想学大数据?一篇长文带你走进大数据 | Spark的基础知识与操作
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了想学大数据?一篇长文带你走进大数据 | Spark的基础知识与操作相关的知识,希望对你有一定的参考价值。
1. Spark概述
1.1 背景
基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
Apache软件基金会最重要的三大分布式计算系统开源项目之一(Hadoop、Spark、Storm)
1.2 特点
-
运行速度快
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。 -
易用性好
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。 -
通用性强
-
随处运行
1.3 使用趋势
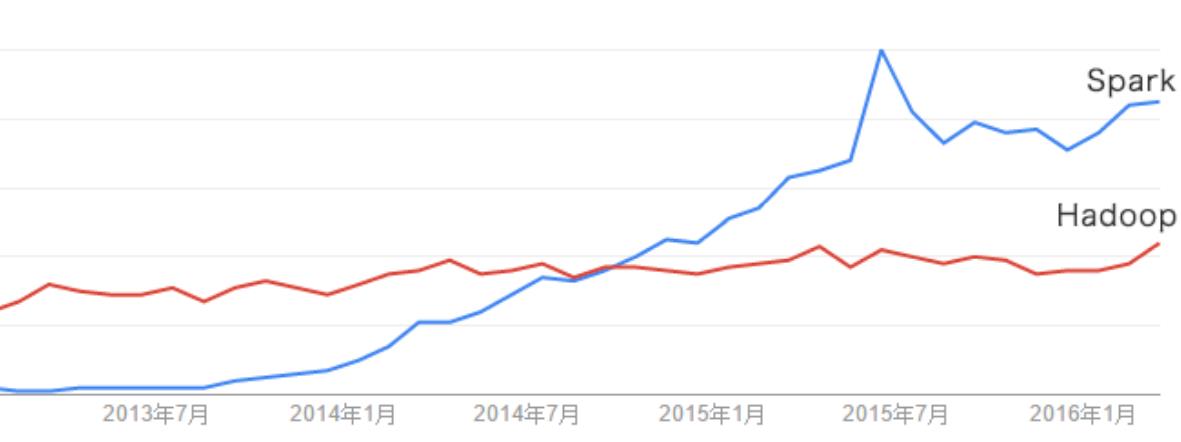
谷歌的大数据分析应用使用趋势
2. Spark生态系统
2.1 Spark与Hadoop的对比。
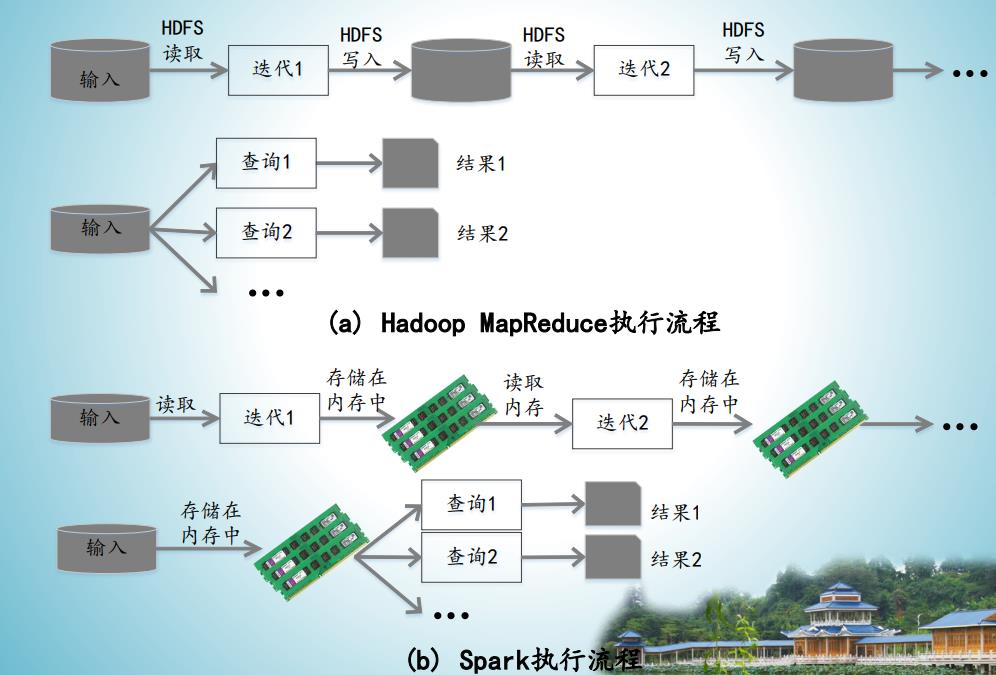
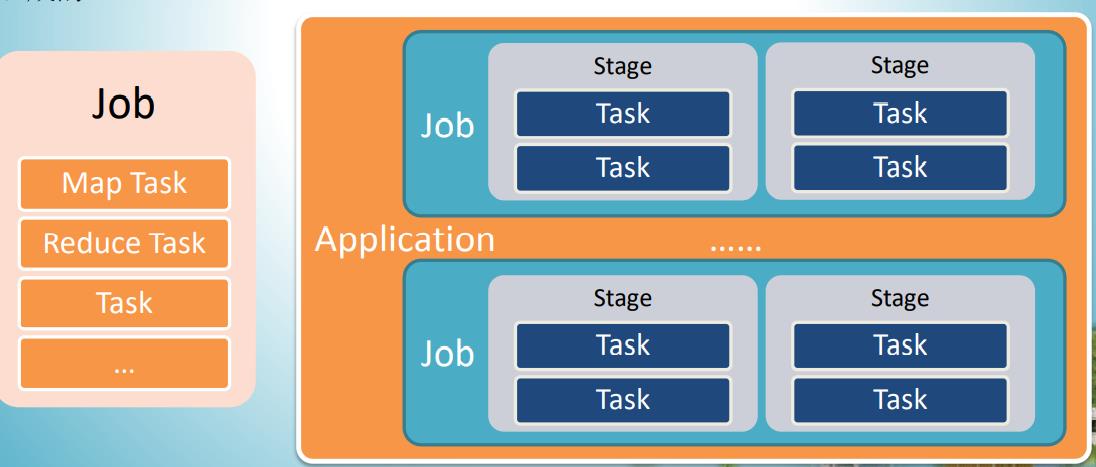
2.2 Job
Hadoop:
一个MapReduce程序就是一个Job,一个Job里有一个或多个Task,区分为Map Task和Reduce Task
Spark:
Job概念与Hadoop不同,在它之上还有Application,一个Application和一个SparkContext相关联,每个Application可以有一个或多个Job并行或串行运行;Job由Action触发Job里又包含多个Stage,Stage是以Shuffle进行划分的,每个Stage包含了由多个Task组成的Task Set。
2.3 容错率
-
Spark容错性比Hadoop更好:
Spark引进了弹性分布式数据集RDD的抽象,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对他们进行重建。 -
另外在RDD计算时,可以通过CheckPoint来实现容错,CheckPoint有两种方式:
CheckPoint Data 和Logging The Updates,用户可以控制采用哪种方式来实现容错。
2.4 通用性
Spark通用性也比Hadoop更好:
-
Hadoop只提供了Map和Reduce两种操作;
-
Spark提供了数据集操作类型很多种,大致分为
Transformation和Action两大类:- Transformation 包 括 Map 、 Filter 、 FlatMap 、 Sample 、 GroupByKey 、ReduceByKey 、 Union 、 Join 、 Cogroup 、 MapValues 、 Sort 、 Count 和PartionBy等多种操作类型。
- Action包括Collect、Reduce、Lookup和Save等操作。
- 另外各个处理节点之间的通信模型不再像Hadoop只有Shuffle一种模式,用户可以命名、物化,控制中间结果的存储、分区等
2.5 实际应用
在实际应用中,大数据处理主要包括以下三个类型:
- 复杂的批量数据处理:通常时间跨度在数十分钟到数小时之间
- 基于历史数据的交互式查询:通常时间跨度在数十秒到数分钟之间
- 基于实时数据流的数据处理:通常时间跨度在数百毫秒到数秒之间
目前对以上三种场景需求都有比较成熟的处理框架,
- 第一种情况可以用
Hadoop的MapReduce来进行批量海量数据处理, - 第二种情况可以
Impala进行交互式查询, - 对于第三中情况可以用
Storm分布式处理框架处理实时流式数据。
成本问题:
- 以上三者都是比较独立,各自一套维护成本比较高,会带来一些问题:
- 不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
- 不同的软件需要不同的开发和维护团队,带来了较高的使用成本
- 比较难以对同一个集群中的各个系统进行统一的资源协调和分配
而Spark的出现能够一站式平台满意以上需求
2.6 Spark生态系统组件的应用场景
| 应用场景 | 时间跨度 | 其他框架 | Spark生态系统中的组件 |
|---|---|---|---|
| 复杂的批量数据处理 | 小时级 | MapReduce、Hive | Spark |
| 基于历史数据的交互式查询 | 分钟级 、秒级 | Impala、Dremel、Drill | Spark SQL |
| 基于实时数据流的数据处理 | 毫秒、秒级 | Storm、S4 | Spark Streaming |
| 基于历史数据的数据挖掘 | - | Mahout | MLlib |
| 图结构数据的处理 | - | Pregel、Hama | GraphX |
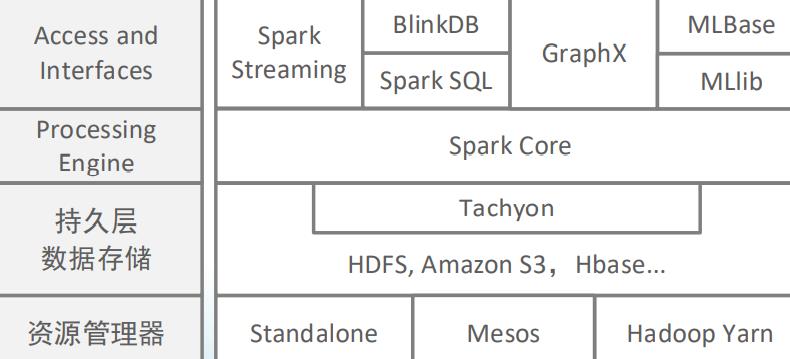
2.7 Spark组件
2.7.1 Spark Core
- 包含Spark的基本内容,包含任务调度,内存管理,容错机制等。
- Spark Core内部定义了RDDs(弹性分布式数据集)。RDDs代表横跨很多工作节点的数据集合,RDDs可以被并行的处理。
- Spark Core提供了很多APIs来创建和操作这些集合RDDs
2.7.2 Spark SQL
- Spark处理结构化数据的库。它支持通过SQL查询数据。就像HQL(Hive SQL)一样,并且支持很多数据源,像Hive表、JSON等。
- Shark是一种较老的基于Spark的SQL项目,它是基于Hive修改的,它现在已经被Spark-SQL代替了。
2.7.3 Spark Streaming
- 实时数据流处理组件,类似Storm
- Spark Streaming提供了API来操作实时流数据。
2.7.4 MLlib
- Spark 有一个包含通用机器学习功能的包,就是MLlib(machine learning lib)
- MLlib 包含了分类,聚类,回归,协同过滤算法,还包括模块评估和数据导入。
- 它还提供了一些低级的机器学习原语,包括通用梯度下降优化算法。
- 除此之外,还支持集群上的横向扩展。
2.7.5 Graphx
- 是处理图的库,并进行图的并行计算。就像Spark Streaming和Spark SQL一样,Graphx也继承了Spark RDD API,同时允许创建有向图。
- Graphx提供了各种图的操作,例如subgraph和mapVertices,也包含了常用的图算法,例如PangeRank等。
2.7.6 Cluster Managers
- Cluster Managers就是集群管理。Sparkl能够运行在很多cluster managers上面,包括Hadoop YARN,Apache Mesos和Spark自带的单独调度器。
- 如果你有了Hadoop Yarn或是Mesos集群,那么Spark对这些集群管理工具的支持,使Spark应用程序能够在这些集群上面运行。
3. Spark运行架构
3.1 基本概念
- RDD:是ResillientResillient Distributed DatasetDistributed Dataset(弹性分布式数据集)的简称,是分布式内存的一个抽象概念, 提供了一种高度受限的共享内存模型
- DAG:是Directed Acyclic Graph(有向无环图)的简称,反映 RDD 之间的依赖关系
- Executor:是运行在工作节点 WorkerNode)的一个进程,负责运行 Task
- Application:用户编写的 Spark 应用程序
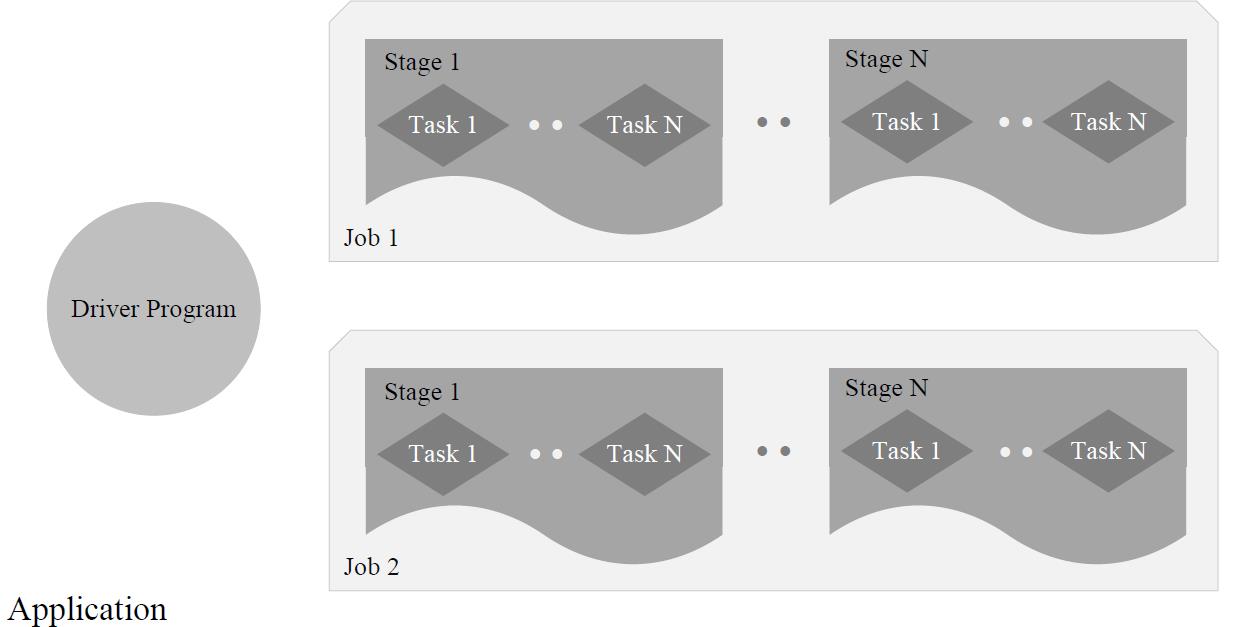
- Task:运行在 Executor 上的工作单元
- Job:一个 Job 包含多个 RDD 及作用于相应 RDD上的各种操作
- Stage:是 Job 的基本调度单位,一个 Job 会分为多组 Task ,每组 Task 被称为 Stage或者也被称为 TaskSet ,代表了一组关联的、相互之间没有 Shuffle 依赖关系的任务组成的任务集
3.2 架构设计
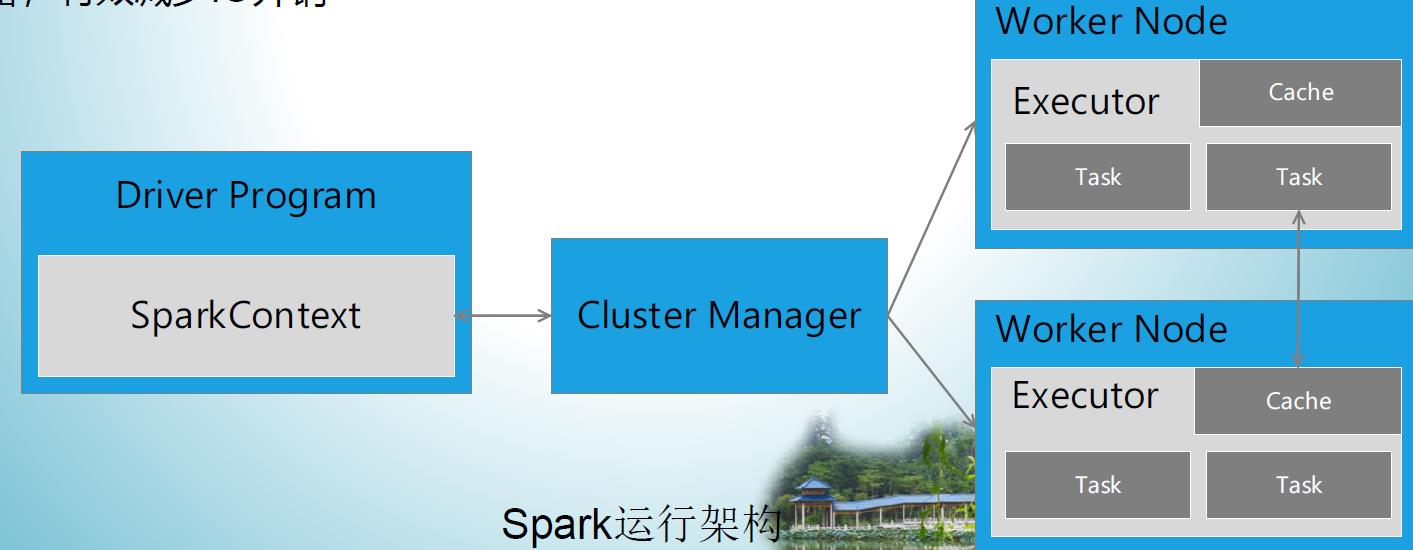
- Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)
- 资源管理器可以自带或Mesos或YARN
- 与Hadoop MapReduce计算框架相比,Spark所采用的Executor有两个优点:
- 一是利用多线程来执行具体的任务,减少任务的启动开销
- 二是Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销
-
一个 Application 由一个 Driver 和若干个 Job 构成,一个 Job 由多个 Stage 构成,一个Stage 由多个没有 Shuffle 关系的 Task 组成
-
当执行一个 Application 时, Driver 会向集群管理器申请资源,启动 Executor ,并向 Executor 发送应用程序代码和文件,然后在 Executor 上执行 Task ,运行结束后执行结果会返回给 Driver 或者写到 HDFS 或者其他数据库中
3.3 Spark 运行基本流程
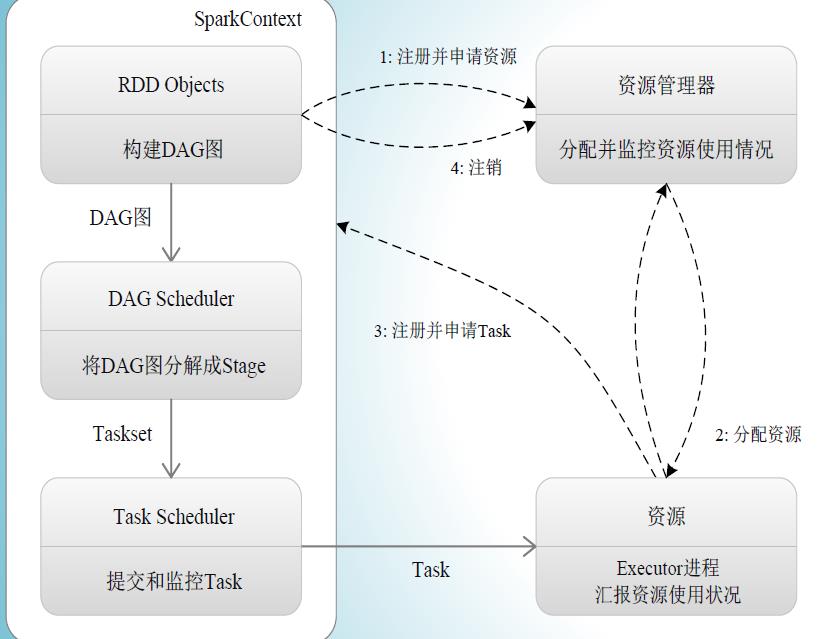
- 首先为应用构建起基本的运行环境,即由 Driver 创建一个 SparkContext ,进行资源的申请、任务的分配和监控
- 资源管理器为 Executor 分配资源,并启动 Executor 进程
- SparkContext 根据 RDD 的依赖关系构建 DAG 图, DAG 图提交给 DAGScheduler 解析成 Stage ,然后把一个个TaskSet 提交给底层调度器,Task Scheduler处理; Executor 向 SparkContext 申请 Task,Task Scheduler ,将 Task 发放给 Executor 运行,并提供应用程序代码
- Task 在 Executor 上运行,把执行结果,反馈给 Task Scheduler ,然后反馈给 DAG Scheduler ,运行完毕后写入数据并释放所有资源
特点:
- 每个
Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可Task采用了数据本地性和推测执行等优化机制
3.4 Spark 运行原理
3.4.1 RDDs
- Resilient Distributed Datasets (弹性分布式数据集 RDDs
- RDDs 是 Spark 的分发数据和计算的基础抽象类,是
Spark的核心概念; - 在 Spark 中,所有的计算都是通过
RDDs的创建、转换、操作完成的。 - RDDs 具有
lineage graph(血统关系图) - 一个 RDD 就是一个不可改变的分布式集合对象,内部有许多
partitions组成,每个partition 都包括一部分数据,这些partitions可以在集群的不同节点上计算; - Partition 是
Spark中的并行处理单元。
3.4.2 RDD运行原理
- RDD 提供了一组丰富的操作以支持常见的数据运算,分为
“动作 Action和“转换 Transformation两种类型 - RDD 提供的转换接口都非常简单,都是类似
map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改 (不适合网页爬虫 - 表面上 RDD 的功能很受限、不够强大 实际上
RDD已经被实践证明可以高效地表达,许多框架的编程模型 比如MapReduce、SQL、Pregel - Spark 用 Scala 语言实现了
RDD的API,程序员可以通过调用API实现对RDD的各种操作
RDD典型的执行顺序如下:
- RDD读入外部数据源进行创建
- RDD经过一系列的转换(Transformation)操作,每一次都会产生不同的RDD,供给下一个转换操作使用
- 最后一个RDD经过“动作”操作进行转换,并输出到外部数据源
- 这一系列处理称为一个Lineage(血缘关系),即DAG拓扑排序的结果
RDD的 transformations 和 actions
RDD 运行过程:
- 创建 RDD 对象;
- SparkContext 负责计算 RDD 之间的依赖关系,构建 DAG
- DAGScheduler 负责把 DAG 图分解成多个 Stage ,每个 Stage 中包含了多个Task ,每个 Task 会被 TaskScheduler 分发给各个 WorkerNode 上的 Executor 去执行。
3.4.3 Scala
Scala 是一门现代的多范式编程语言,运行于 Java 平台( JVM Java 虚拟机),并兼容现有的 Java 程序
Scala 的特性:
- Scala 具备强大的并发性,支持函数式编程,可以更好地支持分布式系统
- Scala 语法简洁,能提供优雅的
API - Scala 兼容
Java,运行速度快,且能融合到Hadoop生态圈中 - Scala 是 Spark 的主要编程语言,但
Spark还支持Java、Python、R作为编程语言 - Scala 的优势是提供了 REPL
Read Eval Print Loop,交互式解释器 ),提高程序开发效率
4. SparkSQL
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
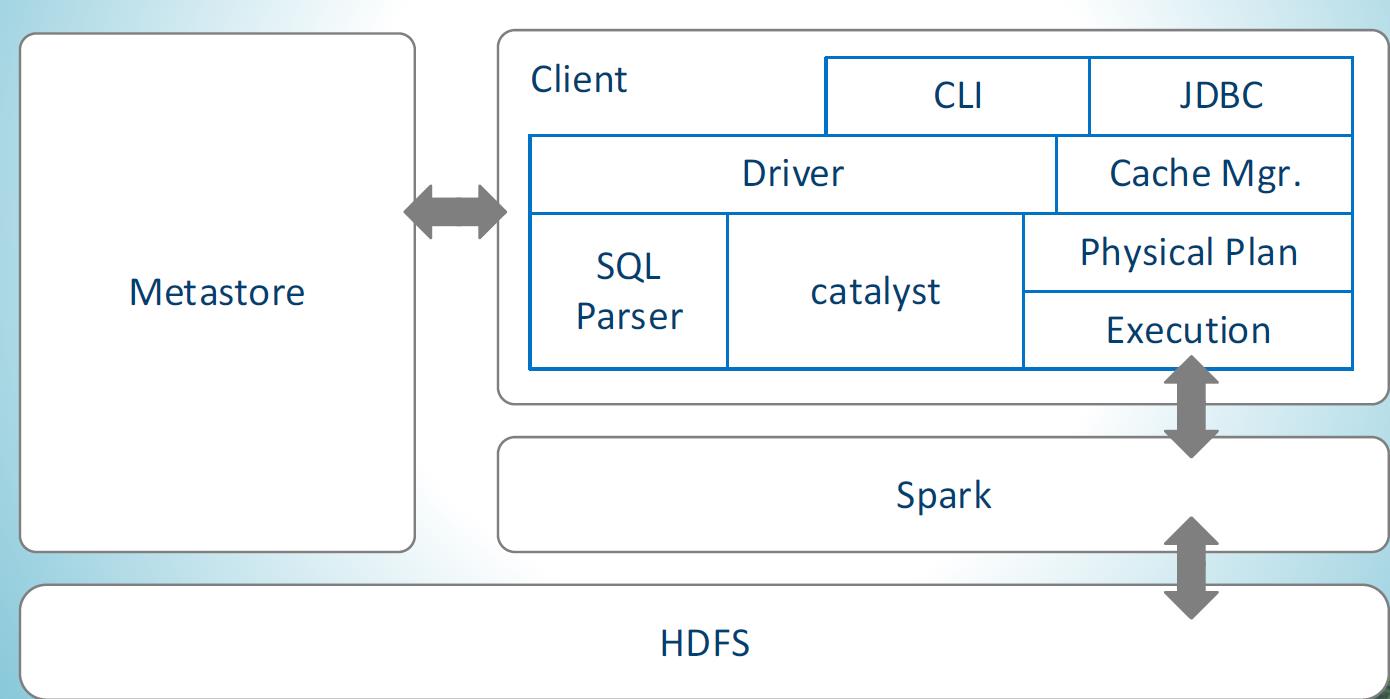
- Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据
- Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范

