长久以来,你不懂的字符编码和字符集,这里都有
Posted 石头StoneWang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了长久以来,你不懂的字符编码和字符集,这里都有相关的知识,希望对你有一定的参考价值。
(从OneNote复制过来格式有点变了,大体不影响阅读,这篇文章花了好几天搜资料,终于写完了,暂时没精力将格式调好看一点~)
常见的字符集或编码:
- ASCII
占一个字节。最高位固定是0,共有2^7=128种表示方法,事实上128种编码都被利用起来了,没有浪费,详细查看ASCII编码表
- GB2312
兼容ASCII,占用1-2个字节。除了所兼容的ASCII是1字节外,其余的都是2字节。收录了6763个汉字以及682个特殊符号。
- GBK(也叫cp936)
兼容GB2312,兼容ASCII,也是占用1-2字节(除了所兼容的ASCII是1字节外,其余的都是2字节)
(虽然收录数比GB2312多许多,但占用字节数没有增加,汉字依然是2字节,是怎么做到的? 当年GB2312没完全利用2字节而已,2字节可以做到最多65536个字符)。该编码汉字达到了20902个,另有984个汉语标点符号、部首等(含繁体字)。题外话,即使GBK也没有完全将2字节完全利用起来,所以后续的GB18030又是对GBK的一个扩展。
CP936其实就是GBK,IBM在发明Code Page的时候将GBK放在第936页,所以叫CP936。CP好像是 code page 的意思。
- Unicode
严格来说它并不是一种编码,就是相当于一个字典一样的字符集。而UTF-8/UTF-16/UTF-32都是利用了它作为字典,即利用了它的编码。
- 这个编码总是使用2字节,即使英文字母也是2字节,所以会浪费。
- 我们一般看到的以 \\u 开头就可以确定是Unicode。比如 "中" 字是 \\u4e2d,A 是 \\u0041。
- 其中 \\u 是固定的前缀,不写也行,后面是2个字节,一般会用十六进制表示。例如\\u4e2d,4e是一个字节,2d是另一个字节。
- \\u4e2d中\\u可以省略,也没有大小写区分,比如4e2d或者4E2D都行,反正都是16进制
- ASCII 的那套字符实际上只需要一个字节,但Unicode规定必须使用2字节,所以高位补零。所以你看到 \\u00xx,即00开头的即可确定该字符是ASCII字符。
- Unicode是字典,严格来说Unicode并不是一种编码方式,它只是规定了某个字符对应用什么数字表示
- Unicode的具体的编码实现,有UTF-8/16/32
- 其中UTF-16和UTF-32都有 BE 和 LE,即大头和小头的区分,详细见本文后面的描述
- Unicode的所有编码(UTF-8/16/32)都可以保存为有BOM或者无BOM,详细也看后续的描述
- 它跟经常看到的UCS,UCS-2,UCS-4 有什么区别,这个后续本文会讨论
- UTF-8
出现 UTF-8 的原因是 Unicode 不分青红皂白连英文字母都用2个字节,浪费磁盘和网络传输,所以出现了UTF-8。其实UTF-8并不是什么新鲜的编码方式,它是基于Unicode字符集做了实际的实现,UTF-8只是将Unicode的编码按照自己定义的框架填入(后续会详细聊到详细的实现方式)。
UTF-8 不兼容 GB2312 以及 GBK,兼容 ASCII,是变长的,使用1-4个字节表示。
其中英文字母、数字等ASCII定义的字符总是一个字节;西欧定义了除ASCII额外的字符是2个字节,比如法文的â是2个字节;中文总是三个字节(这是因为。
- 万国码:说的就是UTF-8,其别称
- 这种说法理解不到位:"Unicode是接口UTF-8是其实现类之一"。Unicode仅仅是被用作词典,即UTF-8利用了Unicode的编码
