[Python从零到壹] 十四.机器学习之分类算法五万字总结全网首发(决策树KNNSVM分类对比实验)
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python从零到壹] 十四.机器学习之分类算法五万字总结全网首发(决策树KNNSVM分类对比实验)相关的知识,希望对你有一定的参考价值。
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了聚类算法的原理知识级案例,包括K-Means聚类、BIRCH算法、PCA降维聚类、均值漂移聚类、文本聚类等。。本文将详细讲解分类算法的原理知识级案例,包括决策树、KNN、SVM,并通过详细的分类对比实验和可视化边界分析与大家总结。四万字基础文章,希望对您有所帮助。
文章目录
下载地址:
前文赏析:
第一部分 基础语法
- [Python从零到壹] 一.为什么我们要学Python及基础语法详解
- [Python从零到壹] 二.语法基础之条件语句、循环语句和函数
- [Python从零到壹] 三.语法基础之文件操作、CSV文件读写及面向对象
第二部分 网络爬虫
- [Python从零到壹] 四.网络爬虫之入门基础及正则表达式抓取博客案例
- [Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
- [Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP250电影详解
- [Python从零到壹] 七.网络爬虫之Requests爬取豆瓣电影TOP250及CSV存储
- [Python从零到壹] 八.数据库之MySQL基础知识及操作万字详解
- [Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解(定位元素、常用方法、键盘鼠标操作)
- [Python从零到壹] 十.网络爬虫之Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)
第三部分 数据分析和机器学习
- [Python从零到壹] 十一.数据分析之Numpy、Pandas、Matplotlib和Sklearn入门知识万字详解(1)
- [Python从零到壹] 十二.机器学习之回归分析万字总结全网首发(线性回归、多项式回归、逻辑回归)
- [Python从零到壹] 十三.机器学习之聚类分析万字总结全网首发(K-Means、BIRCH、层次聚类、树状聚类)
- [Python从零到壹] 十四.机器学习之分类算法三万字总结全网首发(决策树、KNN、SVM、分类算法对比)
作者新开的“娜璋AI安全之家”将专注于Python和安全技术,主要分享Web渗透、系统安全、人工智能、大数据分析、图像识别、恶意代码检测、CVE复现、威胁情报分析等文章。虽然作者是一名技术小白,但会保证每一篇文章都会很用心地撰写,希望这些基础性文章对你有所帮助,在Python和安全路上与大家一起进步。
分类(Classification)属于有监督学习(Supervised Learning)中的一类,它是数据挖掘、机器学习和数据科学中一个重要的研究领域。分类模型类似于人类学习的方式,通过对历史数据或训练集的学习得到一个目标函数,再用该目标函数预测新数据集的未知属性。本章主要讲述分类算法基础概念,并结合决策树、KNN、SVM分类算法案例分析各类数据集,从而让读者学会使用Python分类算法分析自己的数据集,研究自己领域的知识,从而创造价值。