5. Spark编程实践
5.1 编程环境
- 操作系统:Linux(建议Ubuntu18.04或Ubuntu16.04);
- Hadoop版本:3.1.3或2.7.1;
- JDK版本:1.8;
- Hadoop伪分布式配置
- Spark 2.4.8或自编译版本
- Scala 2.11.8或2.8.0
5.2 实验步骤:
5.2.1 Spark环境配置
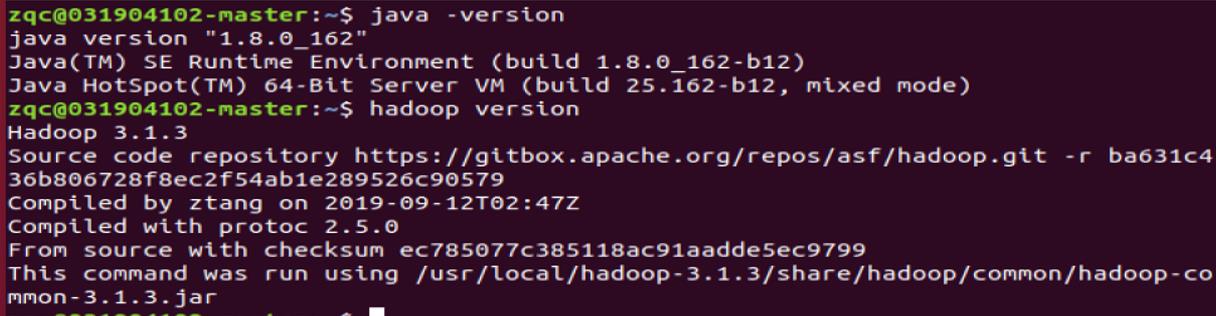
- 检测java环境和hadoop环境。
- 安装包下载