- Unicode就是平时在properties文件中的中文被转义为\\u开头的,这就是我们一般接触到的Unicode编码
- Unicode除了UTF-8外,还有UTF-16这种固定用2个字节的(这个就可以说是Unicode了)。还有UTF-32再补充一些
- UTF-8 with BOM,有些资料会表述为 UTF-8+
- UTF-16,这种编码平时接触得少,不过可能会在本地不在乎空间占用而在乎编码效率的话会使用到它。有分为大头和小头,后续会讨论到
- GB18030:这个比GBK字符集还要大,占用1-2字节,兼容GBK、GB2312、ASCII。当字符是ASCII定义的字符时占用1字节,其余的2字节。
- ISO-8859-1(Latin-1)
- 比ASCII范围要大,是西欧的字符。除了西欧,中欧的叫 ISO-8859-2,更多的 ISO-8859-x 系列可参考:https://zh.wikipedia.org/wiki/ISO/IEC_8859
- 占用1个字节,兼容ASCII。ASCII编码一个字节8位只用了7位,第一位固定是0,于是ISO-8859-x系列的编码就把闲置的第一位利用起来。ISO-8859-x系列,第一位都是1开头,即1xxxxxxx。
- 比如法语字母:â 等更多字母上面有类似声调的字母就是在8859系列里编进去的
- Latin-1:就是ISO-8859-1的别名。ISO-8859-2就是Latin-2,如此类推
- ANSI:
- 这个编码其实很简单,就是x编码,x具体表示什么,要看操作系统默认,也就是说ANSI不是具体的某个编码,它是一个变量。
- 在英文的操作系统里,ANSI表示ASCII,在简体中文里是GBK(也有一种说法是GB2312),在繁体中文里是BIG5
(上面提到的编码,其实GBK和GB2312有点不太好区分,因为GBK是兼容GB2312的,很难从十六进制的字节反过来推论是GBK还是GB2312,另外很多文本编辑器也很难诊断出是什么编码)
- 怎么知道ANSI具体表示什么编码? 不太清楚,貌似

-----------------------------------------------------------------------------------------------------------------------
关于UTF-8究竟用最多能用多少个字节?
最少1字节,最多4字节,这是一般的认识。不过也有文章谈到最多6字节,比如下面的:
(来自维基百科https://zh.wikipedia.org/wiki/UTF-8)

一般记住汉字一定是3字节,ASCII字母1字节,西欧其他奇怪的字母2字节。因为汉字是3字节的,所以对于GBK等2字节的编码方式还是有市场的,毕竟GBK/GB2312/GB18030等最多都只需要2字节。
-----------------------------------------------------------------------------------------------------------------------
关于UTF-8的汉字的范围:
19968(4e00)~40869(9fa5),这是查Unicode编码表,查其第一个以及最后一个汉字,得到的范围。这个范围,说明汉字妥妥的是排在3字节的范围内,这就是为什么说汉字的UTF-8编码都是3字节的。(3字节的并不是都是汉字!)
0xxxxxxx,范围下标是[0, 127] (7位可自定义,共128个)
110xxxxx 10xxxxx,范围是[128, 2175] (11位可自定义,共2048个)
1110xxxx 10xxxxxx 10xxxxxx,范围是[2176, 67711] (16位可自定义,共65536个)----可以看到汉字的范围都在这个里面
