自用Deep Memory Network 深度记忆网络笔记
Posted 王六六的IT日常
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自用Deep Memory Network 深度记忆网络笔记相关的知识,希望对你有一定的参考价值。
参考:从流域到海域-博客-Deep Memory Network 深度记忆网络
论文阅读-Memory Network
论文解读:记忆网络(Memory Network)
- RNN解决长期依赖的能力随着文本长度的增加越来越差,attention机制是解决这种问题的一种思路。
- 现在再来看另外一种思路—深度记忆网络:Deep Memory Network在Aspect based Sentiment等NLP领域都有过成功的实践,但其提出者本身是以通用模型的形式提出的。
Introduce of Memory Network
Memory Network是一种新的可学习模型,它使用一个整合了长期记忆的一个组件(称为Memory)作为推断组件(inference components)来进行推理。长期记忆Memory可以被读和写,以实现预测的最终目的。
原论文作者认为RNN的记忆问题(无法完成简单的复制任务,即将输入原样输出)也可以被Memory Network解决。它核心思想来自机器学习文献中成功应用的使用外置的可读写的记忆模块来进行推断。
Memory Networks
这是Facebook AI在2015年提出来的:MEMORY NETWORKS。论文是第一次提出记忆网络,利用记忆组件保存场景信息,以实现长期记忆的功能。对于很多神经网络模型,RNN,lstm和其变种gru使用了一定的记忆机制,在Memory Networks的作者看来,这些记忆都太小了。
一个记忆网络(memory networks),包括了记忆
m
m
m,还包括以下4个组件
I
I
I,
G
G
G,
O
O
O,
R
R
R(lstm的三个门,然后m像cell的list):
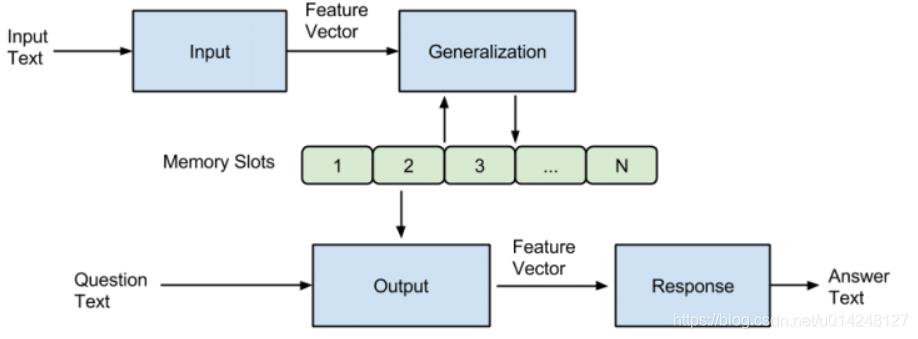
一个记忆网络是由一个记忆 m m m(一个以 m i m_i mi作为索引的数组对象)和4个组件 I I I, G G G, O O O, R R R组成。其中:
- I I I :(input feature map) - 将输入转化为中间特征表示。不同的应用有不同的方法。例如NLP中的词向量化等。(可以利用标准预处理,例如,文本输入的解析,共参考和实体解析。 还可以将输入编码为内部特征表示,例如,从文本转换为稀疏或密集特征向量)
-
G
G
G :(Generalization) - 负责根据输入更新memory单元。原作者称之为泛化,因为网络在该阶段有机会将记忆压缩和泛化以供后面使用。在作者的具体实现里,只是简单地插入记忆数组里。作者考虑了几种新的情况,虽然没有实现,包括了记忆的忘记,记忆的重新组织。(最简单的
G
G
G形式是将
I
(
x
)
I(x)
I(x)存储在存储器中的“slot”中)
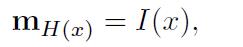
- O O O :(Output feature map) - 给定新输入和当前记忆状态,产生一个新的输出(在特征表示空间上)即负责根据输入获取memory单元的输出。从记忆里结合输入,把合适的记忆抽取出来,返回一个向量。每次获得一个向量,代表了一次推理过程。
- R R R :(Response) - 将output(即O)转化到目标形式(例:一个文本的回复或者一个动作),即将memory的输出转换为目标输出。
所以,I、R算是memory的配套设施,G、O则是直接与memory交互。
简单来说,就是输入的文本经过 I I I 模块编码成向量,然后将其作为 G G G 模块的输入,该模块根据输入的向量对memory进行读写操作,即对memory进行更新。然后 O O O 模块会根据Question(也会经过Input模块进行编码成为向量)对memory的内容进行权重处理,将memory按照与Question的相关程度进行组合得到输出向量,最终 R R R 模块根据输出向量编码生成一个自然语言的答案出来。
Memory Networks的处理过程
给定一个输入 x x x(例:字符、词或者句子(视处理力度而定),图像或者声音信号),模型处理过程如下:
- 将x转化为中间特征表示 I ( x ) I(x) I(x).