Scala: https://www.scala-lang.org/download/all.html
Spark: http://spark.apache.org/downloads.html
关于 Spark 官网下载页面中 Choose a package type 几个选项说明:
- Source Code:spark 源码,需要编译才能使用,可以自由设置编译选项;
- Pre-build with user-provide Hadoop:属于 Hadoop free 版本,用应用到任意 Hadoop 版本;
- Pre-build for Hadoop 2.7、Pre-build for Hadoop 2.6:分别基于 Hadoop2.7、2.6 的预先编译版本,需要与本机安装的 Hadoop 版本对应使用;
- Pre-build with Scala 2.12 and user provided Apache Hadoop:预先编译的版本,包含了 Scala2.12,可应用于任意 Hadoop 版本。
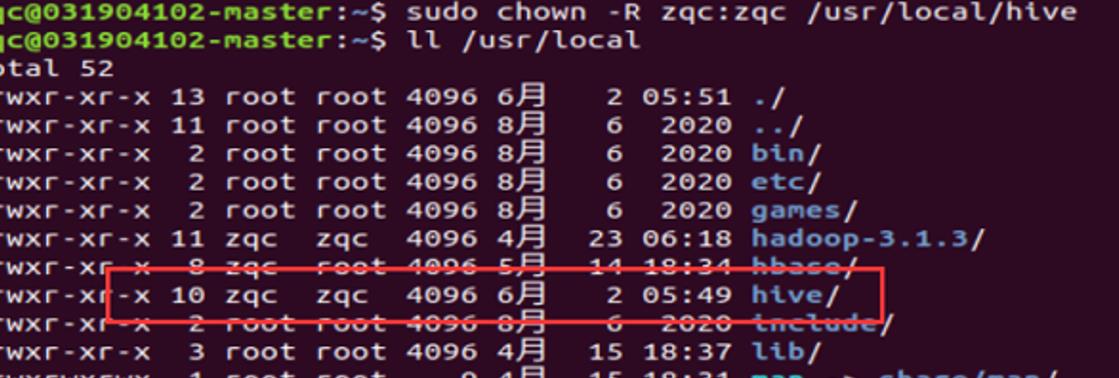
- 安装scala
解压安装包(sudo tar -zxvf scala-2.11.8.tgz -C /usr/local/),并更改 scala