-----------------------------------------------------------------------------------------------------------------------
关于BOM

- BOM的作用是用来标记编码方式,好让浏览器打开的时候正确识别出是什么编码
- 对于UTF-8/16/32,谈有无BOM才有意义
- 有BOM的会比没BOM的文件要大
比如UTF-8/16/32 with BOM的分别比无BOM的大3、2、4个字节。(UTF-16和32存在BE和FE,对BOM的字节大小没有影响,只是印象BOM字节的顺序)
- UTF-8的BOM是 EF BB BF,这3个字节组成一块,其实是空格。
EF BB BF 分别是 11101111 10111011 10111111,标出模板部分11101111 10111011 10111111,得到11111110 11111111,十六进制是FE FF,十进制是65279,这个就是一个空格
- 对于非Unicode的编码,BOM无意义(详细如图文字)
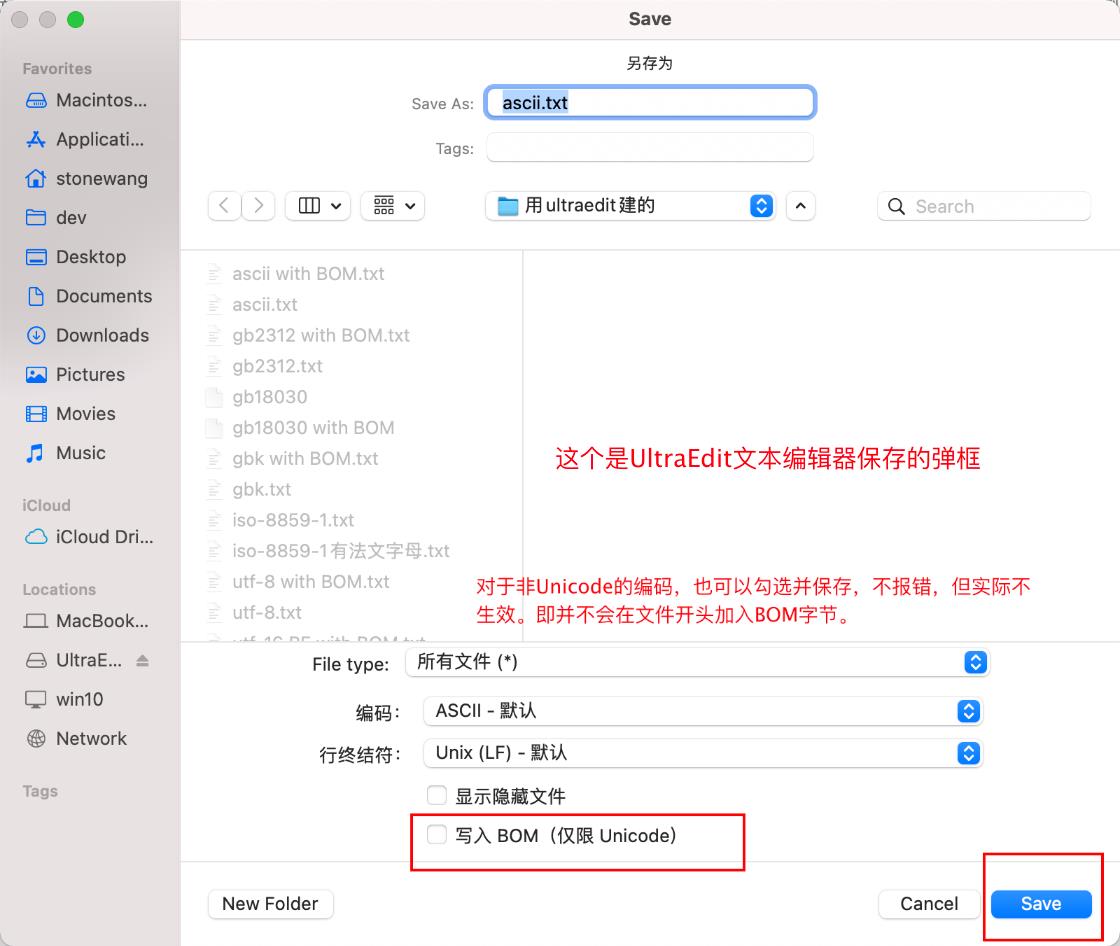
-----------------------------------------------------------------------------------------------------------------------
关于BE和LE(大头和小头)
BE 就是 "大头",即 big endian
LE 就是 "小头",即 small endian
大头和小头区别就是字节的顺序的问题。详细可自行查相关资料。目前似乎就只有UTF-16和UTF-32有大小头问题。
-----------------------------------------------------------------------------------------------------------------------
联通现象
联通现象就是新建文本文件,然后用记事本打开,输入 "联通" 后保存(或者打开记事本,输入 "联通" 后保存到某个路径),然后重新打开就会出现乱码,但是入错此时重新输入 "联通" 二字重新保存就不会有错了。(有时候会模拟不出这种情况,是因为保存的时候没有用ANSI保存,而是用UTF-8保存了)
出现这种问题,是因为 "联通" 二字的,在使用ANSI的时候,甭管在简体Windows系统里ANSI是指什么,GB2312? GBK? 还是GB18030,这都不重要,这3者编码都是一样的,编码为:C1 AA CD A8,在变成二进制的时候为:
| C1 | 11000001 |
| AA | 10101010 |
| CD | 11001101 |
| A8 | 10101000 |
问题就在于重新打开的时候,上面的编码被误以为是UTF-8的2字节的编码了,因为UTF-8的2字节编码的模板就是 110xxxxx 10xxxxxx,所以就出现了乱码,当重新保存 "联通" 两个字的时候,是以UTF-8的编码进行保存了,所以重新打开就不乱码了。(重新保存后编码变成了无bom的UTF-8,即E8 81 94 E9 80 9A)
实际上,除了 "联通" 二字,就是 "联" 这个字,还有很多的其他字,总之只要造成误解的就会出现乱码。
注意:上面的演示不是那么容易演示出来。我的是win10系统,可能不知道设置了什么,新建文本文件默认是UTF-8编码而不是ANSI了,我需要先打开notepad,写上内容再保存为ANSI,然后再次用NPP打开才会出现乱码(用notepad打开还是很顺利识别了ANSI,这可能是微软修复了,总之非常不好模拟)
-----------------------------------------------------------------------------------------------------------------------
