java解析xml获取标签属性值,面试题+笔记+项目实战
Posted 程序员环西
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java解析xml获取标签属性值,面试题+笔记+项目实战相关的知识,希望对你有一定的参考价值。
为了更好的梳理相关知识,咱们先看纯手绘知识体系图
1.1 Kafka知识体系大纲
由于我手绘这些知识体系大纲是用的xmind软件,无法上传,所以都以截图的形式展示,细节处不清楚(毕竟图片形式有限)
1.2 RabbitMQ知识体系大纲
1.3 RocketMQ知识体系大纲
看完知识大纲,该刷面试了
2.1 刷刷Kafka面试
- Kafka的用途有哪些?使用场景如何?
- Kafka中的ISR、AR又代表什么?ISR的伸缩又指什么
- Kafka中的HW、LEO、LSO、LW等分别代表什么?
- Kafka中是怎么体现消息顺序性的?
- Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么?
- Kafka生产者客户端的整体结构是什么样子的?
- Kafka生产者客户端中使用了几个线程来处理?分别是什么?
- Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
- “消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果正确,那么有没有什么hack的手段?
- 有哪些情形会造成重复消费?
- 哪些情景下会造成消息漏消费?
- KafkaConsumer是非线程安全的,那么怎么样实现多线程消费?
- 简述消费者与消费组之间的关系
- 当你使用kafka-topics.sh创建(删除)了一个topic之后,Kafka背后会执行什么逻辑?
- topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
- topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
- 创建topic时如何选择合适的分区数?
- Kafka目前有哪些内部topic,它们都有什么特征?各自的作用又是什么?
- 优先副本是什么?它有什么特殊的作用?
- Kafka有哪几处地方有分区分配的概念?简述大致的过程及原理
- 简述Kafka的日志目录结构
- Kafka中有哪些索引文件?
- 如果我指定了一个offset,Kafka怎么查找到对应的消息?
- 如果我指定了一个timestamp,Kafka怎么查找到对应的消息?
- 聊一聊你对Kafka的Log Retention的理解
- 聊一聊你对Kafka的Log Compaction的理解
- 聊一聊你对Kafka底层存储的理解
- 聊一聊Kafka的延时操作的原理
- 聊一聊Kafka控制器的作用
- Kafka的旧版Scala的消费者客户端的设计有什么缺陷?
- 消费再均衡的原理是什么?(提示:消费者协调器和消费组协调器)
- Kafka中的幂等是怎么实现的?
- Kafka中的事务是怎么实现的?
- 失效副本是指什么?有哪些应对措施?
- 多副本下,各个副本中的HW和LEO的演变过程
- Kafka在可靠性方面做了哪些改进?(HW, LeaderEpoch)
- 为什么Kafka不支持读写分离?
- Kafka中的延迟队列怎么实现
- Kafka中怎么实现死信队列和重试队列?
- Kafka中怎么做消息审计?
- Kafka中怎么做消息轨迹?
- 怎么计算Lag?(注意read_uncommitted和read_committed状态下的不同)
- Kafka有哪些指标需要着重关注?
- Kafka的哪些设计让它有如此高的性能?
2.2 刷刷ActiveMQ面试
1.什么是 ActiveMQ?
2. ActiveMQ 服务器宕机怎么办?
3. 丢消息怎么办?
4. 持久化消息非常慢
5. 消息的不均匀消费
6. 死信队列
7. ActiveMQ 中的消息重发时间间隔和重发次数吗?
2.3 刷刷RabbitMQ面试
- RabbitMQ 中的 broker 是指什么?cluster 又是指什么?
- 什么是元数据?元数据分为哪些类型?包括哪些内容?与 cluster 相关的元数据有哪些?元数据是如何保存的?元数据在 cluster 中是如何分布的?
- RAM node 和 disk node 的区别?
- RabbitMQ 上的一个 queue 中存放的 message 是否有数量限制?
- RabbitMQ 概念里的 channel、exchange 和 queue 这些东东是逻辑概念,还是对应着进程实体?这些东东分别起什么作用?
