python爬虫入门
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫入门相关的知识,希望对你有一定的参考价值。
python爬虫入门(3)
Beautiful Soup 库入门
文章目录
1.安装及测试
安装
在cmd命令行中输入pip install beautifulsoup4,即可安装
测验
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")#获取网页源代码
demo = r.text
soup = BeautifulSoup(demo, "html.parser")#解析demo的解释器,解析得到一个变量
print(soup.prettify())
运行结果如下:
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
基本用法from bs4 import BeautifulSoup #bs4是beautifulsoup4 BeautifulSoup是一个类 soup = BeautifulSoup('<p>data</p>','html.parser') #'<p>data</p>'是需要解析的html信息, 'html.parser'是解析器
2.BeautifulSoup库基本元素
①html标签
html有各种标签,可以看作"标签树"
标签基本结构如下: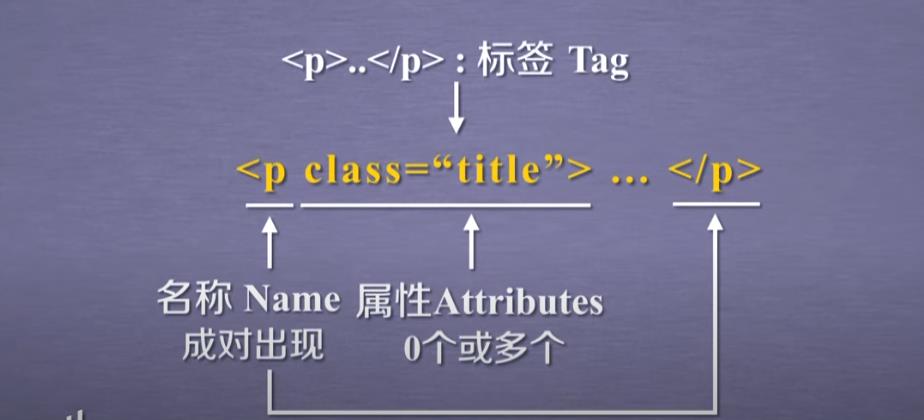
属性由键值对构成
而Beautiful Soup库正是
解析、遍历、维护"标签树"的功能库 如HTML,XML
②库的引用
Beautiful Soup库,也叫beautifulsoup4或bs4
引用方式
from bs4 import BeautifulSoup
#or
import bs4
③Beautiful Soup类
可认为下面三者等价


