JavaScript经典面试题的专业回答
Posted hugo233
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript经典面试题的专业回答相关的知识,希望对你有一定的参考价值。
前言
(嘘!这里都是被面到过的算法题!)
算法是很多厂子喜欢出的题目,各位被算法题整过的小伙伴们肯定都是咬牙切齿。
好吧,本篇文是福利文。目的是让小伙伴们来找到自信,不再抗拒算法,不再觉得被算法题伤害了😂😂😂
本文最终目的是最后一道题,React Fiber。emmmm,只是提一嘴,很容易的。不要喷我😂😂
题1:股票题。
实现一个函数,由已知的某只股票每天的价格找到一个购买点和一个卖出点,计算返回最大收益。
例如:
输入:[1, 2, 4, 8] 输出:7
输入:[8, 1, 2, 4] 输出:3
// 很明显,这种题目绝对不能写出嵌套循环,例如:
for(){
for(){...}
}
// 这样的算法时间复杂度是 O(n * n);
// 有木有O(n)的解法呢?
// 有的,来理解下题目。 是不是用后面一个数减去见面一个数就能得到差? 差为正则代表能赚,负代表亏钱了。 亏钱就得重新来对伐?
function mf(arr) {
var str = "";
var m = 0;
var e = 0;
for (var i = 1; i < arr.length; i++) {
var t = arr[i] - arr[m];
if (t > e) {
e = t;
str = "第"+(m+1)+"天买入 第"+(i+1)+"天卖出 收益"+e;
}
if (t < 0)
m = i;
}
return str;
}
题2: leetcode 168. Excel表列名称
给定一个正整数,返回它在 Excel 表中相对应的列名称。
1 => A;
2 => B;
3 => C
…
26 => Z;
27 => AA;
28 => AB;
29 => AC
…
52 => AZ;
53 => BA;
54 => BB
…
// 实现下方函数
function convert(num) { // TODO }
// 测试代码:
const output1 = convert(1);
console.log(output1); // A
const output2 = convert(26);
console.log(output2); // Z
const output3 = convert(53);
console.log(output3); // BA
// 理解 其实,这道题很明显是一道10进制转26进制的题目。 主要需要考虑到2个因素
// 1. 1-26 分别对应 A-Z,没有0;
// 2. 超过26进A。(和原来的满10进1是一个道理)
function convert (columnNumber) {
const arr = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L','M', 'N','O','P','Q','R','S','T','U','V','W','X','Y','Z'];
// 小于等于26,直接返回
let n = columnNumber;
if (n <= 26) return arr[n - 1];
let res = '';
while (n > 0) {
// n先减1. 因为数组arr 下标是从0开始。 而题目是从1开始
n--;
// 从后往前拼接
res = arr[n % 26] + res;
n = Math.floor(n / 26); // 取整。
}
return res;
};
};
题3:二叉树遍历
深度优先遍历
先给定一个二叉树数据
const tree = {
value: "-",
left: {
value: '+',
left: {
value: 'a',
},
right: {
value: '*',
left: {
value: 'b',
},
right: {
value: 'c',
}
}
},
right: {
value: '/',
left: {
value: 'd',
},
right: {
value: 'e',
}
}
}
如果你有心,应该能看出来,其实这个数据就是个公式:
(a+b∗c)−d/e(a+b*c)-d/e(a+b∗c)−d/e
那开始上代码了,先来一下深度优先遍历(Depth-First Search,DFS)吧。 当你看到代码里有 dfs 字样的时候,你就应该及时反应过来,这里十有八九是有遍历的。
// 深度遍历——先序遍历
// 递归实现
let result = [];
let dfs = function (node) {
if(node) {
result.push(node.value);
dfs(node.left);
dfs(node.right);