所属用户和用户组为当前用户及所在组。

配置环境变量:添加
S
C
A
L
A
H
O
M
E
变
量
为
s
c
a
l
a
解
压
路
径
,
并
在
SCALA_HOME 变量为 scala 解压路径,并在
SCALAHOME变量为scala解压路径,并在PATH 变量添加相应 的 bin 目录。


使得环境生效

查看是否安装成功

已经成功了!
- 安装spark
解压安装包(sudo tar -zxvf spark-2.4.8-bin-without-hadoop.tgz -C /usr/local/),更改所属用户及用户组,并将目录重命名为 spark-2.4.8,方便后续配置:

更改所属用户及用户组

并将目录重命名为 spark-2.4.8

配置环境变量,添加 SPARK_HOME 变量,并在 PATH 变量中添加相应的 bin 目录。
export SPARK_HOME=/usr/local/spark-2.4.8
export PATH=
P
A
T
H
:
PATH:
PATH:SPARK_HOME/bin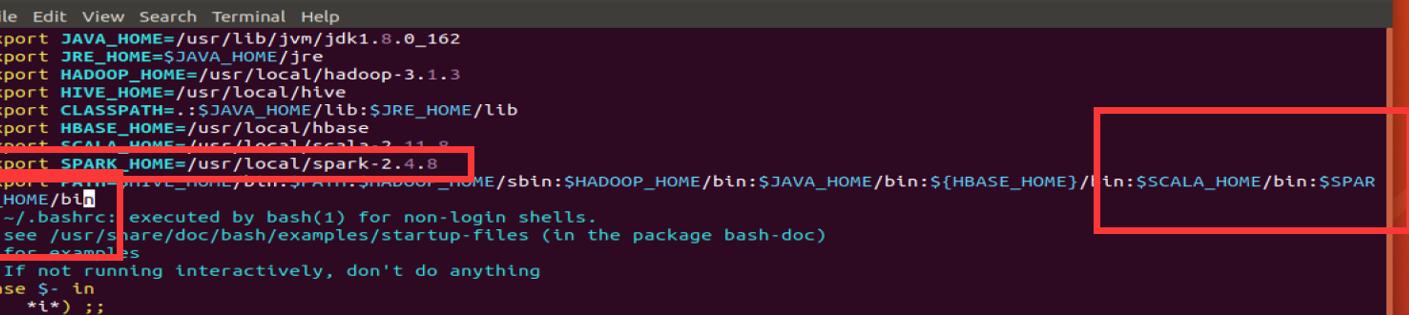

Spark 配置文件配置:
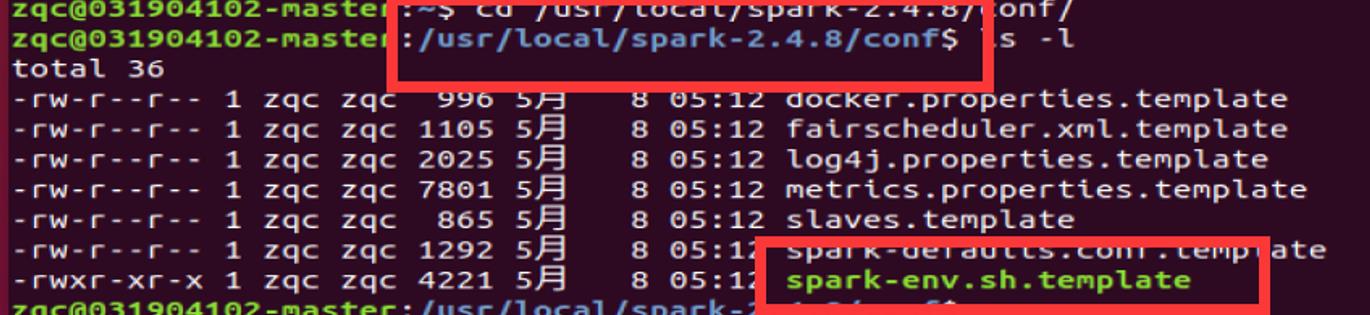
将 spark-env.sh.template 文件复制为 spark-env.sh 文件:

并配置内容如下:
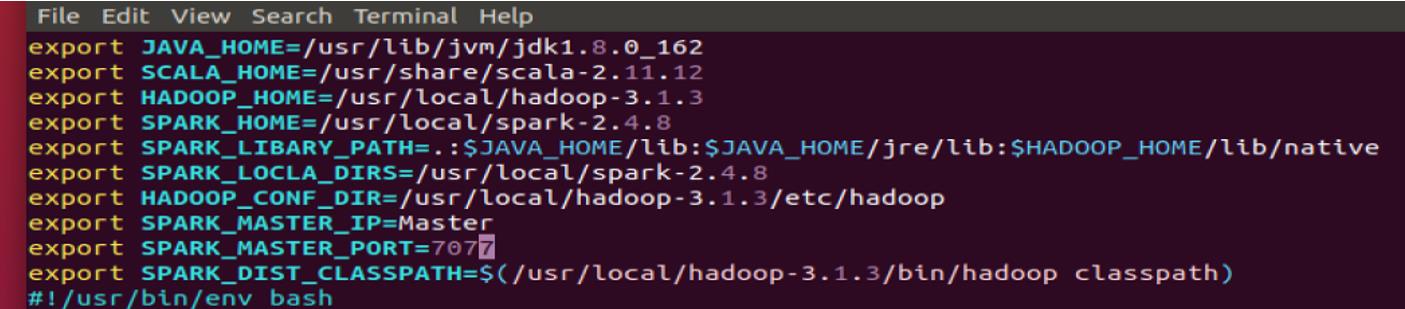
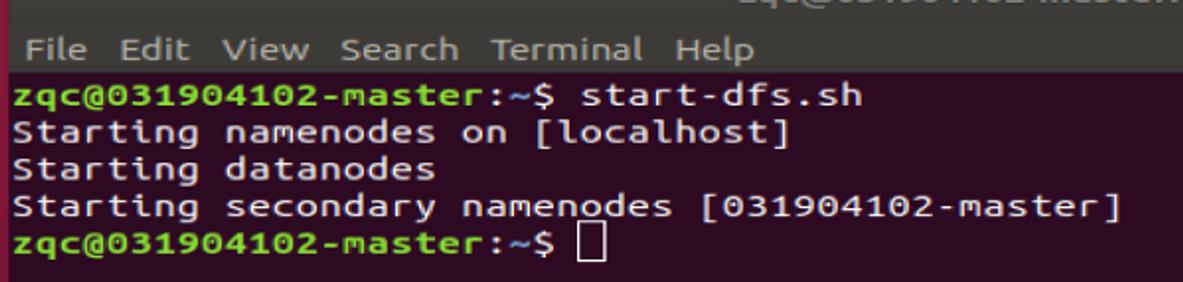
启动 spark:启动 spark 之前要先启动 HDFS