关于如何用正则表达式判断汉字
[\\u4E00-\\u9FA5]

-----------------------------------------------------------------------------------------------------------------------
关于Unicode、UCS、UCS-2、UCS-4区别等
因为精力有限,我这里只列出大概的区别,详细的可以参考百科。
大概就是Unicode是一个组织搞出来的,UCS是另外一个组织搞出来的,后来统一了、互相合作了。所以怎么说,可以说的是差不多的东西。
UCS-2表示2个字节,UCS-4表示4个字节。现在UCS中的CS是character set的意思,就是字符集,所以UCS就是字符集的意思。其实Unicode也是字符集的意思,相当于词典一样一个字符对应一个数字(而UTF-8/16/32等才是具体的编码实现,从Unicode "字典" 中查出这个数字往自己的编码框架中填入值,比如UTF-8的2自己的 "框架" 就是110xxxxx 10xxxxxx)。
不细纠结的话,理解为差不多相同的东西就好了。
-----------------------------------------------------------------------------------------------------------------------
关于字符集和字符编码的区别

- 其实字符集和字符编码是不同的的东西,但是有时候会混着用。比如我们说GBK,既表示GBK字符集,也表示GBK的编码方式。
- 通常一种字符集就对应着一种编码方式,这也就是为什么通常字符集和字符编码方式容易混为一谈的原因
- 但是有个例外,UTF-8并不是字符集,而是编码方式,无论UTF-8、UTF-16、UTF-32,都是Unicode字符集。(原因就是字符用什么数字表示,这都是Unicode字符集描述清楚了的。只是编码的方式由UTF-8等方式决定,比如UTF-8的编码方式,仅仅是将Unicode的字符集中的某个字对应的数字换算成二进制之后填入到UTF-8的模板中,仅此而已)
-----------------------------------------------------------------------------------------------------------------------
关于UTF-8怎么实现Unicode
- 1个字节:用0开头,即0xxxxxxx (8位,0开头,后面7个x,可以表示2^7=128个字符,如上图所示)
- 2个字节:用110开头,第二个字节用10开头,即110xxxxx 10xxxxxx (即第一个字节剩下5个x可用,第二个字节剩下6个x可用,总共11个x可用)
- 3个字节:用1110开头,余下2个字节都用10开头,即1110xxxx 10xxxxxx 10xxxxxx (第一个字节剩下4个x可用,第二三个字节各剩下6个x可用,总共16个x可用)
- 4个字节:用11110开头,余下3个字节都用10开头,即11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (的第一个字节剩下3个x可用,剩下的字节各剩下6个x可用,总共21个x可用)
就用靠着上面的方式,字节流向水流一样不间断,要怎么区分这个字节是独立的还是一部分? 就是靠上面的办法进行判断的。比如0开头,就判定为可独立表示一个字符,如果读到110开头,则必须再读一个(同时如果读到10开头则肯定是不能独立的字符,这里我觉得为什么既然都设计了110开头了为啥后续的字节还要规定用10开头? 可能是为了纠错吧,即读到10开头就可以往前追溯尝试查找110或者1110或者11110的字节从而定边界)
请练习:中国的 "中" 字,是怎么用UTF-8标示的?
