预测模型基于麻雀算法改进核极限学习机(KELM)分类算法 matlab源码
Posted 博主QQ2449341593
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了预测模型基于麻雀算法改进核极限学习机(KELM)分类算法 matlab源码相关的知识,希望对你有一定的参考价值。
一、核极限学习机
本文将介绍一种新的SLFN的算法,极限学习机,该算法将随机产生输入层和隐含层间的连接权值和隐含层神经元的阈值,且在训练过程中无需调整,只需要设置隐含层的神经元的个数,便可以获得唯一最优解,与传统的训练方法相比,该方法具有学习速率快、泛化性能好等优点。

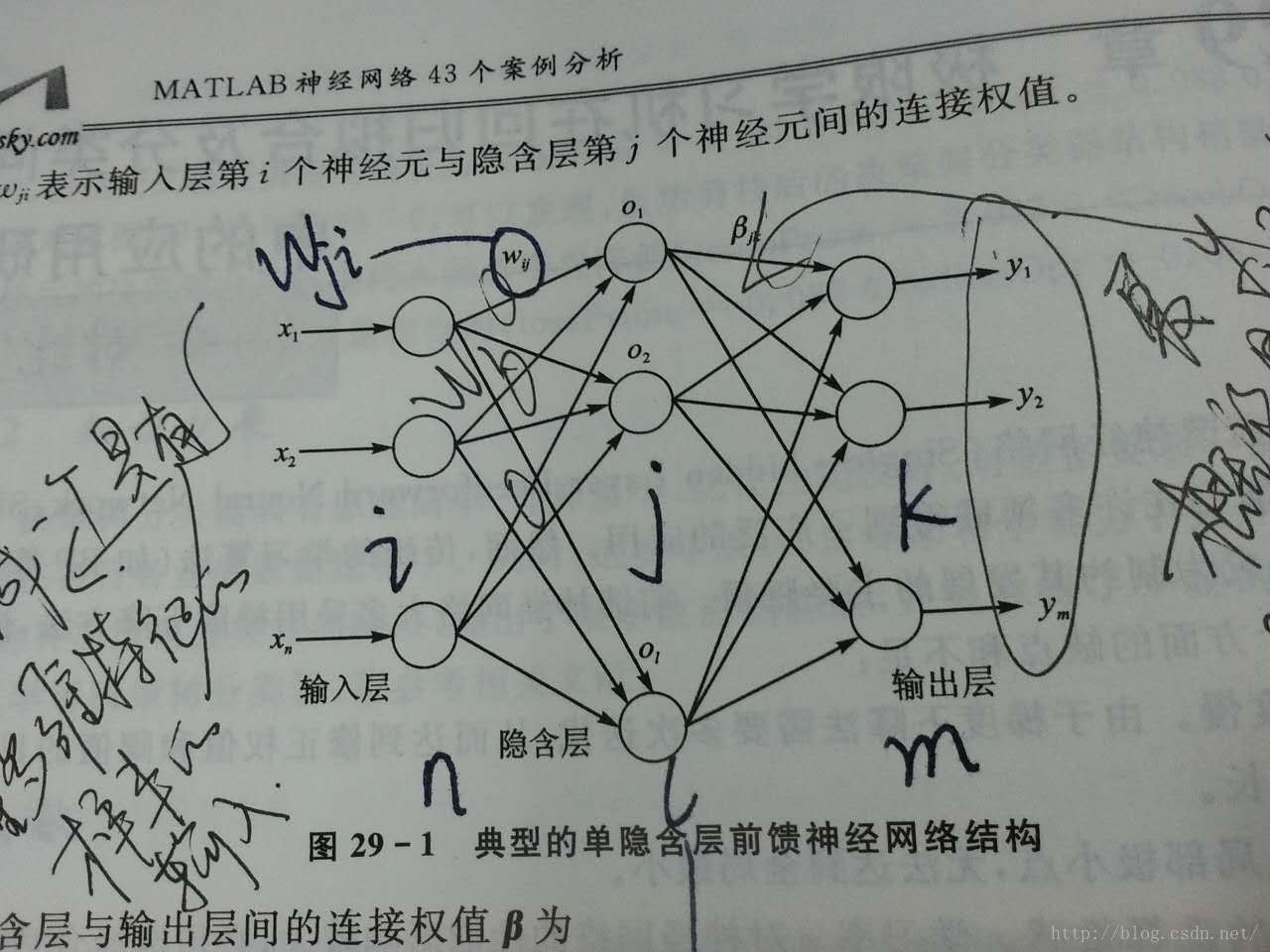
典型的单隐层前馈神经网络如上图所示,输入层与隐含层,隐含层与输出层之间是全连接的。输入层的神经元的个数是根据样本的而特征数的多少来确定的,输出层的神经元的个数是根据样本的种类数来确定的


设隐含层神经元的阈值 b为:







当隐层神经元的个数和样本数相同时(10)式有唯一的解,也就是说零误差的逼近训练样本。通常的学习算法中,W和b需要不断进行调整,但研究结果告诉我们,他们事实上是不需要进行不断调整的,甚至可以随意指定。调整他们不仅费时,而且并没有太多的好处。(此处有疑虑,可能是断章取义,这个结论有可能是基于某个前提下的)。

二、麻雀算法
优化问题是科学研究和工程实践领域中的热门问题。智能优化算法大多是受到人类智能、生物群体社会性或自然现象规律的启发,在解空间内进行全局优化。麻雀算法于2020年由薛建凯[1]首次提出,是基于麻雀种群的觅食和反捕食行为的一种新型智能优化算法。
麻雀搜索算法的具体步骤描述以及公式介绍:
构建麻雀种群: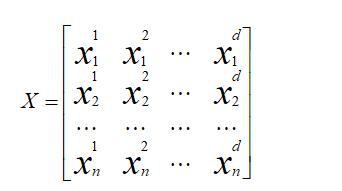
其中,d表示待优化问题的维数,n表示麻雀种群的数量。所有麻雀种群的适应度函数可以表示成如下形式:

其中,Fx表示适应度函数值。
麻雀算法中的麻雀具有两大类分别是发现者和加入者,发现者负责为整个种群寻找食物并为加入者提供觅食的方向,因此,发现者的觅食搜索范围要比加入者的觅食搜索范围大。在每次迭代过程中,发现者按照公式(3)进行迭代。