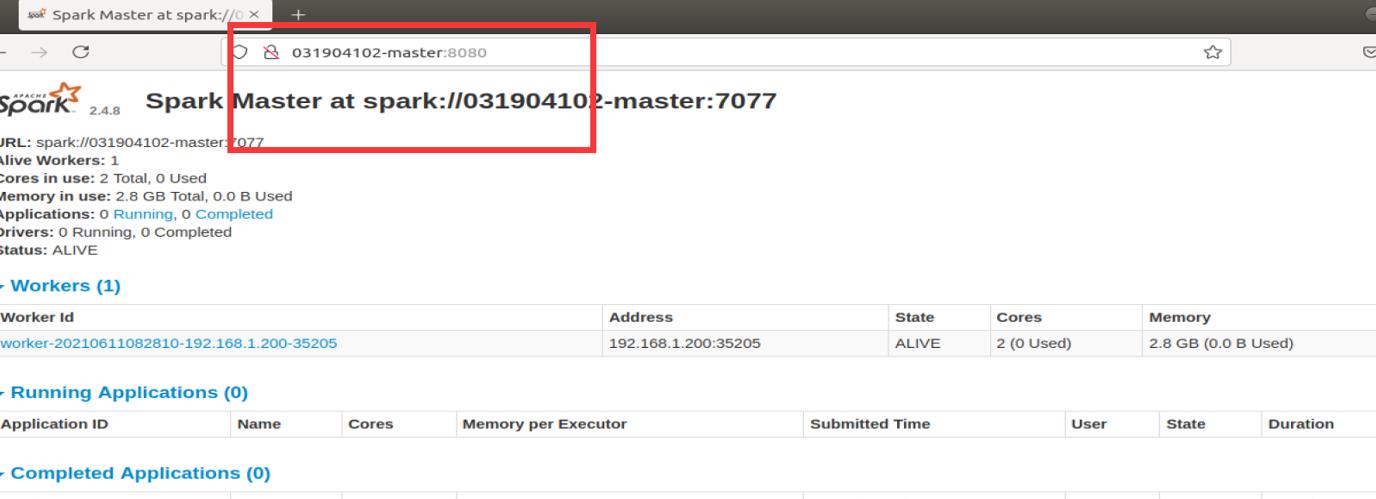
启动之后网页访问 Master:8080 可以查看当前 Spark workers 状态。
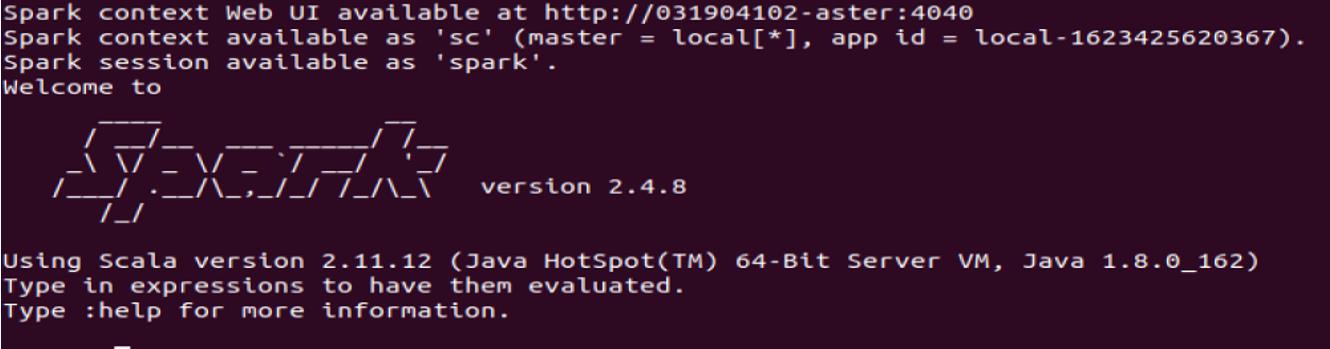
Spark-shell 进入spark shell
会有这种错误
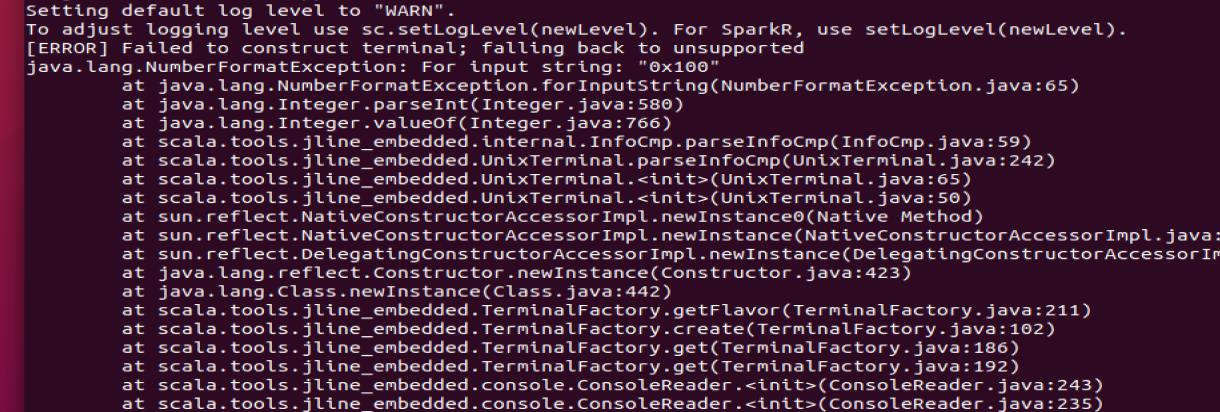
但不需要慌张!不影响使用 scala 使用,如果要解决,可以通过添加系统环境变量。export TERM=xterm-color
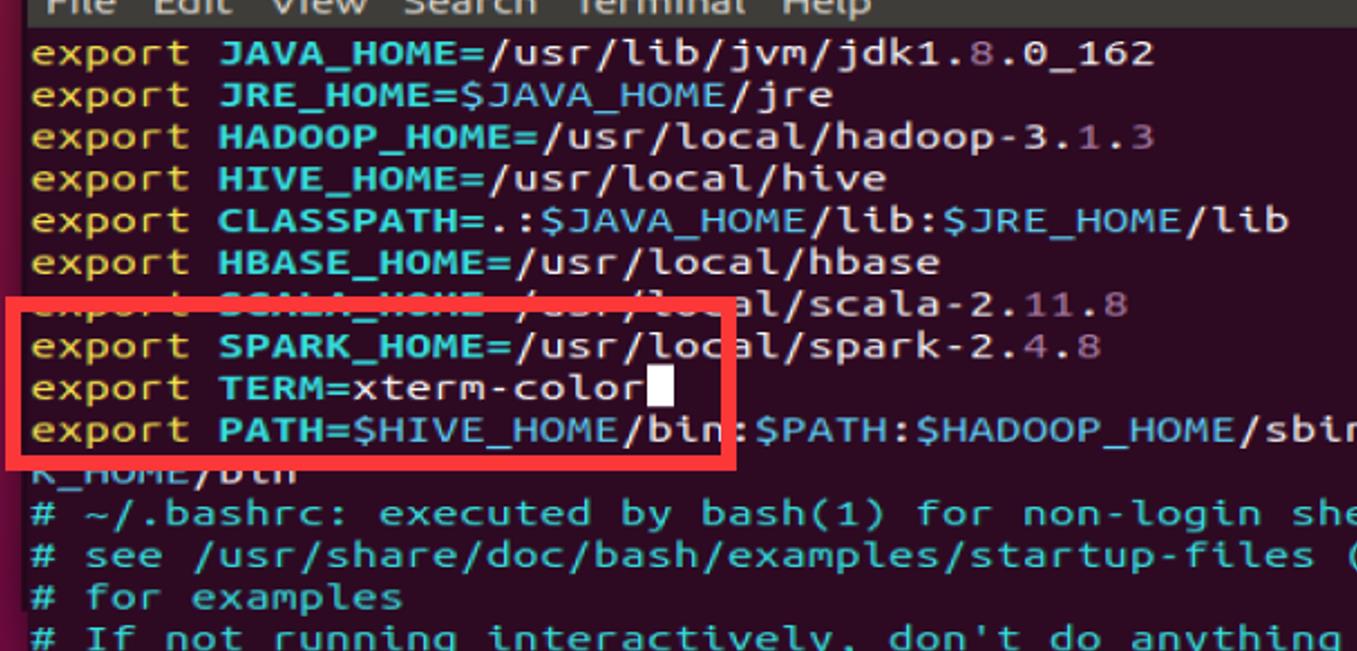

就不会有了
1.5 举个例子
通 过 spark-submit 命令运行 spark 自 带 实 例 , spark 自 带 实 例 都 在
SPARK_HOME/examples/jars/spark-examples_2.11-2.4.8.jar 中提供:
spark-submit --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.8.jar
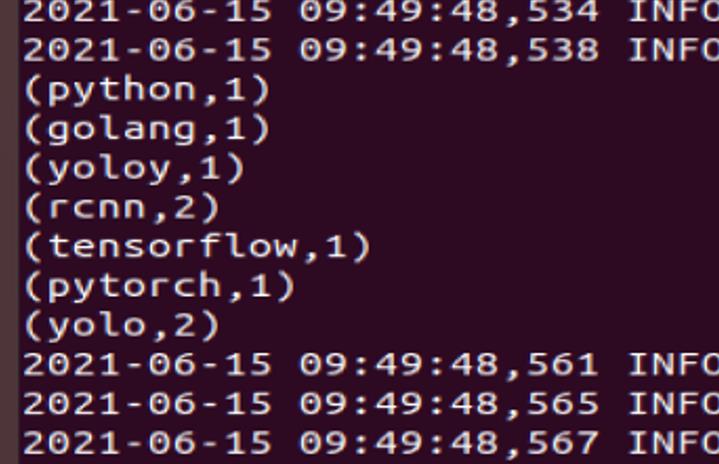
注:在运行SparkPi实例时会输出很多运行日志,可以通过加 grep 命令进行过滤,显示关心的信息:

5.2.2 spark shell中编写Scala代码实现:
(1)分别从本地文件、HDFS上的文件以及Spark Context的parallelized()方法生成分别生成RDD_1、RDD_2、RDD_3,要求本地文件格式为每行多个单词,以空格隔开;HDFS上的文本为每行1个单词,即单词以换行符隔开,每个RDD中都要包含1个或多个你的学号或者姓名拼音;
1.1 本地创建in.txt

写入内容

上传到spark

1.2 本地创建文件in0.txt

写入数据
上传到hdfs中

检查是否上传成功
 上传到spark
上传到spark

1.3 spark创建文件

创建成功!
(2) 输出RDD_1的第一行、RDD_2的所有内容、RDD_3的最大值;
2.1RDD_1的第一行

2.2 RDD_2的所有内容
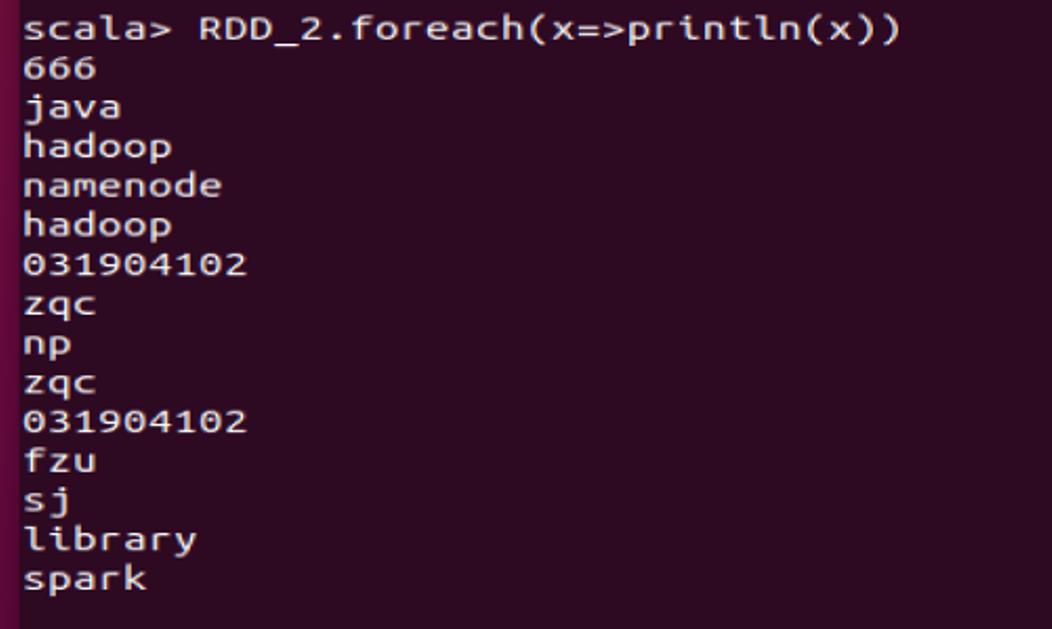
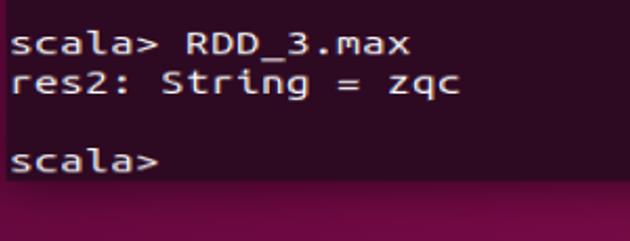
2.3 RDD_3的最大值
(3) 统计 RDD_1 中“姓名拼音”、“学号”两个单词出现的次数;