- 使用新输入更新记忆 m i : m i = G ( m i , I ( x ) , m ) , ∀ i m_i: m_i = G(m_i,I(x),m),\\forall i mi:mi=G(mi,I(x),m),∀i
- 使用新输入的中间特征表示和记忆计算输出特征 o : o = O ( I ( x ) , m ) o: o = O(I(x),m) o:o=O(I(x),m)
- 最后,解码输出特征到最终回复: r = R ( o ) r = R(o) r=R(o)
这个过程在训练和测试时都适用,两者之间的区别在于:测试时记忆也会被存储,但模型参数 I I I, G G G, O O O, R R R将不会再更新。 I I I, G G G, O O O, R R R可以使用现有任何机器学习的方法来实现(SVM, 决策树)。
组件 I I I: I I I可以使用标准的预处理步骤来实现,比如输入文本的语法分析、指代消解、实体识别等。它同样也可以将输入编码到一个中间的特征表示(将文本转化为稀疏或者稠密的特征向量)。
组件
G
G
G:
G
G
G最简单的G的形式可以是将
I
(
x
)
I(x)
I(x)储存起来的槽位(slot):
m
H
(
x
)
=
I
(
x
)
m_{H(x)} = I(x)
mH(x)=I(x)
其中
H
(
x
)
H(x)
H(x)是选择槽位的一个函数。即,
G
G
G只更新m的索引
H
(
x
)
H(x)
H(x),其他索引下的记忆部分将保持不变。更复杂的
G
G
G的实现还可以允许
G
G
G去根据当前输入
x
x
x得到的新证据去更新先前存储的记忆。如果输入是字符级别或者词级别的你也可以将其进行分组。
如果记忆非常庞大(假设要记忆整个Freebase或者Wikipedia),你可能不得不把记忆使用 H ( x ) H(x) H(x)来组织起来。
如果记忆已经被填满。你也可以使用 H H H来实现一种遗忘机制。
O O O和 R R R组件: O O O组件被特别应用于读取记忆和执行推断, R R R组件则根据 O O O的输出产生最终回复。例:在QA中,使用 O O O查找相关的记忆,然后 R R R生成文字来组成答案。 R R R可以是RNN,视 O O O的输出而定。这种设计基于的假设是,如果没有限定在这种记忆上,RNN会表现得相当差(事实上很多场景下确实如此)。
记忆网络在nlp的使用:
场景:给一个段落和一个问题,给出回答
-
I I I: 输入的是一句话,简单地将I转换为一个频率的向量空间模型。
-
m m m: 记忆卡槽list。
-
G G G:简单地把读到的对话组里的每一句话的向量空间模型,插到记忆的list里,这里默认记忆插槽比对话组句子还多。
-
O O O:就是输入一个问题 x x x,将最合适的 k k k个支撑记忆(the supporting memories,在下文的数据集里会举出例子),也就是 t o p − k top-k top−k。做法就是把记忆数组遍历,挑出最大的值。最后, O O O返回一个长度为 k k k的数组。
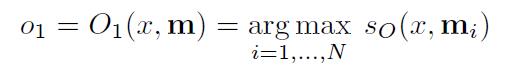
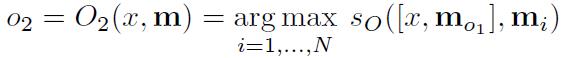
-
R R R:利用 O O O得到的输出,返回一个词汇 w w w
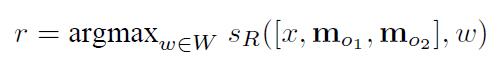
-