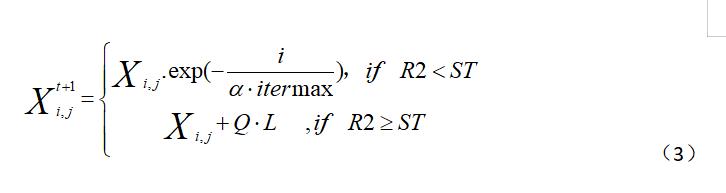
其中,t表示当前迭代次数,Xij表示第i个麻雀种群在第j维中的位置信息,阿尔法表示的0到1的随机数,itermax表示最大迭代次数,Q表示一个服从正态分布的随机数,L是一个1*d并且元素全为1的矩阵,R2属于0-1表示麻雀种群位置的预警值,ST属于0.5-1表示麻雀种群位置的安全值。
当R2<ST时表示 预警值小于安全值,此时觅食环境中没有捕食者,发现者可以进行广泛搜索操作;当R2>ST时意味着种群中有部分麻雀已经发现捕食者,并向种群中的其他麻雀发出预警,所有麻雀都需要飞往安全区域进行觅食。
在觅食过程中,部分加入者会时刻监视发现者,当发现者发现更好的食物,加入者会与其进行争夺,若成功,会立即获得该发现者的食物,否则加入者按照公式(4)进行位置更新。
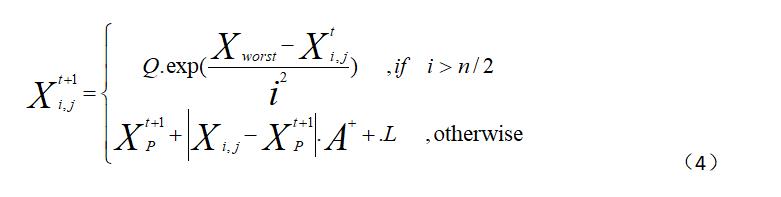
其中,XP表示目前发现者所发现的最优位置,Xworst表示当前全局最差的位置,A表示其元素随机赋值为1或-1的1*d的矩阵并且满足一下关系:
L仍然是一个1*d并且元素全为1的矩阵。当i>n/2时这表明第i个加入者没有获得食物,处于饥饿状态,此时需要飞往其他地方进行觅食,以获得更多的能量。
在麻雀种群中,意识到危险的麻雀数量占总数的10%到20%,这些麻雀的位置是随机产生的,按照公式(5)对意识到危险的麻雀的位置进行不断更新。
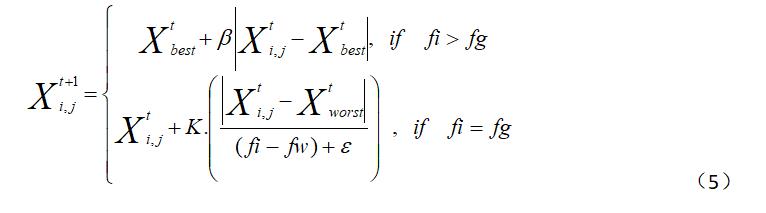
其中,Xbest表示当前全局最优位置,是服从标准正态分布的随机数用来作为步长控制参数,贝塔是一个属于-1到1的随机数,fi表示当前麻雀个体的适应度值,fg表示全局最佳适应度值,fw表示全局最差适应度值,像左耳朵一样的这个是读"一不洗诺"吗?"一不洗诺"表示一个避免分母为0的常数。当fi>fg时表示此时麻雀处于种群边缘,极易受到捕食者的攻击,当fi=fg时表示处于种群中间的麻雀也受到了危险,此时需要靠近其他麻雀以减少被捕食的风险。
三、代码
function [FoodFitness,FoodPosition,Convergence_curve]=SSA(N,Max_iter,lb,ub,dim,fobj)