Beautiful Soup库解析器

Beautiful Soup类的基本元素

获取Tag
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
#print(r.text)
demo = r.text
soup = BeautifulSoup(demo, "html.parser")#解析demo的解释器
# print(soup.prettify())
print(soup.title)
tag = soup.a
print(tag)
运行结果
<title>This is a python demo page</title>
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
html中a标签
标签定义超链接,用于从一张页面链接到另一张页面。
元素最重要的属性是 href 属性,它指示链接的目标。
获取Name
获取标签名字
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo , "html.parser")
print(soup.a.name)
print(soup.a.parent.name)
print(soup.a.parent.parent.name)
运行结果
a
p
body
获取Attributes
获取标签属性
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo , "html.parser")
tag = soup.a
print(tag.attrs)#标签属性.attrs
print(type(tag.attrs))#标签属性的类型 (字典类型)
print(tag.attrs['class'])#是字典,可以提取每一个属性的值
print(tag.attrs['href'])
print(type(tag))#标签的类型
运行结果
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
<class 'dict'>
['py1']
http://www.icourse163.org/course/BIT-268001
<class 'bs4.element.Tag'>
tag是bs4.element.Tag类型,是bs4给标签定义的一种特殊类型
获取NavigableString
navigablestring元素
字符串类型,尖括号标签之间的字符串,可跨越多个标签层次
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup= BeautifulSoup(demo,"html.parser")
tag=soup.a
print(soup.a)
print(soup.a.string)
print(soup.p)
print(soup.p.string)
print(type(soup.p.string))
运行结果
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
Basic Python
<p class="title"><b>The demo python introduces several python courses.</b></p>
The demo python introduces several python courses.
<class 'bs4.element.NavigableString'>
Navigablestring也是bs4定义的类型
获取Comment
Comment类型
from bs4 import BeautifulSoup
soup2 = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>","html.parser")
print(soup2.b.string)
print(type(soup2.b.string))
print(soup2.p.string)
print(type(soup2.p.string))
运行结果
This is a comment
<class 'bs4.element.Comment'>
This is not a comment
<class 'bs4.element.NavigableString'>
虽然是注释,但并没有标明是注释,(还是会提取注释)所以依据类型来判断比较好(bs4.element.Comment)
如果不希望提取注释,就要对类型进行相关判断
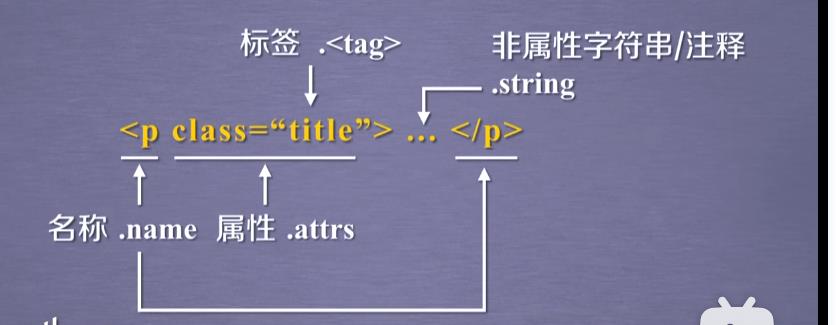
3.基于bs4库的HTML格式输出
之前没有用bs4之前,爬下来的html都乱成一团,没有标签树的层次感,
而bs4可以让其更好地显示
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo = r.text
soup = BeautifulSoup(demo, "html.parser")#解析demo的解释器
print(soup.prettify())
运行结果
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
prettify()可以给html的标签和文本增加换行符
还可以对标签进行处理
print(soup.a.prettify())
运行结果
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
bs4库将读入的html等都转化为了
utf-8编码
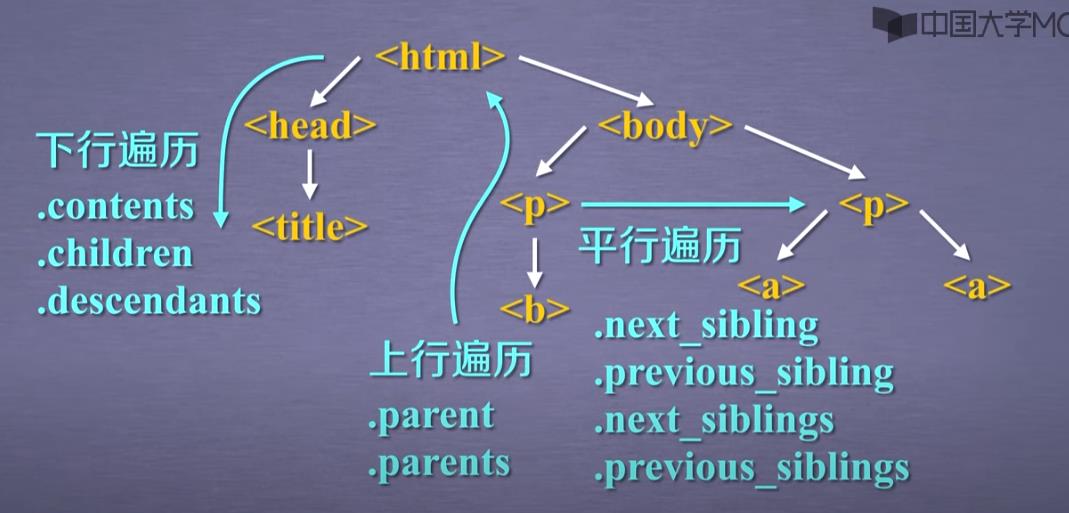
4.基于bs4库的HTML内容遍历方法
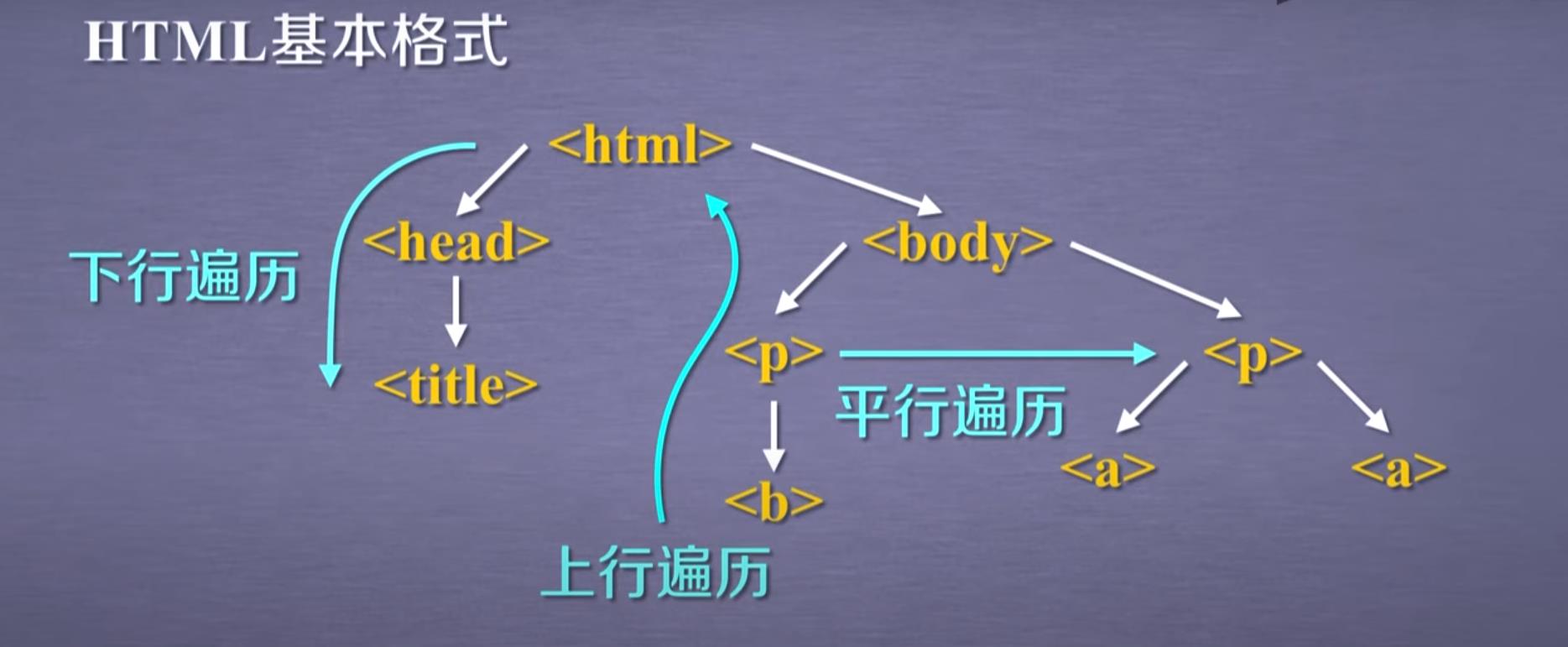
树形结构
①下行遍历

