java深拷贝和浅拷贝
Posted 淼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java深拷贝和浅拷贝相关的知识,希望对你有一定的参考价值。
原文:https://mp.weixin.qq.com/s/ypCIMGxyp7AX5cxG5UJ1Hg
值类型 vs 引用类型
这两个概念的准确区分,对于深、浅拷贝问题的理解非常重要。
正如Java圣经《Java编程思想》第二章的标题所言,在Java中一切都可以视为对象!
所以来到Java的世界,我们要习惯用引用去操作对象。在Java中,像数组、类Class、枚举Enum、Integer包装类等等,就是典型的引用类型,所以操作时一般来说采用的也是引用传递的方式;
但是Java的语言级基础数据类型,诸如int这些基本类型,操作时一般采取的则是值传递的方式,所以有时候也称它为值类型。
为了便于下文的讲述和举例,我们这里先定义两个类:Student和Major,分别表示「学生」以及「所学的专业」,二者是包含关系:
// 学生的所学专业 public class Major { private String majorName; // 专业名称 private long majorId; // 专业代号 // ... 其他省略 ... }
// 学生 public class Student { private String name; // 姓名 private int age; // 年龄 private Major major; // 所学专业 // ... 其他省略 ... }

赋值 vs 浅拷贝 vs 深拷贝
对象赋值
赋值是日常编程过程中最常见的操作,最简单的比如:
Student codeSheep = new Student(); Student codePig = codeSheep;
严格来说,这种不能算是对象拷贝,因为拷贝的仅仅只是引用关系,并没有生成新的实际对象:

浅拷贝
浅拷贝属于对象克隆方式的一种,重要的特性体现在这个 「浅」 字上。
比如我们试图通过studen1实例,拷贝得到student2,如果是浅拷贝这种方式,大致模型可以示意成如下所示的样子:

很明显,值类型的字段会复制一份,而引用类型的字段拷贝的仅仅是引用地址,而该引用地址指向的实际对象空间其实只有一份。
一图胜前言,我想上面这个图已经表现得很清楚了。
深拷贝
深拷贝相较于上面所示的浅拷贝,除了值类型字段会复制一份,引用类型字段所指向的对象,会在内存中也创建一个副本,就像这个样子:

原理很清楚明了,下面来看看具体的代码实现吧。
浅拷贝代码实现
还以上文的例子来讲,我想通过student1拷贝得到student2,浅拷贝的典型实现方式是:让被复制对象的类实现Cloneable接口,并重写clone()方法即可。
以上面的Student类拷贝为例:
public class Student implements Cloneable { private String name; // 姓名 private int age; // 年龄 private Major major; // 所学专业 @Override public Object clone() throws CloneNotSupportedException { return super.clone(); } // ... 其他省略 ... }
然后我们写个测试代码,一试便知:
public class Test { public static void main(String[] args) throws CloneNotSupportedException { Major m = new Major("计算机科学与技术",666666); Student student1 = new Student( "CodeSheep", 18, m ); // 由 student1 拷贝得到 student2 Student student2 = (Student) student1.clone(); System.out.println( student1 == student2 ); System.out.println( student1 ); System.out.println( student2 ); System.out.println( "\\n" ); // 修改student1的值类型字段 student1.setAge( 35 ); // 修改student1的引用类型字段 m.setMajorName( "电子信息工程" ); m.setMajorId( 888888 ); System.out.println( student1 ); System.out.println( student2 ); } }
运行得到如下结果:
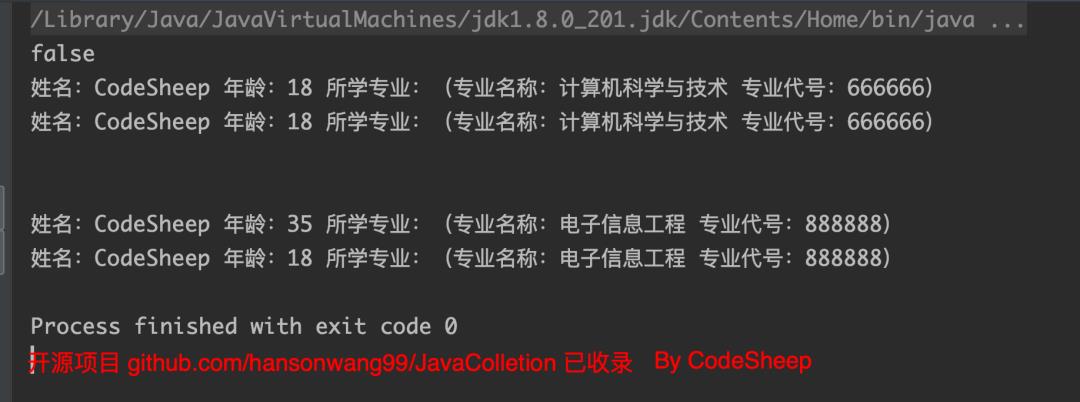
从结果可以看出:
student1==student2打印false,说明clone()方法的确克隆出了一个新对象;- 修改值类型字段并不影响克隆出来的新对象,符合预期;
- 而修改了
student1内部的引用对象,克隆对象student2也受到了波及,说明内部还是关联在一起的
深拷贝代码实现
深度遍历式拷贝
虽然clone()方法可以完成对象的拷贝工作,但是注意:clone()方法默认是浅拷贝行为,就像上面的例子一样。若想实现深拷贝需覆写 clone()方法实现引用对象的深度遍历式拷贝,进行地毯式搜索。
所以对于上面的例子,如果想实现深拷贝,首先需要对更深一层次的引用类Major做改造,让其也实现Cloneable接口并重写clone()方法:
public class Major implements Cloneable { @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } // ... 其他省略 ... }
其次我们还需要在顶层的调用类中重写clone方法,来调用引用类型字段的clone()方法实现深度拷贝,对应到本文那就是Student类:
public class Student implements Cloneable { @Override public Object clone() throws CloneNotSupportedException { Student student = (Student) super.clone(); student.major = (Major) major.clone(); // 重要!!! return student; } // ... 其他省略 ... }
这时候上面的测试用例不变,运行可得结果:
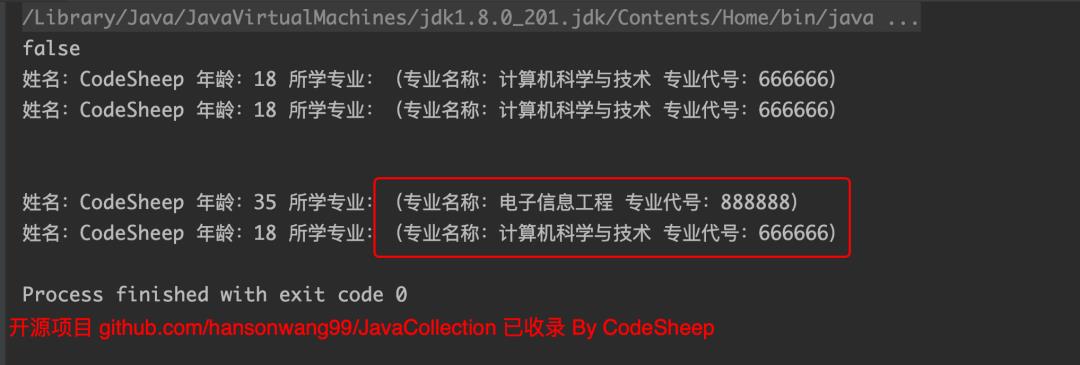
很明显,这时候student1和student2两个对象就完全独立了,不受互相的干扰。
利用反序列化实现深拷贝
利用反序列化技术,我们也可以从一个对象深拷贝出另一个复制对象,而且这货在解决多层套娃式的深拷贝问题时效果出奇的好。
所以我们这里改造一下Student类,让其clone()方法通过序列化和反序列化的方式来生成一个原对象的深拷贝副本:
public class Student implements Serializable { private String name; // 姓名 private int age; // 年龄 private Major major; // 所学专业 public Student clone() { try { // 将对象本身序列化到字节流 ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream(); ObjectOutputStream objectOutputStream = new ObjectOutputStream( byteArrayOutputStream ); objectOutputStream.writeObject( this ); // 再将字节流通过反序列化方式得到对象副本 ObjectInputStream objectInputStream = new ObjectInputStream( new ByteArrayInputStream( byteArrayOutputStream.toByteArray() ) ); return (Student) objectInputStream.readObject(); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } return null; } // ... 其他省略 ... }
当然这种情况下要求被引用的子类(比如这里的Major类)也必须是可以序列化的,即实现了Serializable接口:
public class Major implements Serializable { // ... 其他省略 ... }
这时候测试用例完全不变,直接运行,也可以得到如下结果:
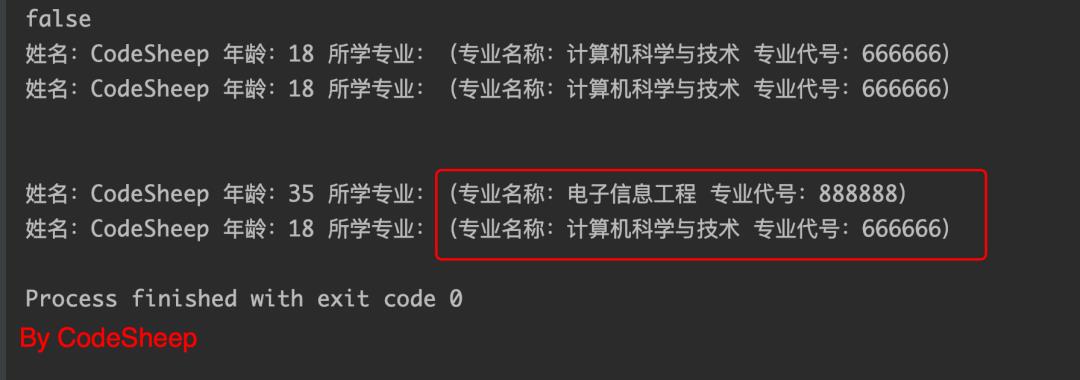
很明显,这时候student1和student2两个对象也是完全独立的,不受互相的干扰,深拷贝完成。
以上是关于java深拷贝和浅拷贝的主要内容,如果未能解决你的问题,请参考以下文章