BP预测基于人工蜂群算法改进BP神经网络实现数据预测
Posted 博主QQ2449341593
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BP预测基于人工蜂群算法改进BP神经网络实现数据预测相关的知识,希望对你有一定的参考价值。
一、 BP神经网络预测算法简介
说明:1.1节主要是概括和帮助理解考虑影响因素的BP神经网络算法原理,即常规的BP模型训练原理讲解(可根据自身掌握的知识是否跳过)。1.2节开始讲基于历史值影响的BP神经网络预测模型。
使用BP神经网络进行预测时,从考虑的输入指标角度,主要有两类模型:
1.1 受相关指标影响的BP神经网络算法原理
如图一所示,使用MATLAB的newff函数训练BP时,可以看到大部分情况是三层的神经网络(即输入层,隐含层,输出层)。这里帮助理解下神经网络原理:
1)输入层:相当于人的五官,五官获取外部信息,对应神经网络模型input端口接收输入数据的过程。
2)隐含层:对应人的大脑,大脑对五官传递来的数据进行分析和思考,神经网络的隐含层hidden Layer对输入层传来的数据x进行映射,简单理解为一个公式hiddenLayer_output=F(w*x+b)。其中,w、b叫做权重、阈值参数,F()为映射规则,也叫激活函数,hiddenLayer_output是隐含层对于传来的数据映射的输出值。换句话说,隐含层对于输入的影响因素数据x进行了映射,产生了映射值。
3)输出层:可以对应为人的四肢,大脑对五官传来的信息经过思考(隐含层映射)之后,再控制四肢执行动作(向外部作出响应)。类似地,BP神经网络的输出层对hiddenLayer_output再次进行映射,outputLayer_output=w *hiddenLayer_output+b。其中,w、b为权重、阈值参数,outputLayer_output是神经网络输出层的输出值(也叫仿真值、预测值)(理解为,人脑对外的执行动作,比如婴儿拍打桌子)。
4)梯度下降算法:通过计算outputLayer_output和神经网络模型传入的y值之间的偏差,使用算法来相应调整权重和阈值等参数。这个过程,可以理解为婴儿拍打桌子,打偏了,根据偏离的距离远近,来调整身体使得再次挥动的胳膊不断靠近桌子,最终打中。
再举个例子来加深理解:
图一所示BP神经网络,具备输入层、隐含层和输出层。BP是如何通过这三层结构来实现输出层的输出值outputLayer_output,不断逼近给定的y值,从而训练得到一个精准的模型的呢?
从图中串起来的端口,可以想到一个过程:坐地铁,将图一想象为一条地铁线路。王某某坐地铁回家的一天:在input起点站上车,中途经过了很多站(hiddenLayer),然后发现坐过头了(outputLayer对应现在的位置),那么王某某将会根据现在的位置离家(目标Target)的距离(误差Error),返回到中途的地铁站(hiddenLayer)重新坐地铁(误差反向传递,使用梯度下降算法更新w和b),如果王某某又一次发生失误,那么将再次进行这个调整的过程。
从在婴儿拍打桌子和王某某坐地铁的例子中,思考问题:BP的完整训练,需要先传入数据给input,再经过隐含层的映射,输出层得到BP仿真值,根据仿真值与目标值的误差,来调整参数,使得仿真值不断逼近目标值。比如(1)婴儿受到了外界的干扰因素(x),从而作出反应拍桌(predict),大脑不断的调整胳膊位置,控制四肢拍准(y、Target)。(2)王某某上车点(x),过站点(predict),不断返回中途站来调整位置,到家(y、Target)。
在这些环节中,涉及了影响因素数据x,目标值数据y(Target)。根据x,y,使用BP算法来寻求x与y之间存在的规律,实现由x来映射逼近y,这就是BP神经网络算法的作用。再多说一句,上述讲的过程,都是BP模型训练,那么最终得到的模型虽然训练准确,但是找到的规律(bp network)是否准确与可靠呢。于是,我们再给x1到训练好的bp network中,得到相应的BP输出值(预测值)predict1,通过作图,计算Mse,Mape,R方等指标,来对比predict1和y1的接近程度,就可以知道模型是否预测准确。这是BP模型的测试过程,即实现对数据的预测,并且对比实际值检验预测是否准确。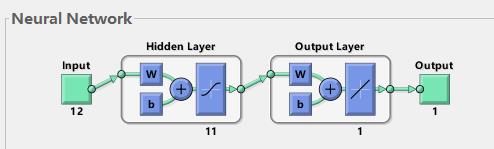
图一 3层BP神经网络结构图
1.2 基于历史值影响的BP神经网络
以电力负荷预测问题为例,进行两种模型的区分。在预测某个时间段内的电力负荷时:
一种做法,是考虑 t 时刻的气候因素指标,比如该时刻的空气湿度x1,温度x2,以及节假日x3等的影响,对 t 时刻的负荷值进行预测。这是前面1.1所说的模型。
另一种做法,是认为电力负荷值的变化,与时间相关,比如认为t-1,t-2,t-3时刻的电力负荷值与t时刻的负荷值有关系,即满足公式y(t)=F(y(t-1),y(t-2),y(t-3))。采用BP神经网络进行训练模型时,则输入到神经网络的影响因素值为历史负荷值y(t-1),y(t-2),y(t-3),特别地,3叫做自回归阶数或者延迟。给到神经网络中的目标输出值为y(t)。