一.分类
1.分类模型
与前面讲述的聚类模型类似,分类算法的模型如图1所示。它主要包括两个步骤:
- 训练。给定一个数据集,每个样本包含一组特征和一个类别信息,然后调用分类算法训练分类模型。
- 预测。利用生成的模型或函数对新的数据集(测试集)进行分类预测,并判断其分类后的结果,并进行可视化绘图显示。
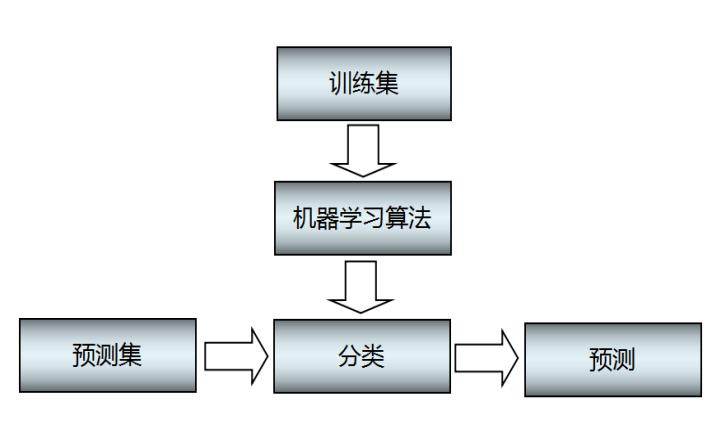
通常为了检验学习模型的性能,会使用校验集。数据集会被分成不相交的训练集和测试集,训练集用来构造分类模型,测试集用来检验多少类标签被正确分类。
下面举一个分类实例进行讲解。假设存在一个垃圾分类系统,将邮件划分为“垃圾邮件”和“非垃圾邮件”,现在有一个带有是否是垃圾邮件类标的训练集,然后训练一个分类模型,对测试集进行预测,步骤如下:
- (1) 分类模型对训练集进行训练,判断每行数据是正向数据还是负向数据,并不断与真实的结果进行比较,反复训练模型,直到模型达到某个状态或超出某个阈值,模型训练结束。
- (2) 利用该模型对测试集进行预测,判断其类标是“垃圾邮件”还是“非垃圾邮件”,并计算出该分类模型的准确率、召回率和F特征值。
经过上述步骤,当收到一封新邮件时,我们可以根据它邮件的内容或特征,判断其是否是垃圾邮件,这为我们提供了很大的便利,能够防止垃圾邮件信息的骚扰。
2.常见分类算法
监督式学习包括分类和回归。其中常见的分类算法包括朴素贝叶斯分类器、决策树、K最近邻分类算法、支持向量机、神经网络和基于规则的分类算法等,同时还有用于组合单一类方法的集成学习算法,如Bagging和Boosting等。
(1) 朴素贝叶斯分类器
朴素贝叶斯分类器(Naive Bayes Classifier,简称NBC)发源于古典数学理论,有着坚实的数学基础和稳定的分类效率。该算法是利用Bayes定理来预测一个未知类别的样本属于各个类别的可能性,选择其中可能性最大的一个类别作为该样本的最终类别。其中,朴素贝叶斯(Naive Bayes)法是基于贝叶斯定理与特征条件独立假设的方法 ,是一类利用概率统计知识进行分类的算法,该算法被广泛应用的模型称为朴素贝叶斯模型(Naive Bayesian Model,简称NBM)。
根据贝叶斯定理,对于一个分类问题,给定样本特征x,样本属于类别y的概率如下:
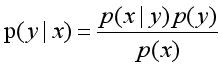
其中p(x)表示x事件发生的概率,p(y)表示y事件发生的概率,p(x|y)表示事件y发生后事件x发生的概率。由于贝叶斯定理的成立本身需要一个很强的条件独立性假设前提,而此假设在实际情况中经常是不成立的,因而其分类准确性就会下降,同时它对缺失的数据不太敏感。本书没有详细介绍朴素贝叶斯分类实例,希望读者下来自行研究学习。
(2) 决策树算法
决策树(Decision Tree)是以实例为基础的归纳学习(Inductive Learning)算法,它是对一组无次序、无规则的实例建立一棵决策判断树,并推理出树形结果的分类规则。决策树作为分类和预测的主要技术之一,其构造目的是找出属性和类别间的关系,用它来预测未知数据的类别。该算法采用自顶向下的递归方式,在决策树的内部节点进行属性比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶子节点得到反馈的结果。
决策树算法根据数据的属性采用树状结构建立决策模型,常用来解决分类和回归问题。常见的算法包括:分类及回归树、ID3 、C4.5、随机森林等。