- vhost 是什么?起什么作用?
- 在单 node 系统和多 node 构成的 cluster 系统中声明 queue、exchange ,以及进行 binding 会有什么不同?
- 客户端连接到 cluster 中的任意 node 上是否都能正常工作?
- 若 cluster 中拥有某个 queue 的 owner node 失效了,且该 queue 被声明具有durable 属性,是否能够成功从其他 node 上重新声明该 queue ?
- cluster 中 node 的失效会对 consumer 产生什么影响?若是在 cluster 中创建了mirrored queue ,这时 node 失效会对 consumer 产生什么影响?
- 能够在地理上分开的不同数据中心使用 RabbitMQ cluster 么?
- 为什么 heavy RPC 的使用场景下不建议采用 disk node ?
- 向不存在的 exchange 发 publish 消息会发生什么?向不存在的 queue 执行consume 动作会发生什么?
- routing_key 和 binding_key 的最大长度是多少?
- RabbitMQ 允许发送的 message 最大可达多大?
- 什么情况下 producer 不主动创建 queue 是安全的?
- “dead letter”queue 的用途?
- 为什么说保证 message 被可靠持久化的条件是 queue 和 exchange 具有durable 属性,同时 message 具有 persistent 属性才行?
- 什么情况下会出现 blackholed 问题?
- 如何防止出现 blackholed 问题?
- Consumer Cancellation Notification 机制用于什么场景?
- Basic.Reject 的用法是什么?
- 为什么不应该对所有的 message 都使用持久化机制?
- RabbitMQ 中的 cluster、mirrored queue,以及 warrens 机制分别用于解决什么问题?存在哪些问题?
全部刷题的答案已经整理好,如下题所示的PDF文件了,篇幅原因就不再一一的截图了,需要看答案的可以在文末领取

看完体系大纲+面试刷题,有知识漏洞那就继续往下看学习笔记
3.1 Kafka源码解析与实战
第1章 Kafka简介
1.1 Kafka诞生的背景
1.2 Kafka在LinkedIn内部的应用
1.3 Kafka的主要设计目标
1.4 为什么使用消息系统
第2章 Kafka的架构
2.1 Kafka的基本组成
2.2 Kafka的拓扑结构
2.3 Kafka内部的通信协议
第3章 Broker概述
3.1 Broker的启动
3.2 Broker内部的模块组成
第4章 Broker的基本模块
4.1 SocketServer
4.2 KafkaRequestHandlerPool
4.3 KafkaApis
4.4 KafkaHealthcheck
第5章 Broker的控制管理模块
5.1 KafkaController的选举策略
5.2 KafkaController的初始化