二、人工蜂群算法
受到蜜蜂群体的有组织的觅食过程的启发,Karaboga提出了模拟蜜蜂群体觅食过程的人工蜂群(Artificial Bee Colony) 算法用于解决多维度多峰谷的优化问题。该算法创始之初被用来寻找Sphere、Rosenbrock和Rastrigin函数的最小值。 首先对蜜蜂基于摇摆舞进行觅食的过程特征进行介绍。在图1中,存在两个已发现的食物源A和B。初始时,潜在工蜂以非雇佣蜂的身份进行搜索。它并不知道蜂房附近的任何蜜源的信息。因此,它有以下两个可能的选择: (1)成为一个侦察蜂,秉着自身潜在动力或外在因素自发的搜索蜂房附近的区域(见图1中的S); (2)在观看摆尾舞后,成为一个被招募者,并开始搜索蜜源(见图1中的R)。 在定位蜜源之后,该蜜蜂能够利用自身的能力来记住食物源的位置,并立刻对它进行探索。该蜜蜂现在成为了一个雇佣蜂。雇佣蜂采到蜂蜜后,从蜜源处返回蜂房并将蜂蜜卸载到蜜室中。在卸载完蜂蜜后,雇佣蜂有下列三个选择: (1)放弃已经采集过的蜜源,成为一个受其他摇尾舞招募的跟随者(UF)。 (2)施展摇尾舞技,招募蜂房内的同伴,再次回到原先采集过的食物源(EF1)。 (3)不招募其它的蜜蜂,继续探索采集过的食物源(EF2)。 ![]()
图1 蜜蜂觅食行为图
二、算法流程
人工蜂群算法由连续的四个阶段组成,分别是初始化阶段、引领(雇佣)蜂阶段、跟随蜂阶端和侦察蜂阶段。 人工蜂群算法中将人工蜂群分为引领蜂、跟随蜂和侦察蜂三类,每一次搜索过程中,引领蜂和跟随蜂是先后开采食物源,即寻找最优解,而侦察蜂是观察是否陷入局部最优,若陷入局部最优则随机地搜索其它可能的食物源。每个食物源代表问题一个可能解,食物源的花蜜量对应相应解的质量(适应度值f i t fitfit)。 ABC算法流程图如图2所示。 ![]()
图2 ABC算法流程图
1、初始化阶段

![]()
2、引领蜂阶段
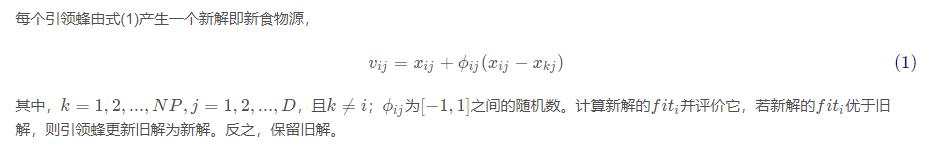
 3、跟随蜂阶段
3、跟随蜂阶段

![]()
4、侦察蜂阶段

5、食物源

三、部分代码
%
clc;
clear;
close all;
%% Problem Definition
CostFunction=@(x) Sphere(x); % Cost Function
nVar=5; % Number of Decision Variables
VarSize=[1 nVar]; % Decision Variables Matrix Size
VarMin=-10; % Decision Variables Lower Bound
VarMax= 10; % Decision Variables Upper Bound
%% ABC Settings
MaxIt=200; % Maximum Number of Iterations
nPop=100; % Population Size (Colony Size)
nOnlooker=nPop; % Number of Onlooker Bees
L=round(0.6*nVar*nPop); % Abandonment Limit Parameter (Trial Limit)
a=1; % Acceleration Coefficient Upper Bound
%% Initialization
% Empty Bee Structure
empty_bee.Position=[];
empty_bee.Cost=[];
% Initialize Population Array
pop=repmat(empty_bee,nPop,1);
% Initialize Best Solution Ever Found
BestSol.Cost=inf;
% Create Initial Population
for i=1:nPop
pop(i).Position=unifrnd(VarMin,VarMax,VarSize);
pop(i).Cost=CostFunction(pop(i).Position);
if pop(i).Cost<=BestSol.Cost
BestSol=pop(i);
end
end
% Abandonment Counter
C=zeros(nPop,1);
% Array to Hold Best Cost Values
BestCost=zeros(MaxIt,1);
%% ABC Main Loop
for it=1:MaxIt
% Recruited Bees
for i=1:nPop
% Choose k randomly, not equal to i
K=[1:i-1 i+1:nPop];
k=K(randi([1 numel(K)]));
% Define Acceleration Coeff.