.contents
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo =r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.head)
print(soup.head.contents)
print(soup.body.contents)#节点不仅包括tag,还包括字符串等
print(soup.body.contents)#body的儿子节点的数量
print(soup.body.contents[1])#利用列表下标
运行结果
<head><title>This is a python demo page</title></head>
[<title>This is a python demo page</title>]
['\\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\\n']
['\\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\\n']
<p class="title"><b>The demo python introduces several python courses.</b></p>
.children
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo =r.text
soup = BeautifulSoup(demo,"html.parser")
for child in soup.body.children:
print(child)
运行结果
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
②上行遍历

import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo =r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.title.parent)
print(soup.html.parent)#html是最高级别的,其parent就是自己
print(soup.parent)#是空的,无parent
运行结果
<head><title>This is a python demo page</title></head>
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
None
遍历一个标签的所有先辈标签
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo =r.text
soup = BeautifulSoup(demo,"html.parser")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
运行结果
p
body
html
[document]
③平行遍历

其中后两个是迭代类型,只能用在for in 中
平行遍历的条件:必须发生在同一个父节点下的各节点间
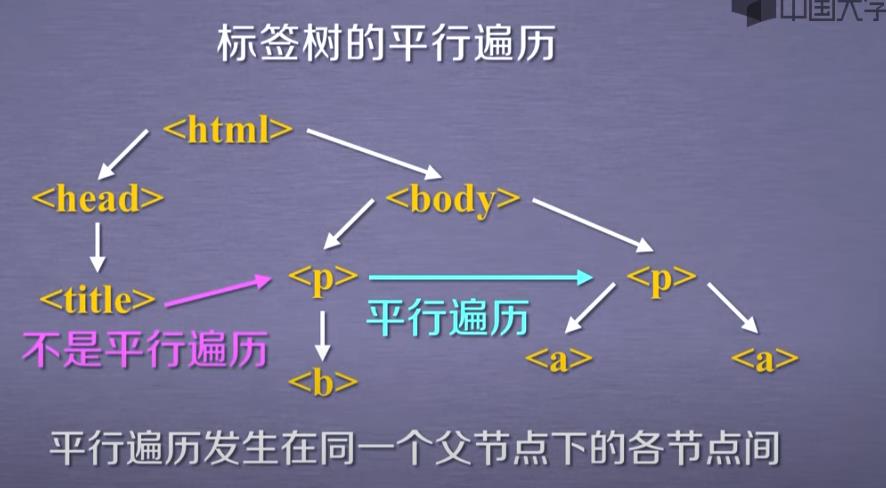
标签树的navigablestring也构成了标签树的节点
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo =r.text
soup = BeautifulSoup(demo,"html.parser")
print(soup.a.next_sibling)#标签树的navigablestring也构成了标签树的节点
print(soup.a.next_sibling.next_sibling)
print(soup.a.previous_sibling)
print(soup.a.previous_sibling.previous_sibling)#空信息
运行结果
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
None
用循环来遍历
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
demo =r.text
soup = BeautifulSoup(demo,"html.parser")
for sibling in soup.a.next_siblings:
print(sibling)
运行结果
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
.
回顾