5.3 Topic的分区状态转换机制
5.4 Topic分区的领导者副本选举策略
5.5 Topic分区的副本状态转换机制
5.6 KafkaController内部的监听器
5.7 Kafka集群的负载均衡流程
5.8 Kafka集群的Topic删除流程
5.9 KafkaController的通信模块
第6章 Topic的管理工具
6.1 kafka-topics.sh
6.2 kafka-reassign-partitions.sh
6.3 kafka-preferred-replica-election.sh
第7章 生产者
7.1 设计原则
7.2 示例代码
7.3 模块组成
7.4 发送模式
第8章 消费者
8.1 简单消费者
8.2 高级消费者
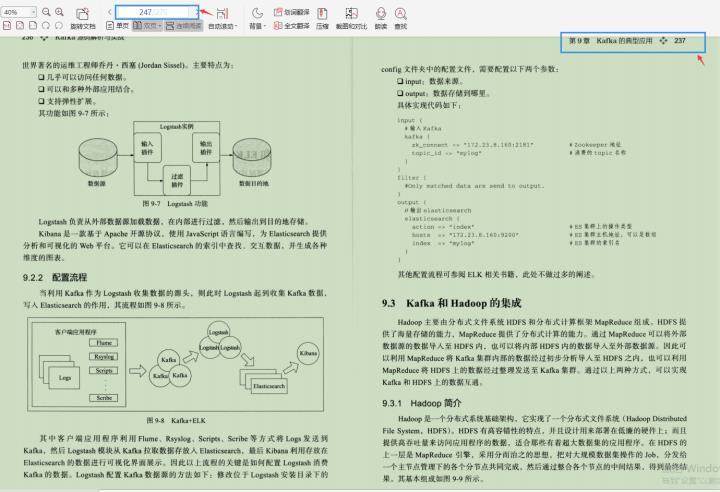
第9章 Kafka的典型应用
9.1 Kafka和Storm的集成
9.2 Kafka和ELK的集成
9.3 Kafka和Hadoop的集成
9.4 Kafka和Spark的集成
第10章 Kafka的综合实例
10.1 安防大数据的主要应用
10.2 Kafka在安防整体解决方案中的角色
10.3 典型业务
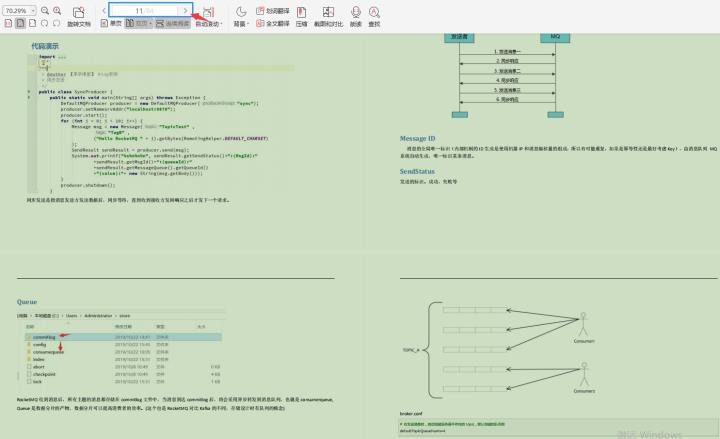
3.2 手写RocketMQ笔记
第一节:RocketMQ介绍
1.1 核心概念
1.2 RocketMQ的设计理念和目标
第二节:RocketMq中消息的发送
2.1 单向(OneWay)发送
2.2 可靠同步发送
2.3 可靠异步发送
2.4 RocketMQ中消息发送的权衡
第三节:RocketMQ消息消费
3.1 集群消费和广播消费
3.2 消费方式
第四节:深入消息发送
4.1 消息生产者流程
4.2 批量消息发送
4.3 消息重试机制
第五节:深入消息模式
5.1 拉模式 5.2 推模式
第六节:顺序消息
6.1 全局顺序消息
6.2 部分顺序消息
第七节:延时消息
7.1 概念介绍
7.2 适用场景
7.3 使用方式
第八节:死信队列
8.1 概念介绍
8.2 适用场景
第九节:消费幂等
9.1 什么是消息幂等
9.2 需要处理的场景
9.3 处理方法
第十节:消息过滤
10.1 概念介绍
10.2 表达式过滤
10.3 类过滤
第十一节:RocketMQ存储概要设计
11.1 消息存储结构
11.2 内存映射
11.3 文件刷盘机制
11.4 过期文件删除
第十二节:RocketMQ中的事务消息
12.1 事务消息实现思想
12.2 两阶段提交
12.3 事务状态回查机制
12.3 代码实现
第十三节:RocketMQ主从同步(HA)机制
13.1 RocketMQ集群部署模式
13.2 主从复制原理
13.3 读写分离机制
13.4 与Spring集成
13.5 与SpringBoot集成
第十四节:限时订单实战
14.1 什么是限时订单
14.2 如何实现限时订单
14.3 用RocketMQ实现限时订单
第十五节:RocketMQ源码分析
15.1 RocketMQ整体架构
15.2 NameServer
