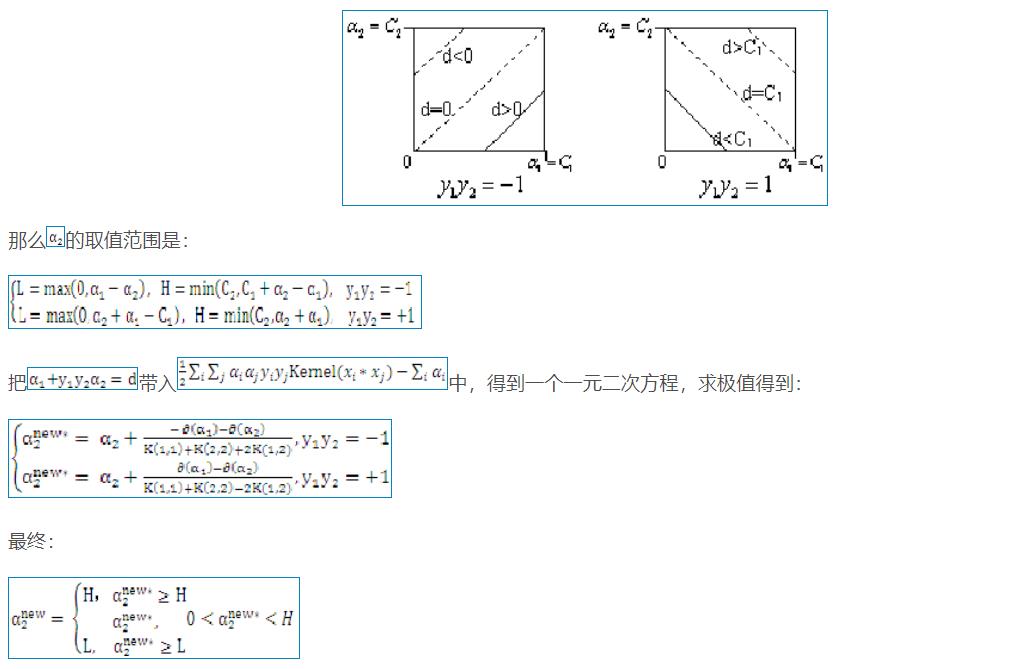
![]()

二、花授粉算法
花朵授粉算法( Flower Pollination Algorithm,FPA)是由英国剑桥大学学者Yang于2012年提出的,其基本思想来源于对自然界花朵自花授粉、异花授粉的模拟,是一种新的元启发式群智能随机优化技术 。算法中为了简便计算,假设每个植物仅有一朵花,每朵花只有一个配子,我们可以认为每一个配子都是解空间中的一个候选解。
Yang通过对花朵授粉的研究,抽象出以下四大规则:
1) 生物异花授粉被考虑为算法的全局探测行为,并由传粉者通过Levy飞行的机制实现全局授粉;
2)非生物自花授粉被视作算法的局部开采行为,或称局部授粉;
3)花朵的常性可以被认为是繁衍概率,他与两朵参与授粉花朵的相似性成正比例关系;
4)花朵的全局授粉与局部授粉通过转换概率 p∈[0,1]进行调节。 由于物理上的邻近性和风等因素的影响,在整个授粉活动中,转换概率 p是一个非常重要的参数。 文献[1]中对该参数的试验研究认为,取 p =0.8 更利于算法寻优。
直接上步骤(以多元函数寻优为例):
目标函数 : min g = f(x1,x2,x3,x4...........xd)
设置参量:N(候选解的个数),iter(最大迭代次数),p(转换概率),lamda(Levy飞行参数)
初始化花朵,随机设置一个NXd的矩阵;
计算适应度,即函数值;
获取最优解和最优解得位置;
A循环 1 : 1 :iter
B循环
if rand < p
全局授粉;
else
局部授粉;
end if
更新新一代的花朵与适应度(函数变量和函数值);
B循环end
获取新一代的最优解与最优解位置;
A循环end
全局更新公式:xi(t+1) = xi(t) + L(xi(t) - xbest(t)) L服从Levy分布,具体可以搜索布谷鸟算法。
局部更新公式:xi(t+1) = xi(t) + m(xj(t) - xk(t)) m是服从在[0,1]上均匀分布的随机数。其中,xj和xk是两个不同的个体
三、代码
function [mem,bestSol,bestFit,optima,FunctionCalls]=FPA(para)
% Default parameters
if nargin<1,
para=[50 0.25 500];
end
n=para(1); % Population size
p=para(2); % Probabibility switch
N_iter=para (3); % Number of iterations
phase = 1; %First state
phaseIte= [0.5,0.9,1.01]; %State vector
%Deb Function
d = 1;
Lb = 0;
Ub = 1;
optima = [.1;.3;.5;.7;.9];
% Initialize the population
for i=1:n,
Sol(i,:)=Lb+(Ub-Lb).*rand(1,d);
Fitness(i)=fitFunc(Sol(i,:)); %%Evaluate fitness function
end
% Initialice the memory
[mem,bestSol,bestFit,worstF] = memUpdate(Sol,Fitness, [], zeros(1,d), 100000000, 0, phase,d,Ub,Lb);
S = Sol;
FunctionCalls = 0;
% Main Loop
for ite = 1 : N_iter,
%For each pollen gamete, modify each position acoording
%to local or global pollination
for i = 1 : n,
% Switch probability
if rand>p,
L=Levy(d);
dS=L.*(Sol(i,:)-bestSol);
S(i,:)=Sol(i,:)+dS;
S(i,:)=simplebounds(S(i,:),Lb,Ub);
else
epsilon=rand;
% Find random flowers in the neighbourhood
JK=randperm(n);
% As they are random, the first two entries also random
% If the flower are the same or similar species, then
% they can be pollenated, otherwise, no action.