}
}
dfs(tree);
console.log(result); // ["-", "+", "a", "*", "b", "c", "/", "d", "e"]
/* 思路:
1. 先遍历根结点,将值存入数组。
2. 然后递归遍历:先左结点,将值存入数组,继续向下遍历;直到(二叉树为空)子树为空,则遍历结束;
3. 然后再回溯遍历右结点,将值存入数组,这样递归循环,直到(二叉树为空)子树为空,则遍历结束。
*/
// 非递归实现
let dfs = function (nodes) {
let result = [];
let stack = [];
stack.push(nodes);
while(stack.length) { // 等同于 while(stack.length !== 0) 直到栈中的数据为空
let node = stack.pop(); // 取的是栈中最后一个j
result.push(node.value);
if(node.right) stack.push(node.right); // 先压入右子树 保证先序
if(node.left) stack.push(node.left); // 后压入左子树
}
return result;
}
dfs(tree);
/*思路
step 1. 初始化一个栈,将根节点压入栈中;
step 2. 当栈为非空时,循环执行步骤3到4,否则循环结束,得到最终的结果;
step 3. 从队列取得一个结点(其实是取的是栈顶元素),将该值放入结果数组;
step 4. 若该结点的右子树为非空,则将该结点的右子树入栈。若该结点的左子树为非空,则将该结点的左子树入栈;
(ps:先将右结点压入栈中,后压入左结点,从栈中取得时候是取最后一个入栈的结点,而先序遍历要先遍历左子树,后遍历右子树)
*/
// 深度遍历——中序遍历
// 递归实现
let result = [];
let dfs = function (node) {
if(node) {
dfs(node.left);
result.push(node.value); // 直到该结点无左子树 将该结点存入结果数组 接下来并开始遍历右子树
dfs(node.right);
}
}
dfs(tree);
console.log(result); // ["a", "+", "b", "*", "c", "-", "d", "/", "e"]
/*思路你一看就看明白了,就是调了个顺序😂😂😂*/
// 非递归实现?
function dfs(node) {
let result = [];
let stack = [];
while(stack.length || node) { // 是 || 不是 &&
if(node) {
stack.push(node);
node = node.left;
} else {
node = stack.pop();
result.push(node.value);
node = node.right; // 如果没有右子树 会再次向栈中取一个结点即双亲结点
}
}
return result;
}
dfs(tree);
/*思路:
1. 将当前结点压入栈。
2. 然后将左子树当做当前结点。
3. 如果当前结点为空,则将双亲结点取出来,将值保存入数组。
4. 然后将右子树当做当前结点,进行循环。
*/
// 后续遍历。。。 不写了。欢迎小伙伴们自己去写出来。
// 提一下广度优先遍历
let result = [];
let stack = [tree]; // 先将要遍历的树压入栈
let count = 0; // 用来记录执行到第一层
let bfs = function () {
let node = stack[count];
if(node) {
result.push(node.value);
if(node.left) stack.push(node.left);
if(node.right) stack.push(node.right);
count++;
bfs();
}
}
dfc();
console.log(result); // ["-", "+", "/", "a", "*", "d", "e", "b", "c"]
/*思路: 思路应该一看就明白对伐?*/
题4: React Fiber
这年头,面试被问React diff算法有多大概率?
如果说,以前的diff 算法基本上都是 Virtual DOM -> DOM ,那现在的 diff 算法就是 Virtual DOM -> Fiber -> Fiber链表 -> DOM。
你以为面试官不会考虑时间的吗? 所以,问你 Fiber 就是在问你 diff,而你到底是回答diff呢还是Fiber呢? 还是一股脑的都说了?
这里有个小技巧。敲黑板,划重点! 请把Fiber 看作是一道算法题,而算法题首先要搞清楚的事情就是:算法要对应的数据结构。