首先我们查 "中" 子的Unicode编码,这里为啥是查Unicode编码而不是查UTF-8编码呢? 大概是Unicode规定了某个字符用什么数字表示,而UTF-8具体将这个数字表示为特定的二进制。注意并不是直接将该数字转化为二进制,是需要做一些处理的。处理方式就是上面提到的如果用0开头、110、1110、11110、10开头来表示。
如何查Unicode编码呢? Chrome浏览器安装 FeHelper插件,再安装插件中的小功能模块 "信息编码解码工具",如图可查看
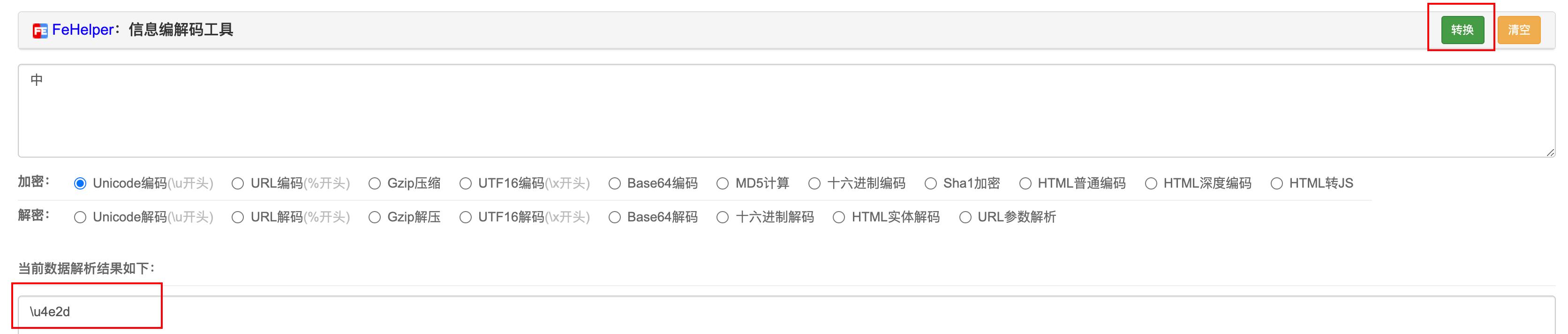
由图中国可以看到 "中" 字的Unicode是 \\u4e2d,其中\\u 是固定的前缀,其实就是用数字 4e2d 来表示 "中" 字。4e2d 是十六进制,用程序员计算器或者继续用上面的工具安装 "进制转换工具" 将其转为二进制:
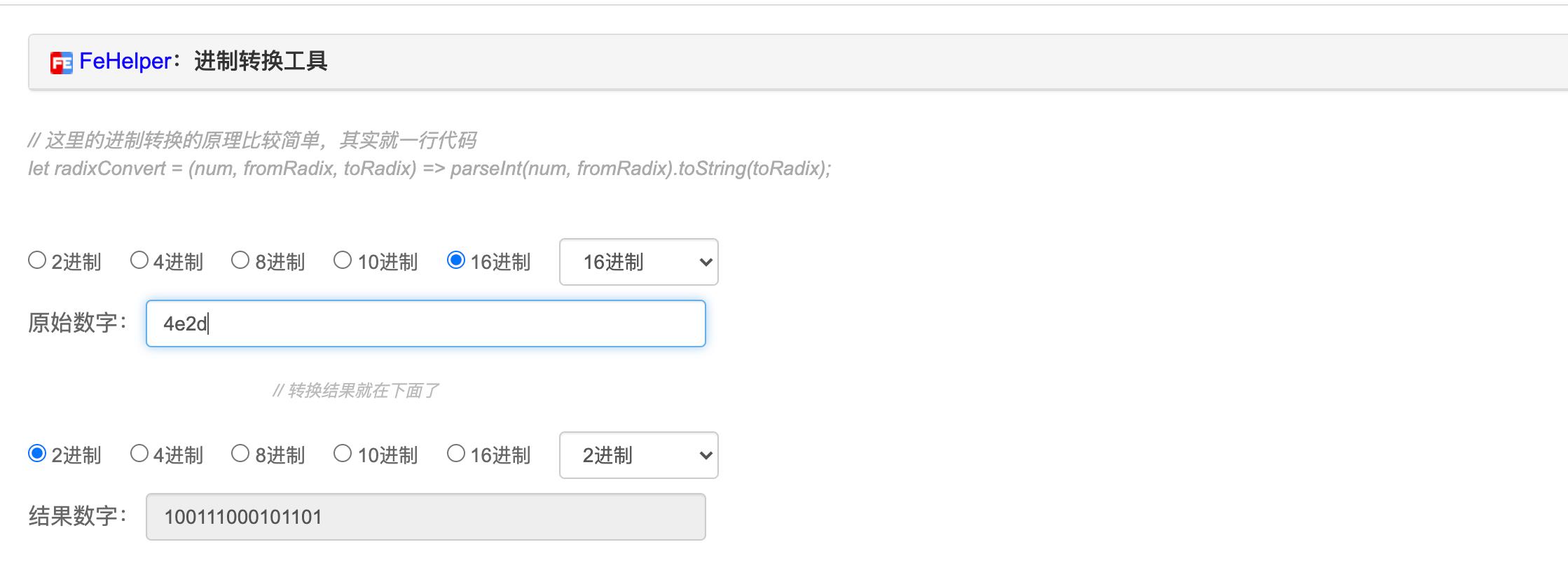
要注意上述二进制的结果不满2字节,高位补0,凑成2字节(16位)
100111000101101,共15位,高位补0,为 0100111000101101
将上述的二进制填入下面的模板中,即有多少个x就替换
1110xxxx 10xxxxxx 10xxxxxx
成为:
11100100 10111000 10101101
