爬虫学习日志2
Posted 犬饲Atsuhiro
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习日志2相关的知识,希望对你有一定的参考价值。
1 网页采集器
网页采集器要求我们能够动态的爬取搜索页面的信息,即能够根据搜索的关键词的变化来改变爬取的页面
实现的代码
import requests
url = \'https://cn.bing.com/search?\'
#指定url
headers = {
\'User-Agent\':\'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.62\'
}
#UA伪装 2.1
keyword = input(\'请输入关键词:\')
param = {
\'q\':keyword
#\'q\'(关键词)是需要通过你所使用的搜索引擎来改变的 1.1
}
response = requests.get(url=url,params=param,headers=headers)
#发起请求
page_text = response.text
#获取响应数据
fileName = keyword + \'.html\'
with open(fileName,\'w\',encoding=\'utf-8\') as fp:
fp.write(page_text)
#持久化储存
print(\'爬取已完成\')大家可以试试,改写以上代码实现搜狗和百度等搜索引擎及其他浏览器的网页采集器
1.1 param的封装
param的封装是需要根据你的搜索引擎来改变的,例如:
使用Microsoft Bing https://cn.bing.com/search?q=吴栋剑&cvid=ed4ba36aff514bb09ca8f0a195cc4d11&aqs=edge.0.69i59j0l2j69i61l3.1923j0j1&pglt=675&FORM=ANNTA1&PC=DCTS(无效部分)
在设置url时,只需要保留https://cn.bing.com/search?(“?”可以不保留),而关键词就应该设置为第一个“=”之前的字符串\'q\'。
相应的,使用百度 https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=吴栋剑&fenlei=256&rsv_pq=edf0c8550000138a&rsv_t=f2e86C3I83ti%2FElJOg34CFV%2FfQITD3BcDBI1mK16Lr3oA9L1rINdDy1hyZQ&rqlang=cn&rsv_enter=1&rsv_dl=ib&rsv_sug3=4&rsv_sug1=4&rsv_sug7=101(无效部分)
2 UA伪装
2.1 UA是什么
UA 是“User-Agent”(用户代理)的简写,一般用来区分不同的浏览器。
2.2 什么是UA伪装
在采用爬虫访问网页时,是属于非正常访问大概率是会被拒绝的。而网页对于大多数来自浏览器的访问请求是不会拒绝的。所以我们要将自己的爬虫伪装成浏览器,来顺利的访问网页。
2.3 如何获取浏览器的 User-Agent
以Microsoft edge为例
首先右键选择“检查”选项
点击“网络”后,随意单击下列的任一选项(如果没有内容 刷新页面即可)
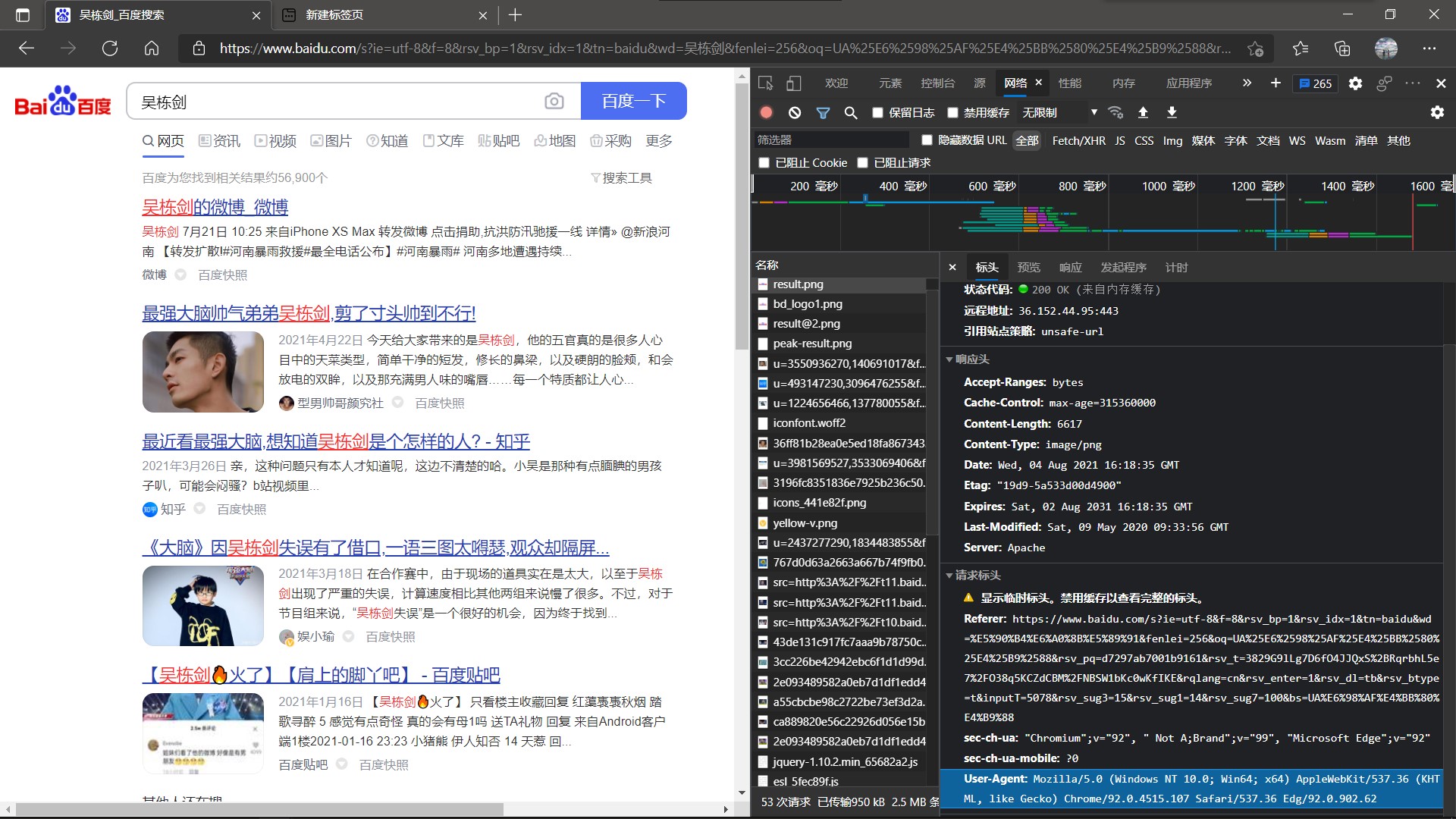
找到 User-Agent 即可
以上是关于爬虫学习日志2的主要内容,如果未能解决你的问题,请参考以下文章