结果:
zqc 有6个
031904102 有 4个
(4) 对去重后的 RDD_1再去掉RDD_2中的内容;



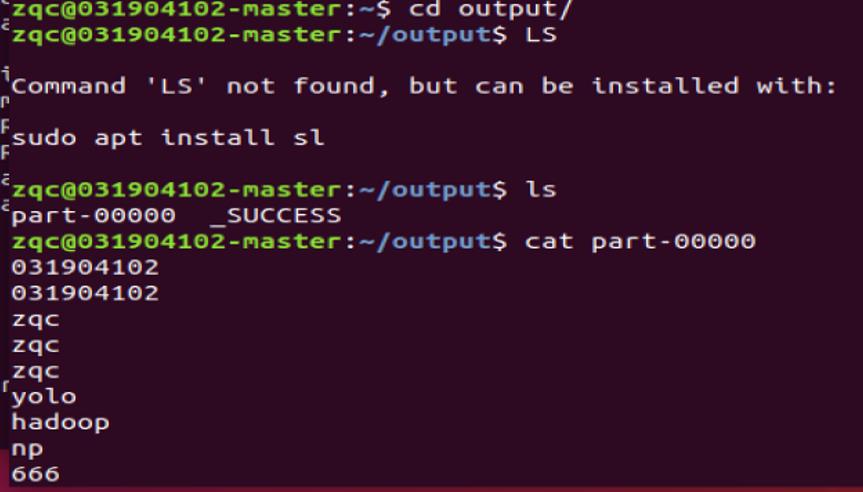
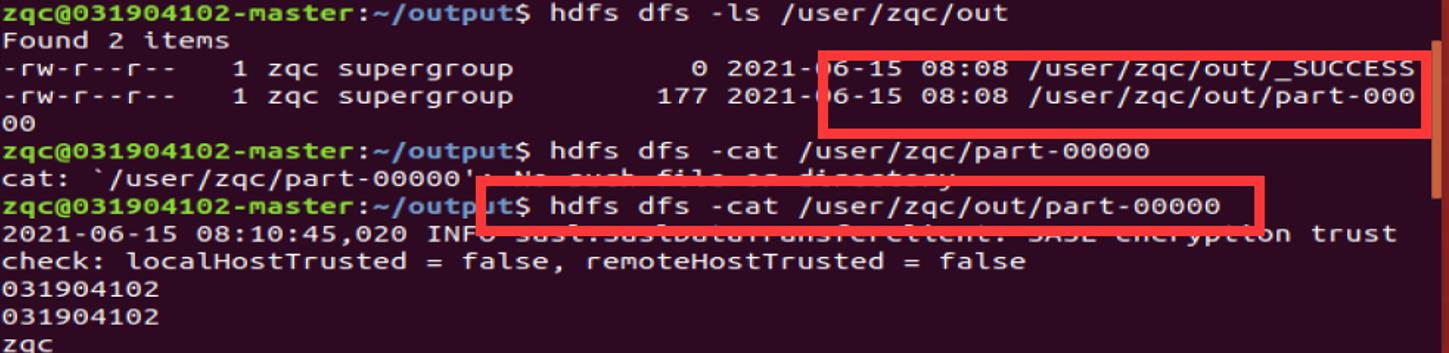
(5) 将上述结果与RDD_3合并,并将RDD_3分别写入本地文件系统和HDFS文件系统;


查看是否成功放入
(6)编写scala代码实现写入任意内容到HDFS中,文件路径自定义,文件以”学号-姓名拼音.txt”命名。
先创建一个文件

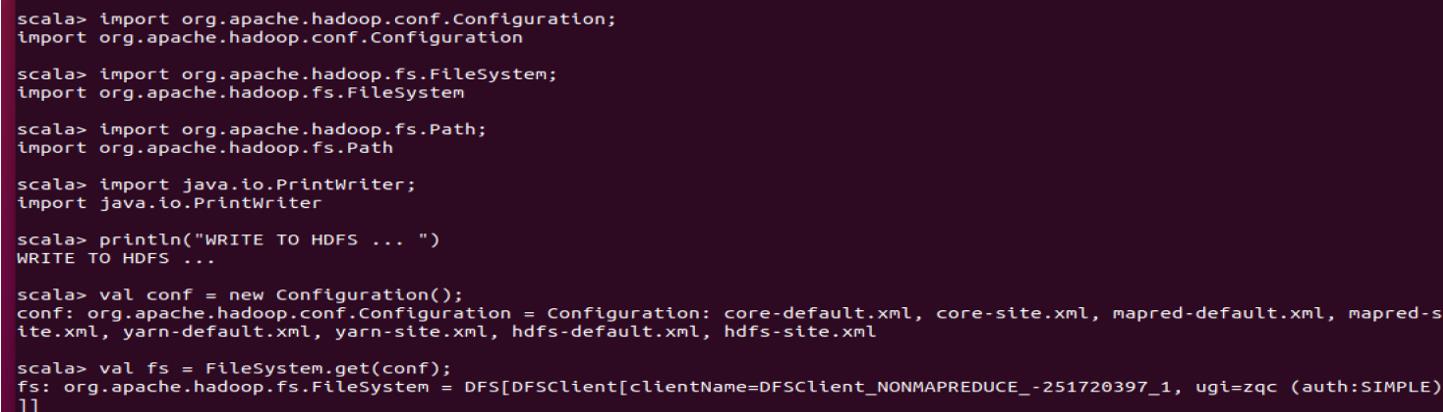

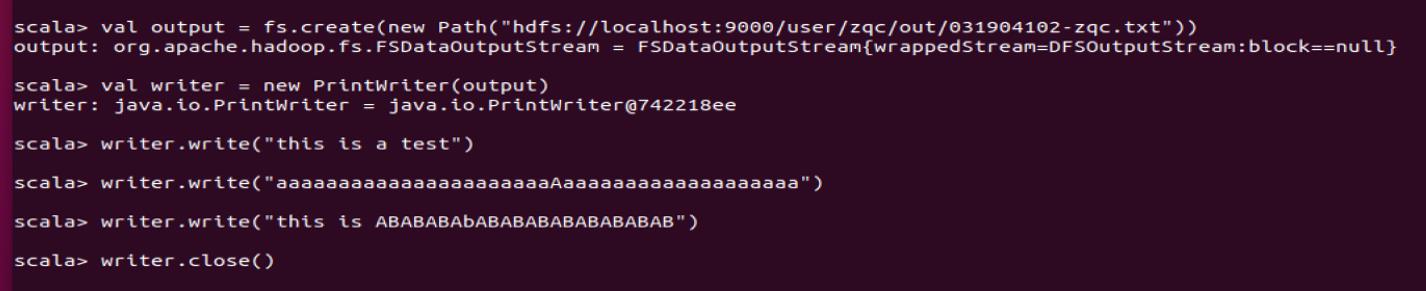
在HDFS上查看

5.2.3 编写Scala独立应用程序:
使用 Scala 语言编写的 Spark 程序,需要使用 sbt 进行编译打包。Spark 中没有自带sbt,需要单独安装。可以到 官网 下载 sbt 安装文件,最新版即可
下载好

创建一个目录

这里我们把 sbt 安装到“/usr/local/sbt”目录下,执行如下命令:

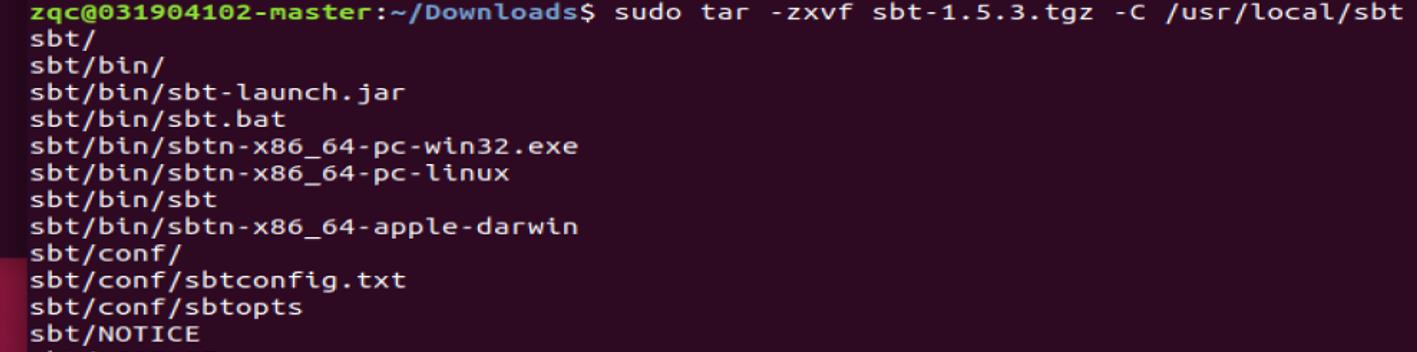
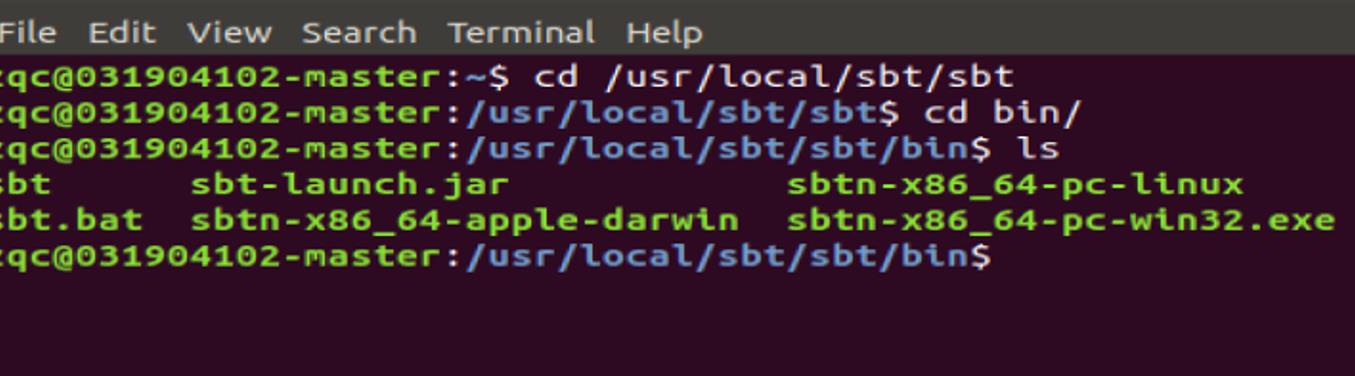
把 bin 目录下的 sbt-launch.jar 复制到 sbt 安装目录下


新建一个文件然后将下列内容写下去
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
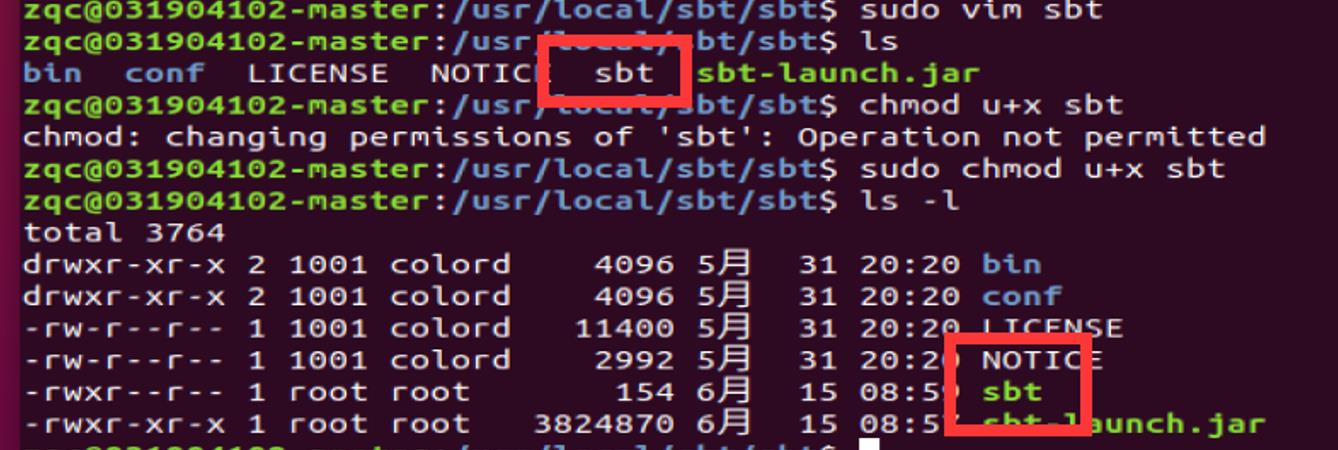
保存后,还需要为该 Shell 脚本文件增加可执行权限:
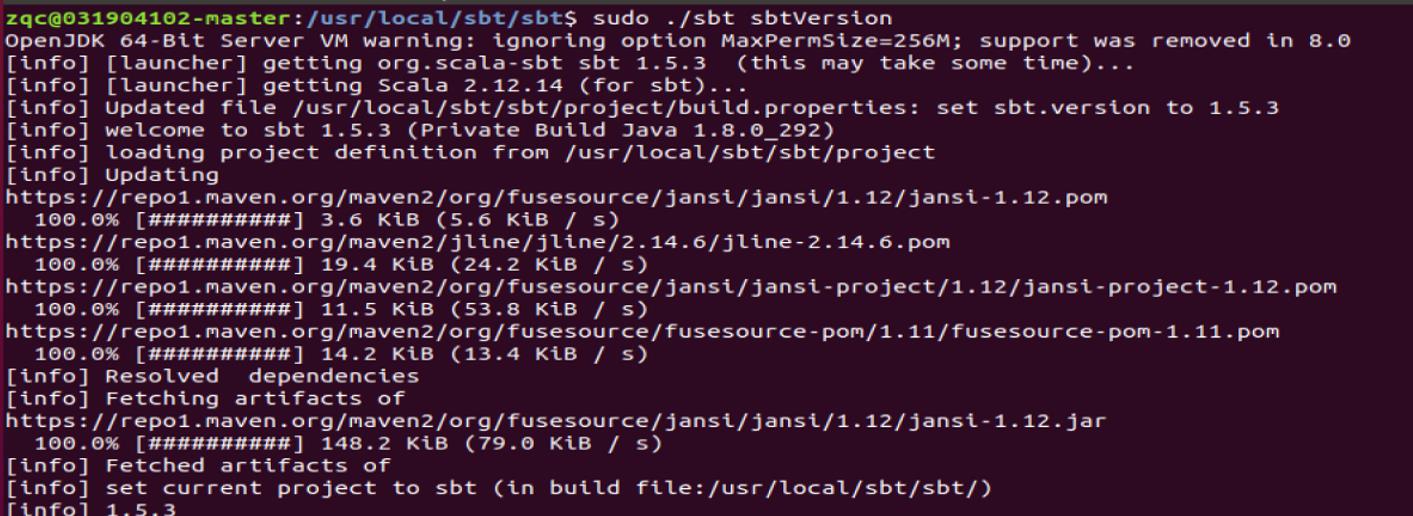
然后,可以使用命令 sbt sbtVersion 查看 sbt 版本信息:

完成了,是有一点点慢!
(1) 实现wordcount功能,并将结果写入本地文件;
在本地创建目录


创建这个文件。

写入数据。
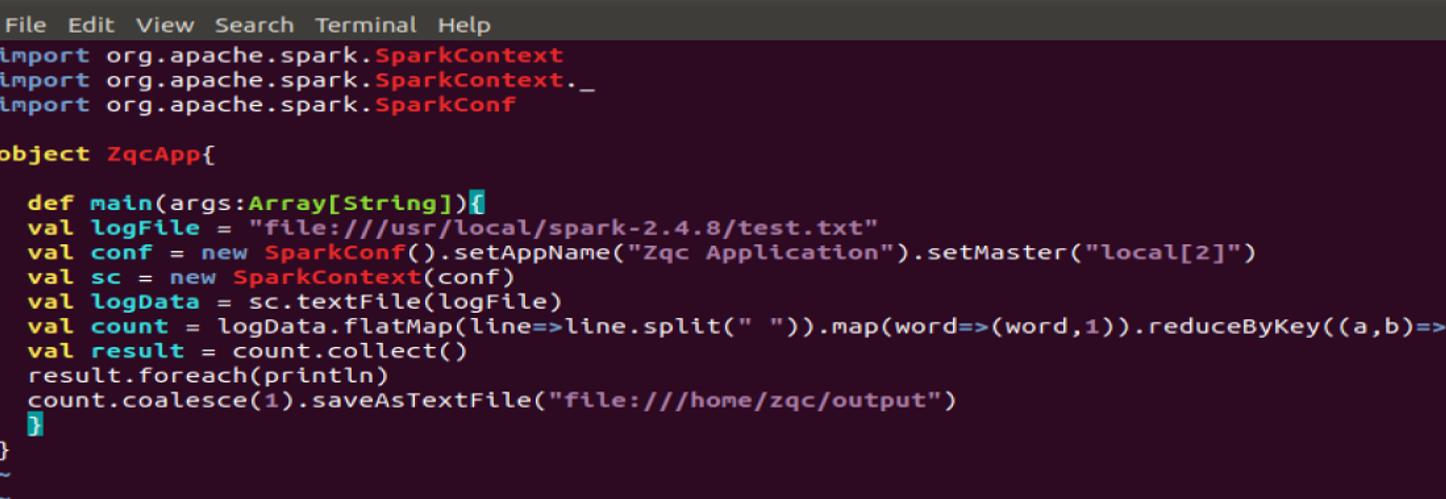
检查目录结构
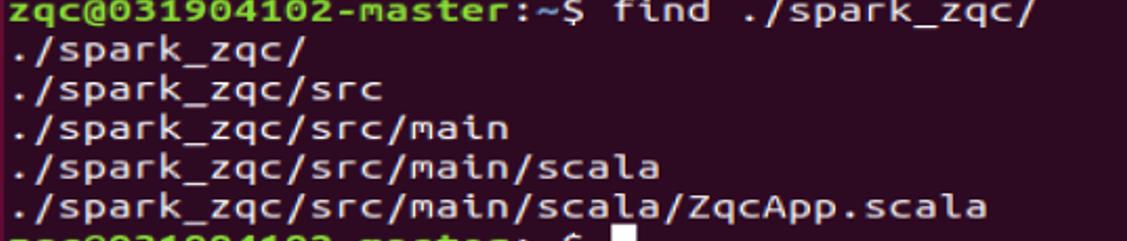