if size(ub,1)==1
ub=ones(dim,1)*ub;
lb=ones(dim,1)*lb;
end
Convergence_curve = zeros(1,Max_iter);
%Initialize the positions of salps
SalpPositions=initialization(N,dim,ub,lb);
FoodPosition=zeros(1,dim);
FoodFitness=inf;
%calculate the fitness of initial salps
for i=1:size(SalpPositions,1)
SalpFitness(1,i)=fobj(SalpPositions(i,:));
end
[sorted_salps_fitness,sorted_indexes]=sort(SalpFitness);
for newindex=1:N
Sorted_salps(newindex,:)=SalpPositions(sorted_indexes(newindex),:);
end
FoodPosition=Sorted_salps(1,:);
FoodFitness=sorted_salps_fitness(1);
%Main loop
l=2; % start from the second iteration since the first iteration was dedicated to calculating the fitness of salps
while l<Max_iter+1
c1 = 2*exp(-(4*l/Max_iter)^2); % Eq. (3.2) in the paper
for i=1:size(SalpPositions,1)
SalpPositions= SalpPositions';
if i<=N/2
for j=1:1:dim
c2=rand();
c3=rand();
%%%%%%%%%%%%% % Eq. (3.1) in the paper %%%%%%%%%%%%%%
if c3<0.5
SalpPositions(j,i)=FoodPosition(j)+c1*((ub(j)-lb(j))*c2+lb(j));