step 1: 先介绍Fiber对象有哪些属性,其实这就是在介绍数据结构了。 请你挑最核心的属性讲。
step 2: 说清楚Fiber对象怎么来的,也就是如果构建Fiber对象。
step 3: Fiber链表如何构建。
step 4: 如何渲染真实DOM
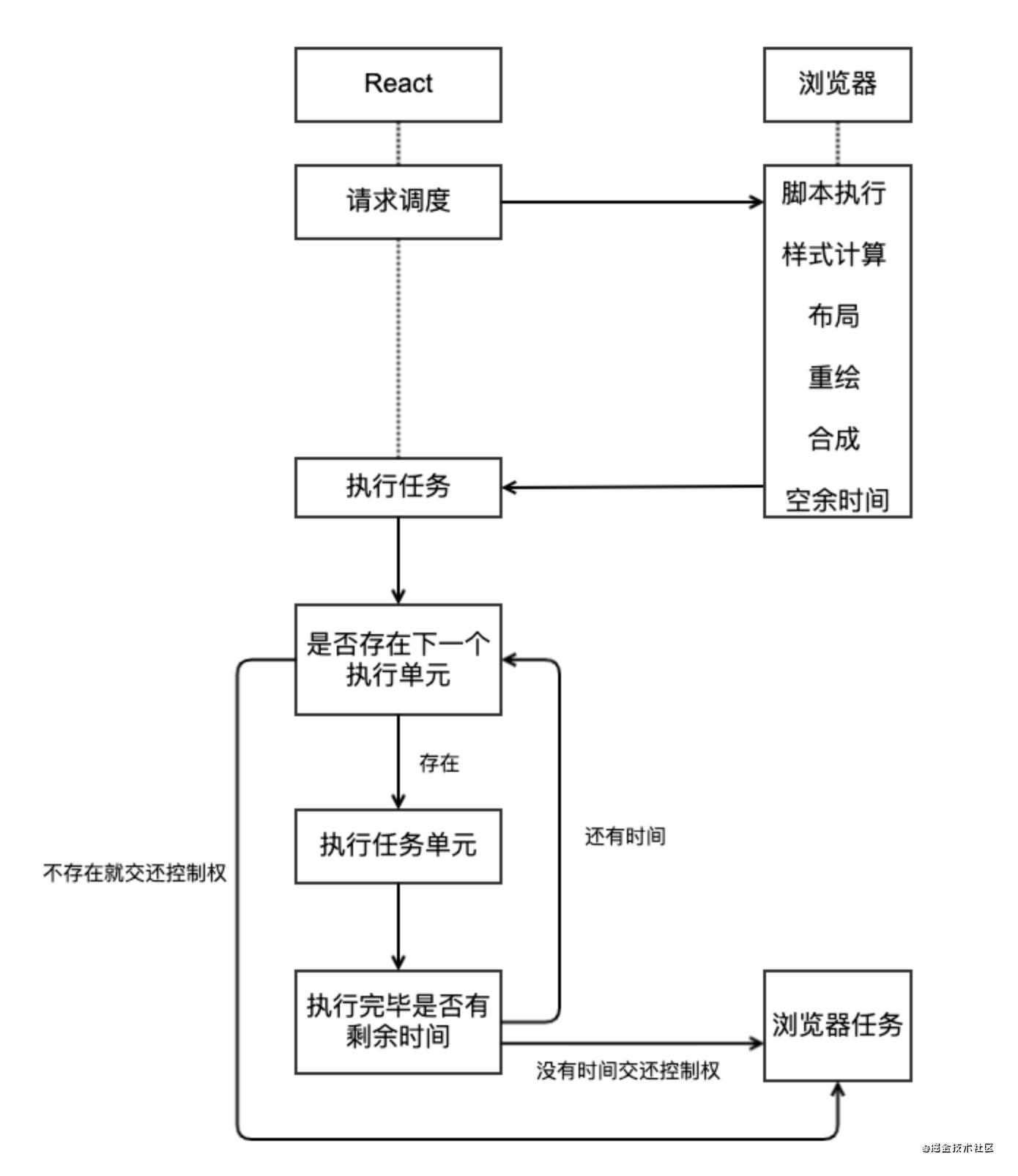
到底什么是Fiber?
Fiber 是一个执行单元
在 React 15 中,将 VirtualDOM 树整体看成一个任务进行递归处理,任务整体庞大执行耗时且不能中断。
在 React 16 中,将整个任务拆分成了一个一个小的任务进行处理,每一个小的任务指的就是一个 Fiber 节点的构建。
任务会在浏览器的空闲时间被执行,每个单元执行完成后,React 都会检查是否还有空余时间,如果有就交还主线程的控制权。
// 哦哈呦,我帮你把Fiber对象身上挂的属性尽量给你列出来了。 恐怖不? 😱 头皮发麻不
type Fiber = {
/************************ DOM 实例相关 *****************************/
// 标记不同的组件类型, 值详见 WorkTag
tag: WorkTag,
// 组件类型 div、span、组件构造函数
type: any,
// 实例对象, 如类组件的实例、原生 dom 实例, 而 function 组件没有实例, 因此该属性是空
stateNode: any,
/************************ 构建 Fiber 树相关 ***************************/
// 指向自己的父级 Fiber 对象
return: Fiber | null,
// 指向自己的第一个子级 Fiber 对象
child: Fiber | null,
// 指向自己的下一个兄弟 iber 对象
sibling: Fiber | null,
// 在 Fiber 树更新的过程中,每个 Fiber 都会有一个跟其对应的 Fiber
// 我们称他为 current <==> workInProgress
// 在渲染完成之后他们会交换位置
// alternate 指向当前 Fiber 在 workInProgress 树中的对应 Fiber
alternate: Fiber | null,
/************************ 状态数据相关 ********************************/
// 即将更新的 props
pendingProps: any,
// 旧的 props
memoizedProps: any,
// 旧的 state
memoizedState: any,
/************************ 副作用相关 ******************************/
// 该 Fiber 对应的组件产生的状态更新会存放在这个队列里面
updateQueue: UpdateQueue<any> | null,
// 用来记录当前 Fiber 要执行的 DOM 操作
effectTag: SideEffectTag,
// 存储要执行的 DOM 操作
firstEffect: Fiber | null,
// 单链表用来快速查找下一个 side effect
nextEffect: Fiber | null,
// 存储 DOM 操作完后的副租用 比如调用生命周期函数或者钩子函数的调用
lastEffect: Fiber | null,
// 任务的过期时间
expirationTime: ExpirationTime,
// 当前组件及子组件处于何种渲染模式 详见 TypeOfMode
mode: TypeOfMode,
};
好了。这篇文就暂时写到这。 不是不愿一次性写完,主要是内容真的太多。 例如上文提到的 浏览器空闲时间、 链表。 这些个准备知识也是必不可少的。
最后
为了让大家快速精通javascript,在这里免费分享给大家一份Javascript学习指南。
Javascript学习指南文档涵盖了javascript 语言核心、词法结构 、类型、值和变量 、表达式和运算符 、语句、对象 、数组 、函数 、类和模块 、 正则表达式的模式匹配、 javascript的子集和扩展 、服务器端javascript /客户端javascript 、web浏览器中的javascript 、window对象 、脚本化文档、脚本化css 、事件处理等22章知识点。内容丰富又详细,拿下互联网一线公司offfer的小伙伴都在看。
每个知识点都有左侧导航书签页,看的时候十分方便,由于内容较多,下面列举的部分内容和图片。
对象
- 创建对象
- 属性的查询和设置
- 删除属性
- 检测属性
- 枚举属性
- 属性getter和setter
- 属性的特性