这个就是 "中" 字用二进制表示的方法,虽然Unicode中这个字占用了15位连2字节都不到,但是因为UTF-8中需要一些功能占位(即固定的开始位),所以整个是占用了3字节。
在UTF-8编码中,中文总是占用3个字节的,因为查了Unicode的汉字的范围,从开始到结束都必须套用占3个字节的模板(1110xxxx 10xxxxxx 10xxxxxx)。
最终表示为 11100100 10111000 10101101,所以你会在打印byte[]的时候会打印出 [-28, -72, -83]
附:负数如何转为十进制? (你怎么知道上述数字是负数? 因为最高位是1表示负数,0就是正数,貌似是这样子)
11100100 先取反,00011011,加1,00011100(就是10进制的28),最后结果记得加上负号,即-28
10111000 先取反,01000111,加1,01001000(即10进制的72),最终结果-72
10101101 先取反,01010010,加1,01010011(即10进制的83),最终-83
补充第二点:关于字符的范围
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
| 0000 0000~0000 007F | 0xxxxxxx |
| 0000 0080~0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800~0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000~0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
-----------------------------------------------------------------------------------------------------------------------
附录:ASCII 编码表
一个字节8位,用了7位,能表示2^6=128个字符,如下图所示从0~127一共128个字符,看来设计这套字符的人员已经将其用满用尽了。
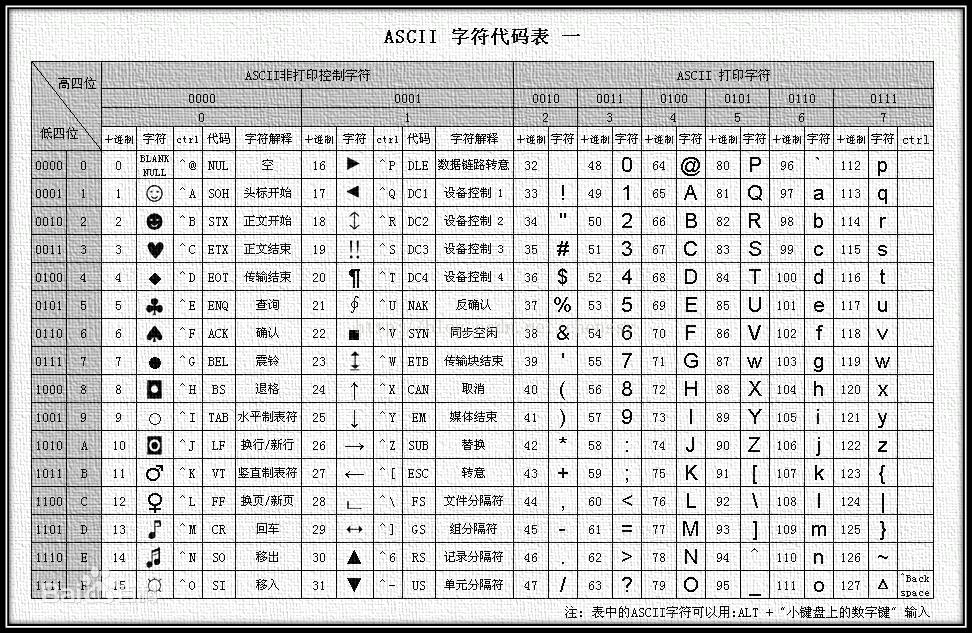
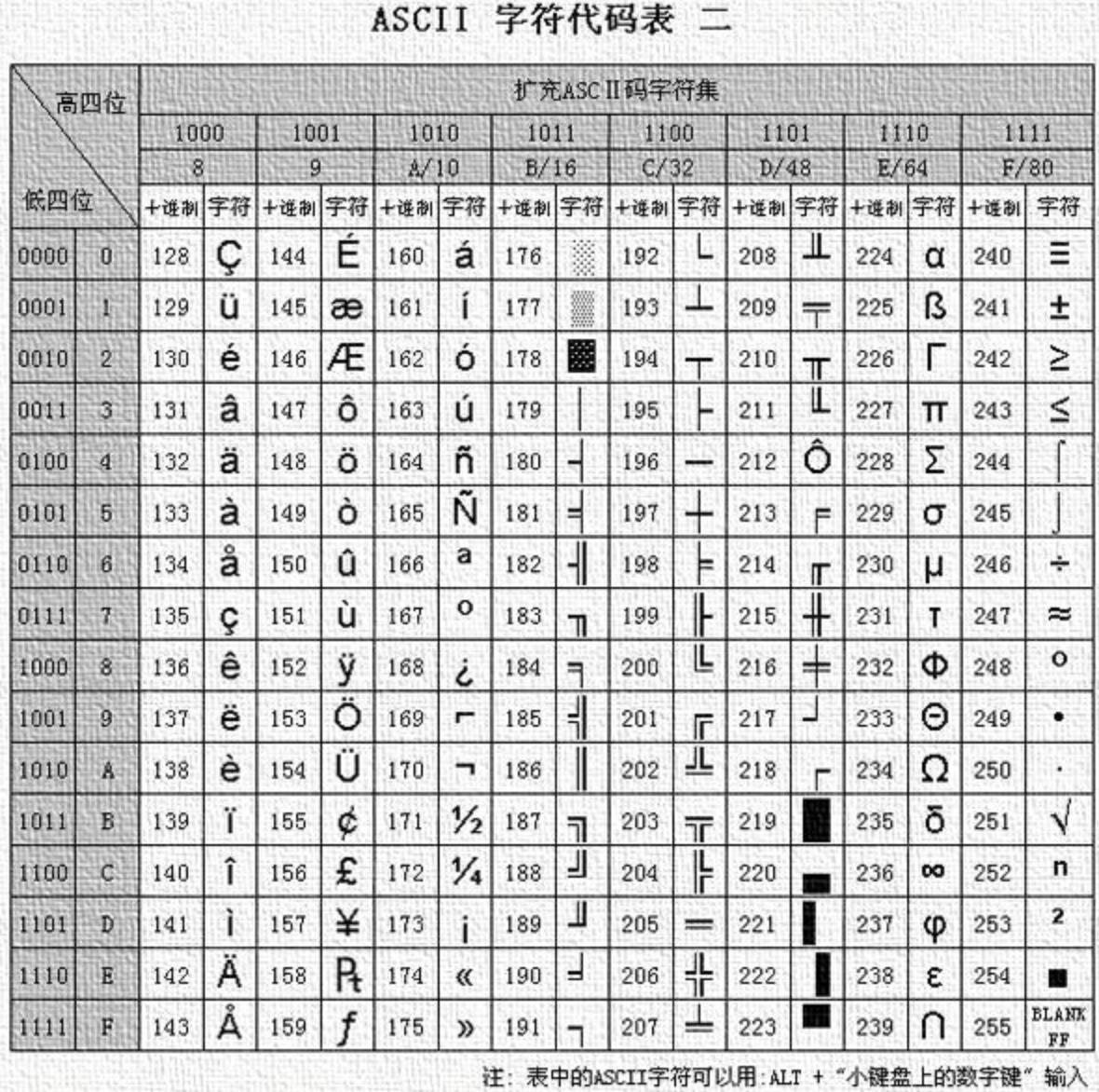
附录:扩展的 ASCII 编码表
-----------------------------------------------------------------------------------------------------------------------
以上是关于长久以来,你不懂的字符编码和字符集,这里都有的主要内容,如果未能解决你的问题,请参考以下文章