% Formula: x_i^{t+1}+epsilon*(x_j^t-x_k^t)
S(i,:)=S(i,:)+epsilon*(Sol(JK(1),:)-Sol(JK(2),:));
% Check if the simple limits/bounds are OK
S(i,:)=simplebounds(S(i,:),Lb,Ub);
end
Fitness(i)=fitFunc(S(i,:));
end
%Update the memory
[mem,bestSol,bestFit,worstF] = memUpdate(S,Fitness,mem,bestSol,bestFit,worstF,phase,d,Ub,Lb);
Sol = get_best_nest(S, mem, p);
FunctionCalls = FunctionCalls + n;
if ite/N_iter > phaseIte(phase)
%Next evolutionary process stage
phase = phase + 1;
[m,~]=size(mem);
%Depurate the memory for each stage
mem = cleanMemory(mem);
FunctionCalls = FunctionCalls + m;
end
end
%Plot the solutions (mem) founded by the multimodal framework
x = 0:.01:1;
y = ((sin(5.*pi.*x)).^ 6);
plot(x,y)
hold on
plot(mem(:,1),-mem(:,2),'r*');
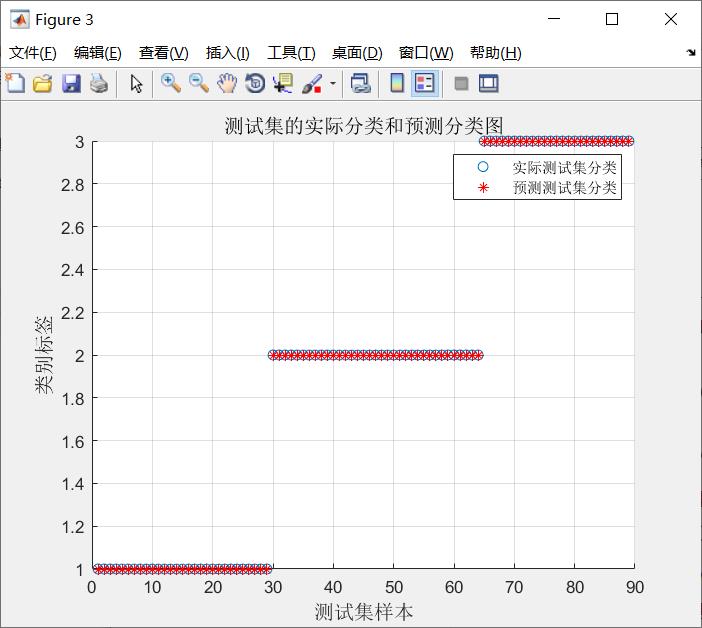
5.参考文献:
书籍《MATLAB神经网络43个案例分析》

以上是关于SVM分类基于花授粉算法优化实现SVM数据分类matlab源码的主要内容,如果未能解决你的问题,请参考以下文章
SVM分类基于灰狼算法优化SVM实现数据分类matlab源码
SVM分类基于灰狼算法优化SVM实现数据分类matlab源码
SVM分类基于遗传算法优化实现SVM数据分类matlab源码
SVM分类基于遗传算法优化实现SVM数据分类matlab源码