数组
- 创建数组
- 数组元素的读和写
- 稀疏数组
- 数组长度
- 数组元素的添加和删除
- 数组遍历
- 多维数组

函数
- 函数定义
- 函数调用
- 函数的实参和形参
- 作为值的函数
- 作为命名空间的函数
- 闭包
- 函数属性、方法和构造函数

类和模块
- 类和原型
- 类和构造函数
- javascript中java式的类继承
- 类的扩充
- 类和类型
- javascript中的面向对象技术
- 子类

正则表达式的模式匹配
- 正则表达式的定义
- 用于模式匹配的string方法
- regexp对象

javascript的子集和扩展
- javascript的子集
- 常量和局部变量
- 解构赋值
- 迭代
- 函数简写
- 多catch 从句
- e4x: ecmascript for xml

web浏览器中的javascript
- 客户端javascript
- 在html里嵌入javascript
- javascript程序的执行
- 兼容性和互用性
- 可访问性
- 安全性
- 客户端框架

window对象
- 计时器
- 浏览器定位和导航
- 浏览历史
- 浏览器和屏幕信息
- 对话框
- 错误处理
- 作为window对象属性的文档元素
如果你有其他语言的编程经历,这份文档会有助你了解JavaScript是一门高端的、动态的、弱类型的编程语言,非常适合面向对象和函数式的编程风格。
我在这里将这份完整版的JS学习指南电子版文档提供出来,感兴趣的朋友都可以找我拿一份学习!(纯免费的一个分享,希望能给大家带来实质性的帮助)
快速入手通道:【点击这领取Javascript学习指南电子版】
你的支持,我的动力;祝各位前程似锦,offer不断!!!
以上是关于JavaScript经典面试题的专业回答的主要内容,如果未能解决你的问题,请参考以下文章