打分函数:在 O O O和 R R R中的打分函数:
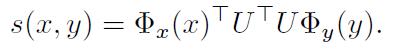
损失函数
采用margin ranking loss,这个与支持向量机的损失函数类似。(即是选出最合适中间结果,和得到最好的预测输出。)
理解
- 记忆网络是一个组件形式的模型,每个模型相互对立又相互影响。每个组件没有固定的模型,可以是传统的模型,也可以是神经网络。
- 论文的缺陷没有思想端到端的训练,端到端的训练将在下面介绍。
- 原论文给了一个QA的例子,但由于这个模型并没有广泛使用这里就不介绍了。我们转而介绍一种常用的端到端的记忆网络实现。
End-To-End Memory Network
这篇文章是上面一篇文章的基础之上提出来的端到端的训练方式。并提出重复的去提取有用的信息,实现多次推理的过程。End-To-End Memory Networks
端到端的记忆网络本质上也是一种RNN架构,但与RNN不同之处在于,在递归过程中会多次读取大型外部存储的记忆来输出一个符号。下面介绍的Memory Network可以有很多层,也易于反向传播,需要对网络的每一层进行监督训练。它以端到端的形式被应用于QA和Aspect Based Sentiment。
模型将一系列离散的输入 x i , . . . , x n x_i,...,x_n xi,...,xn存储在记忆中,并接受一个查询 q q q,输出回答 a a a。模型会将所有的 x x x写为记忆存储在一个固定大小的缓存中,然后寻求一个 x x x和 q q q的连续表示。该连续表示会被多跳处理以输出a。这使得错误信号能够在多级记忆中反向传播到输入。
Single Layer 单次推理
整个模型是很多层堆起来的,我们先介绍单个层,如图a所示。
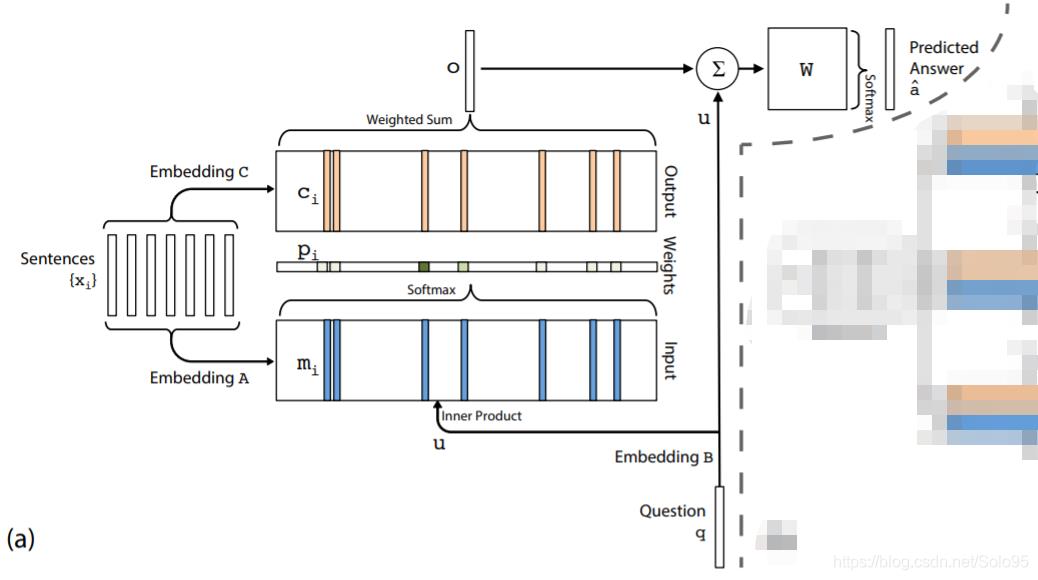
使用输入集合
S
S
S =
x
1
,
x
2
,
…
x
i
,
…
,
x
n
{x1,x2,…xi,…,xn}
x1,x2,…xi,…,xn表示上下文知识使用输入向量
q
q
q表示问题,使用输出向量
a
^
\\hat{a}
a^表示预测答案。记忆网络模型通过对上下文集合S和问题向量q的数学变换,得到对应于问题的答案。
输入记忆表示(Input memory representation):把词进行embedding,变成向量放入m中。假定我们把给定输入集
x
i
,
.
.
.
,
x
n
x_i,...,x_n
xi,...,xn 存储在记忆中。整个输入集
x
i
x_i
xi都会经由每个
x
i
x_i
xi所处的连续空间的嵌入(embedding)被转化为维度为
d
d
d的记忆向量
m
i
m_i
mi,最简单的实现方法可以使用一个嵌入矩阵
A
(
d
×
V
)
A ( d × V )
A(d×V),查询
q
q
q也会被嵌入,可以用维度与
A
A
A相同的嵌入矩阵
B
B
B来得到一个中间状态
u
u
u,在嵌入空间上,我们使用内积计算
u
u
u和记忆
m
i
m_i
mi的匹配程度,然后再softmax:
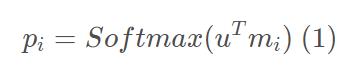
- q:对问题q进行同样的embedding
- 计算u和记忆m的匹配程度。
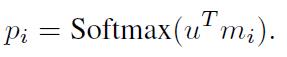
输出记忆表示(Output memory representation):记忆 m m