15.3 RocketMQ 服务启动
15.4 源码分析之消息的来龙去脉
3.3 RabbitMQ实战学习指南
第1章 RabbitMQ简介
1.1 什么是消息中间件
1.2 消息中间件的作用
1.3 RabbitMQ的起源
1.4 RabbitMQ的安装及简单使用
第2章 RabbitMQ入门
2.1 相关概念介绍
2.2 AMQP协议介绍
第3章 客户端开发向导
3.1 连接RabbitMQ
3.2 使用交换器和队列
3.3 发送消息
3.4 消费消息
3.5 消费端的确认与拒绝
3.6 关闭连接
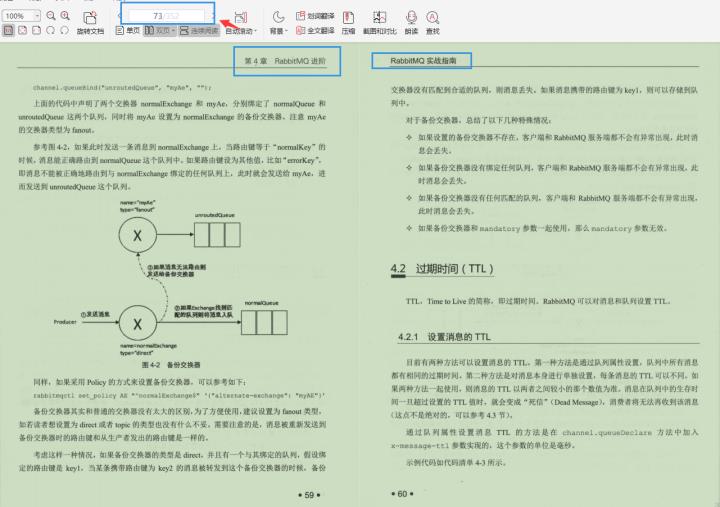
第4章 RabbitMQ进阶
4.1 消息何去何从
4.2 过期时间(TTL)
4.3 死信队列
4.4 延迟队列
4.5 优先级队列
4.6 RPC实现
4.7 持久化
4.8 生产者确认
4.9 消费端要点介绍
4.10 消息传输保障
第5章 RabbitMQ管理
5.1 多租户与权限
5.2 用户管理
5.3 Web端管理
5.4 应用与集群管理
5.5 服务端状态
5.6 HTTPAPI接口管理
第6章 RabbitMQ配置
6.1 环境变量
6.2 配置文件
6.3 参数及策略
第7章 RabbitMQ运维
7.1 集群搭建
7.2 查看服务日志
7.3 单节点故障恢复
7.4 集群迁移
7.5 集群监控
第8章 跨越集群的界限
8.1 Federation
8.2 Shovel
第9章 RabbitMQ高阶
9.1 存储机制
9.2 内存及磁盘告警
9.3 流控
9.4 镜像队列
第10章 网络分区
10.1 网络分区的意义
10.2 网络分区的判定
10.3 网络分区的模拟
10.4 网络分区的影响
10.5 手动处理网络分区
10.6 自动处理网络分区
10.7 案例:多分区情形
第11章 RabbitMQ扩展
11.1 消息追踪
11.2 负载均衡
面试结束复盘查漏补缺
每次面试都是检验自己知识与技术实力的一次机会,面试结束后建议大家及时总结复盘,查漏补缺,然后有针对性地进行学习,既能提高下一场面试的成功概率,还能增加自己的技术知识栈储备,可谓是一举两得。
以下最新总结的阿里P6资深Java必考题范围和答案,包含最全mysql、Redis、Java并发编程等等面试题和答案,用于参考~
资料免费领取方式:点赞关注后,戳这里免费领取
重要的事说三遍,关注+关注+关注!

更多笔记分享
对性地进行学习,既能提高下一场面试的成功概率,还能增加自己的技术知识栈储备,可谓是一举两得。
以下最新总结的阿里P6资深Java必考题范围和答案,包含最全MySQL、Redis、Java并发编程等等面试题和答案,用于参考~
资料免费领取方式:点赞关注后,戳这里免费领取
重要的事说三遍,关注+关注+关注!
[外链图片转存中…(img-iI56RwNE-1625940752741)]
[外链图片转存中…(img-pDI8ip8B-1625940752742)]
更多笔记分享

以上是关于java解析xml获取标签属性值,面试题+笔记+项目实战的主要内容,如果未能解决你的问题,请参考以下文章