else
SalpPositions(j,i)=FoodPosition(j)-c1*((ub(j)-lb(j))*c2+lb(j));
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
end
elseif i>N/2 && i<N+1
point1=SalpPositions(:,i-1);
point2=SalpPositions(:,i);
SalpPositions(:,i)=(point2+point1)/2; % % Eq. (3.4) in the paper
end
SalpPositions= SalpPositions';
end
for i=1:size(SalpPositions,1)
Tp=SalpPositions(i,:)>ub';Tm=SalpPositions(i,:)<lb';SalpPositions(i,:)=(SalpPositions(i,:).*(~(Tp+Tm)))+ub'.*Tp+lb'.*Tm;
SalpFitness(1,i)=fobj(SalpPositions(i,:));
if SalpFitness(1,i)<FoodFitness
FoodPosition=SalpPositions(i,:);
FoodFitness=SalpFitness(1,i);
end
end
Convergence_curve(l)=FoodFitness;
l = l + 1;
end
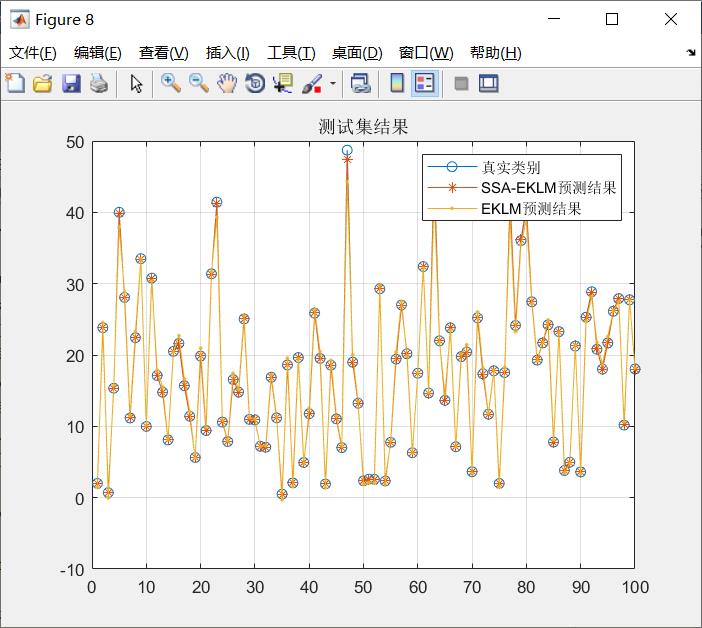
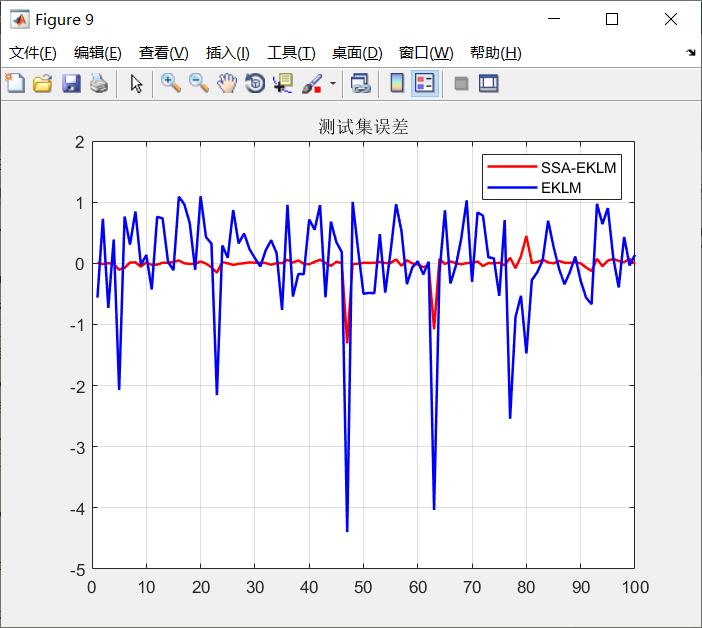
四、参考文献及代码私信博主
以上是关于预测模型基于麻雀算法改进核极限学习机(KELM)分类算法 matlab源码的主要内容,如果未能解决你的问题,请参考以下文章
预测模型基于遗传算法改进核极限学习机(KELM)分类算法 matlab源码
预测模型基于遗传算法改进核极限学习机(KELM)分类算法 matlab源码
预测模型基于狮群算法改进核极限学习机(KELM)分类算法 matlab源码
预测模型基于狮群算法改进核极限学习机(KELM)分类算法 matlab源码