phi=a*unifrnd(-1,+1,VarSize);
% New Bee Position
newbee.Position=pop(i).Position+phi.*(pop(i).Position-pop(k).Position);
% Evaluation
newbee.Cost=CostFunction(newbee.Position);
% Comparision
if newbee.Cost<=pop(i).Cost
pop(i)=newbee;
else
C(i)=C(i)+1;
end
end
% Calculate Fitness Values and Selection Probabilities
F=zeros(nPop,1);
MeanCost = mean([pop.Cost]);
for i=1:nPop
F(i) = exp(-pop(i).Cost/MeanCost); % Convert Cost to Fitness
end
P=F/sum(F);
% Onlooker Bees
for m=1:nOnlooker
% Select Source Site
i=RouletteWheelSelection(P);
% Choose k randomly, not equal to i
K=[1:i-1 i+1:nPop];
k=K(randi([1 numel(K)]));
% Define Acceleration Coeff.
phi=a*unifrnd(-1,+1,VarSize);
% New Bee Position
newbee.Position=pop(i).Position+phi.*(pop(i).Position-pop(k).Position);
% Evaluation
newbee.Cost=CostFunction(newbee.Position);
% Comparision
if newbee.Cost<=pop(i).Cost
pop(i)=newbee;
else
C(i)=C(i)+1;
end
end
% Scout Bees
for i=1:nPop
if C(i)>=L
pop(i).Position=unifrnd(VarMin,VarMax,VarSize);
pop(i).Cost=CostFunction(pop(i).Position);
C(i)=0;
end
end
% Update Best Solution Ever Found
for i=1:nPop
if pop(i).Cost<=BestSol.Cost
BestSol=pop(i);
end
end
% Store Best Cost Ever Found
BestCost(it)=BestSol.Cost;
% Display Iteration Information
disp(['Iteration ' num2str(it) ': Best Cost = ' num2str(BestCost(it))]);
end
%% Results
figure;
%plot(BestCost,'LineWidth',2);
semilogy(BestCost,'LineWidth',2);
xlabel('Iteration');
ylabel('Best Cost');
grid on;
四、仿真结果
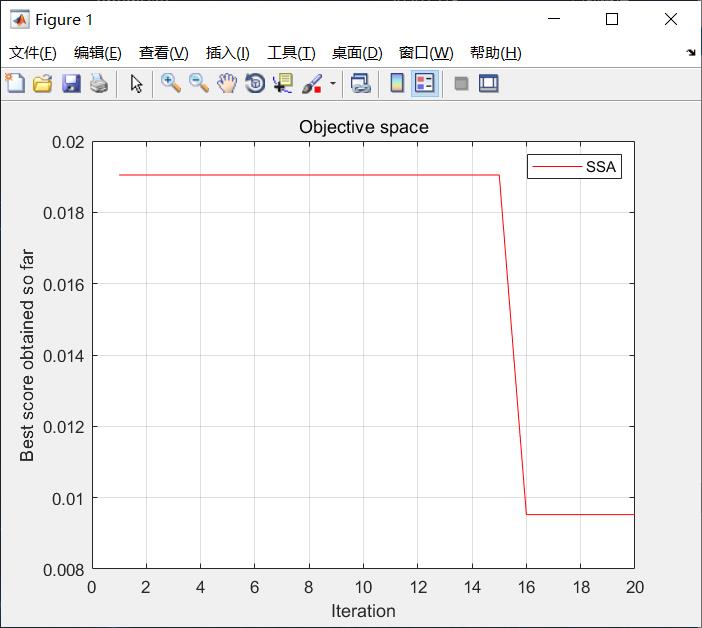
图2人工蜂群算法收敛曲线
测试统计如下表所示
| 测试结果 | 测试集正确率 | 训练集正确率 |
|---|---|---|
| BP神经网络 | 100% | 95% |
| ABC-BP | 100% | 99.8% |
五、参考文献及代码私信博主
《基于BP神经网络的宁夏水资源需求量预测》
以上是关于BP预测基于人工蜂群算法改进BP神经网络实现数据预测的主要内容,如果未能解决你的问题,请参考以下文章
DELM回归预测基于matlab人工蜂群算法改进深度学习极限学习机数据回归预测含Matlab源码 1885期
DELM回归预测基于matlab人工蜂群算法改进深度学习极限学习机数据回归预测含Matlab源码 1885期
BP预测基于Logistic混沌映射改进麻雀算法改进BP神经网络实现数据预测
BP预测基于Tent混沌映射改进麻雀算法改进BP神经网络实现数据预测