5.遇到的问题
①回顾上次
Ⅰ
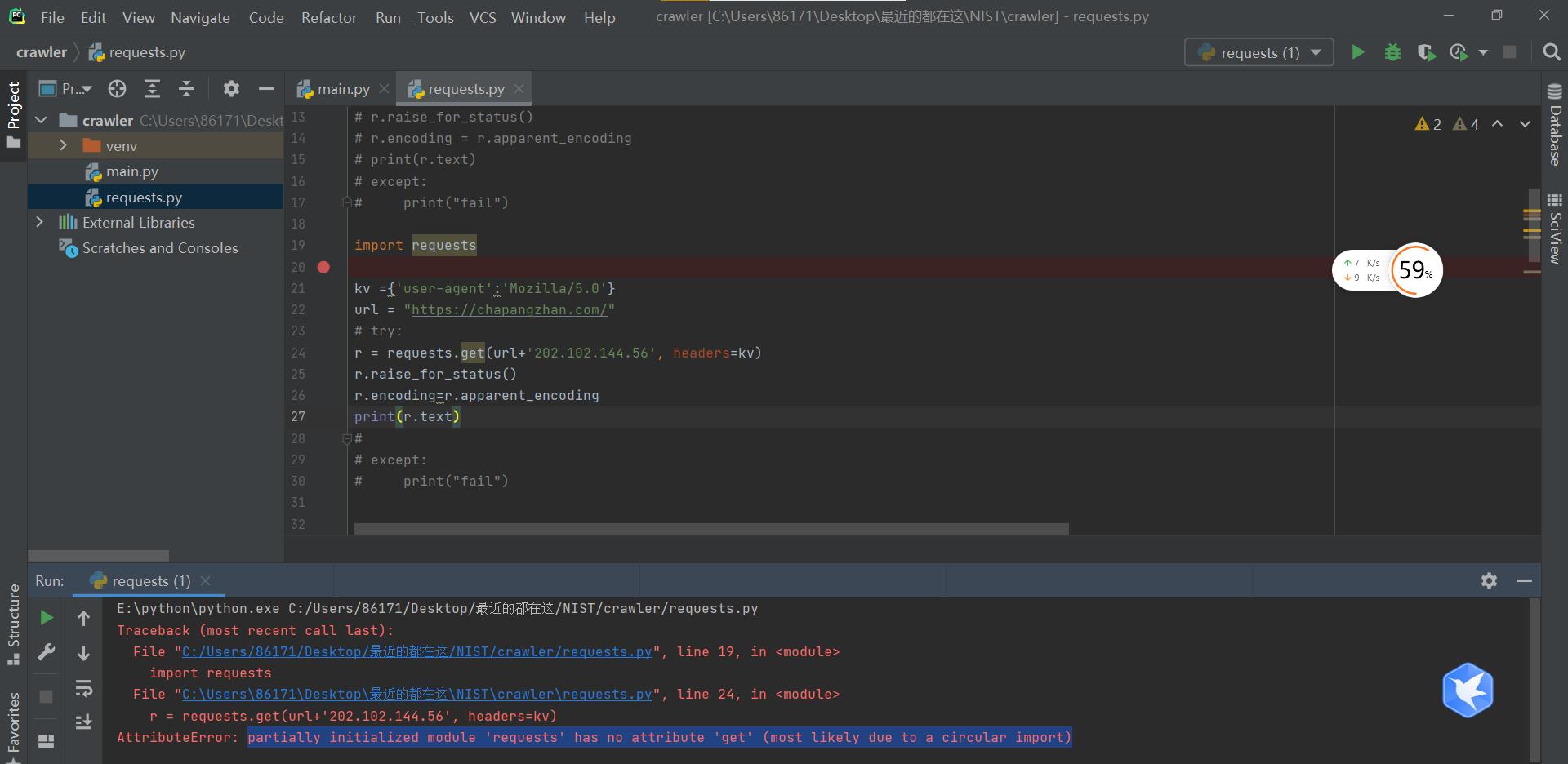
上一篇文章里爬取IP的代码居然失效了🤔❓❓❓
把try 和 except去掉,搜了一下报错,看到了这篇文章,解决了
原来是因为我把文件名重命名为了
requests.py
Ⅱ
而奇怪的事情又发生了🤔,我重新改成 以上是关于python爬虫入门的主要内容,如果未能解决你的问题,请参考以下文章requests_learnin