(2)分别使用sbt打包上述程序;



(3)通过spark-submit执行生成的jar。

- 编写Scala独立应用程序:
-
实现生成任意RDD,并将结果写入文件;
重命名并设置权限组

在终端中执行如下命令创建一个文件夹 spark_zqc_maven_scala 作为应用程序根,目录:

写入下面内容
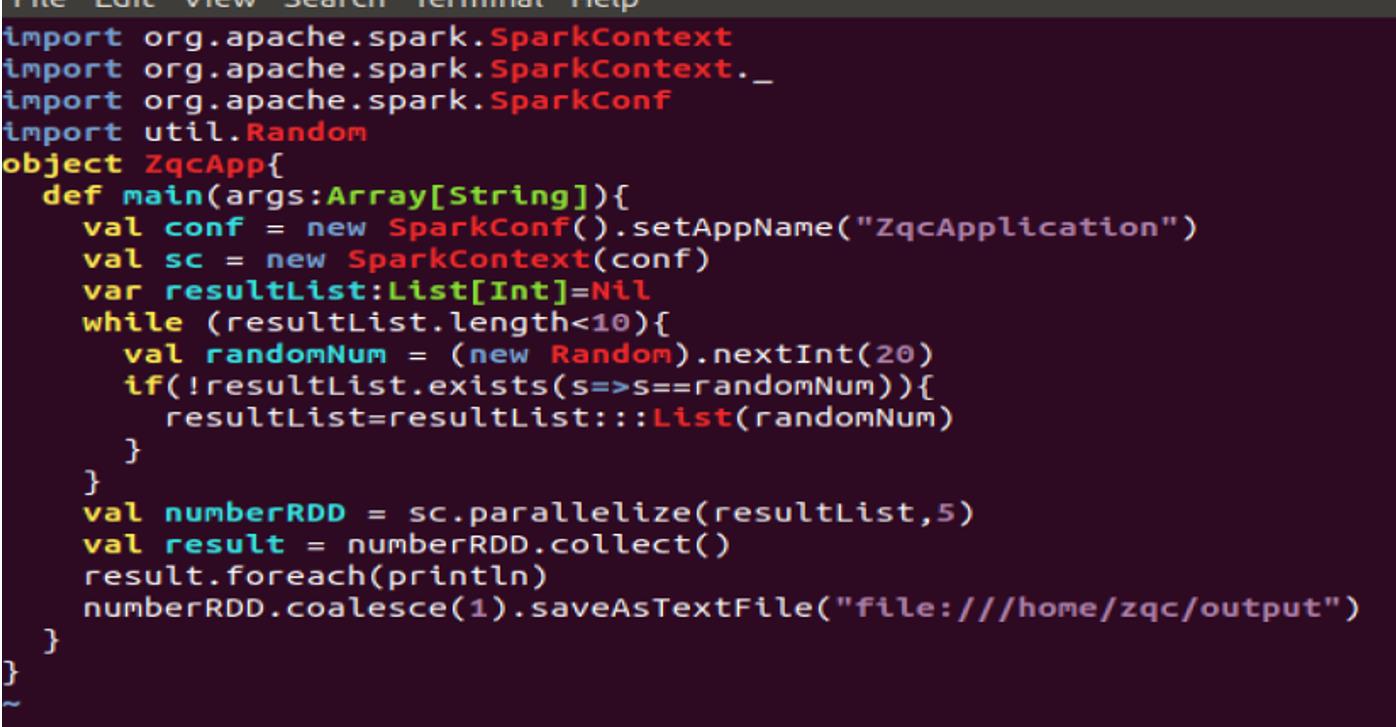
(2) 分别使用maven打包上述程序;
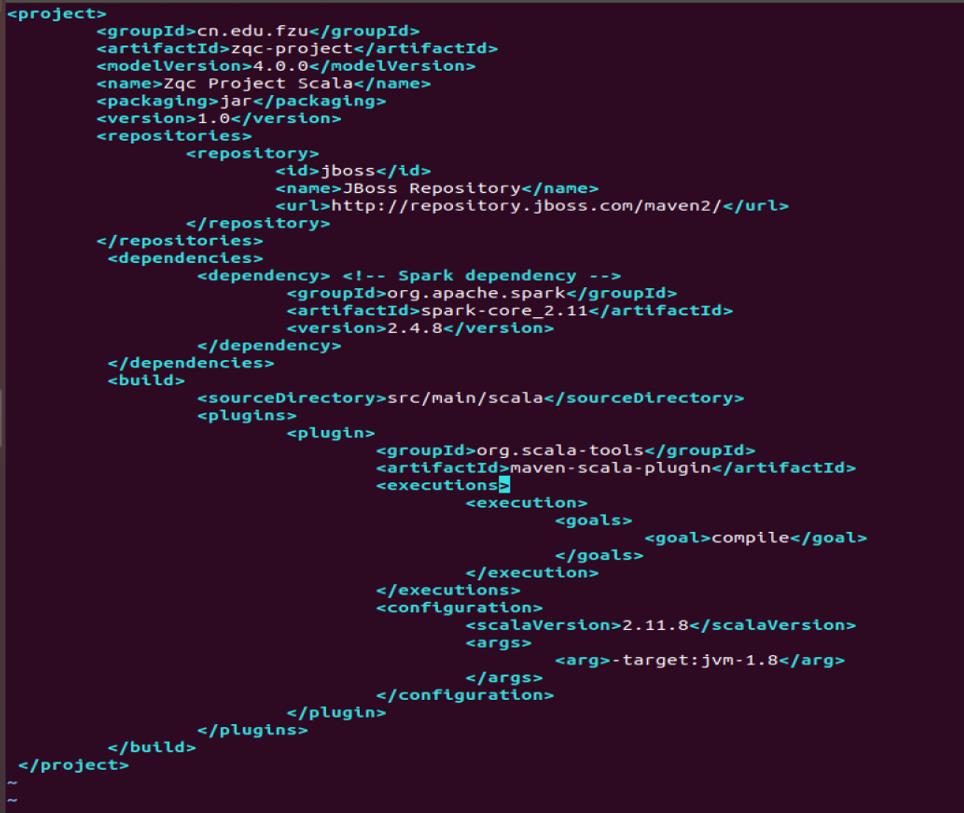
该 程 序 依 赖 Spark Java API, 因 此 我 们 需 要 通 过 Maven 进 行 编 译 打 包 。 在./spark_zqc_maven_scala 目录中新建文件 pom.xml,然后,在 pom.xml 文件中 添加如下内容,用来声明该独立应用程序的信息以及与 Spark 的依赖关系:
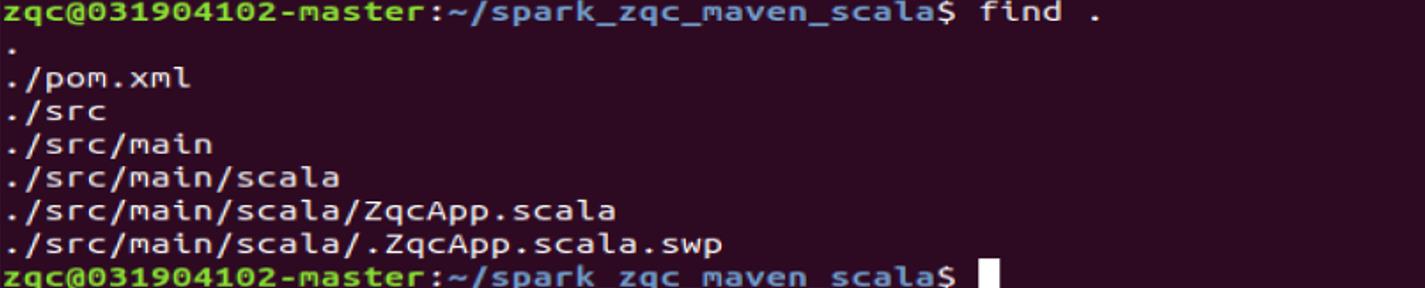
为了保证 Maven 能够正常运行,先执行如下命令检查整个应用程序的文件结构,
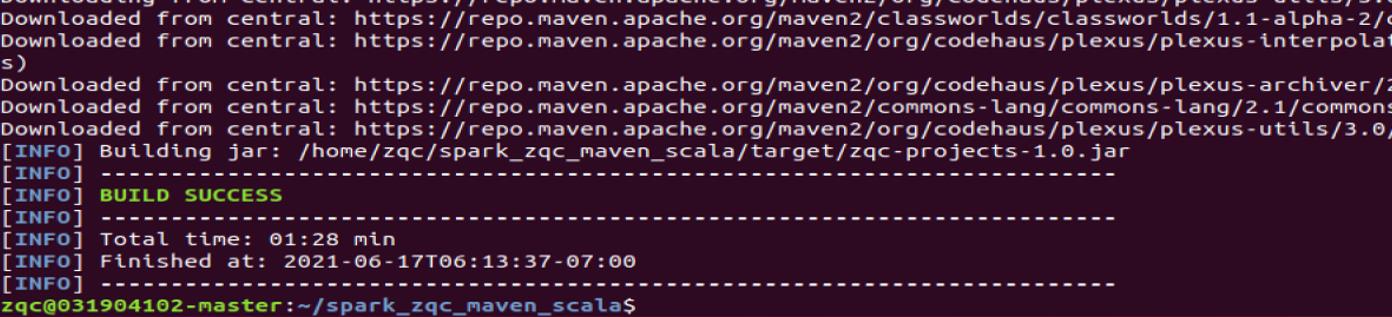
接下来,我们可以通过如下代码将整个应用程序打包成 JAR 包(注意:计算机需要保持连接网络的状态,而且首次运行打包命令时,Maven 会自动下载依赖包,需要消耗几分钟的时间):

(3) 通过spark-submit执行生成的jar。

最后
小生凡一,期待你的关注。

以上是关于想学大数据?一篇长文带你走进大数据 | Spark的基础知识与操作的主要内容,如果未能解决你的问题,请参考以下文章