(3) K最近邻分类算法
K最近邻(K-Nearest Neighbor,简称KNN)分类算法是一种基于实例的分类方法,是数据挖掘分类技术中最简单常用的方法之一。所谓K最近邻,就是寻找K个最近的邻居,每个样本都可以用它最接近的K个邻居来代表。该方法需要找出与未知样本X距离最近的K个训练样本,看这K个样本中属于哪一类的数量多,就把未知样本X归为那一类。
K-近邻方法是一种懒惰学习方法,它存放样本,直到需要分类时才进行分类,如果样本集比较复杂,可能会导致很大的计算开销,因此无法应用到实时性很强的场合。
(4) 支持向量机
支持向量机(Support Vector Machine,简称SVM)是数学家Vapnik等人根据统计学习理论提出的一种新的学习方法,其基本模型定义为特征空间上间隔最大的线性分类器,其学习策略是间隔最大化,最终转换为一个凸二次规划问题的求解。
SVM算法的最大特点是根据结构风险最小化准则,以最大化分类间隔构造最优分类超平面来提高学习机的泛化能力,较好地解决了非线性、高维数、局部极小点等问题,同时维数大于样本数时仍然有效,支持不同的内核函数(线性、多项式、s型等)。
(5) 神经网络
神经网络(Neural Network,也称之为人工神经网络)算法是80年代机器学习界非常流行的算法,不过在90年代中途衰落。现在又随着“深度学习”之势重新火热,成为最强大的机器学习算法之一。图2是一个神经网络的例子,包括输入层、隐藏层和输出层。
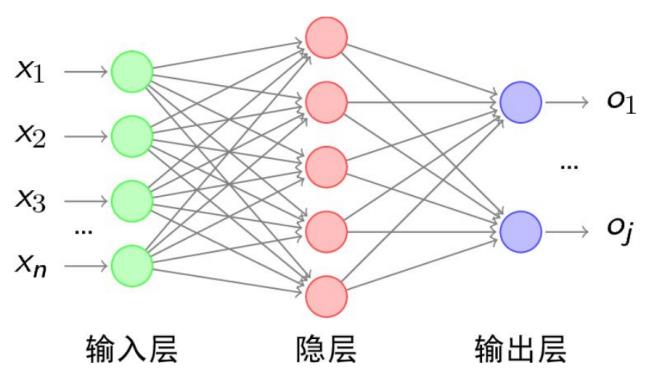
人工神经网络(Artificial Neural Network,简称ANN)是一种模仿生物神经网络的结构和功能的数学模型或计算模型。在这种模型中,大量的节点或称“神经元”之间相互联接构成网络,即“神经网络”,以达到处理信息的目的。神经网络通常需要进行训练,训练的过程就是网络进行学习的过程,训练改变了网络节点的连接权的值使其具有分类的功能,经过训练的网络就可用于对象的识别。
常见的人工神经网络有BP(Back Propagation)神经网络、径向基RBF神经网络、Hopfield神经网络、随机神经网络(Boltzmann机)、深度神经网络DNN、卷积神经网络CNN等。
(6) 集成学习
集成学习(Ensemble Learning)是一种机器学习方法,它使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果。由于实际应用的复杂性和数据的多样性往往使得单一的分类方法不够有效,因此,学者们对多种分类方法的融合即集成学习进行了广泛的研究,它已俨然成为了国际机器学习界的研究热点。
集成学习试图通过连续调用单个的学习算法,获得不同的基学习器,然后根据规则组合这些学习器来解决同一个问题,可以显著的提高学习系统的泛化能力。组合多个基学习器主要采用投票(加权)的方法,常见的算法有装袋(Bagging)、推进(Boosting)等。
3.回归、聚类和分类的区别
在第12篇文章中我们详细讲解了回归分析,13篇详细讲解了聚类分析,本章着重讲解分类分析,而它们之间究竟存在什么区别和关系呢?
- 分类(Classification)和回归(Regression)都属于监督学习,它们的区别在于:回归是用来预测连续的实数值,比如给定了房屋面积,来预测房屋价格,返回的结果是房屋价格;而分类是用来预测有限的离散值,比如判断一个人是否患糖尿病,返回值是“是”或“否”。即明确对象属于哪个预定义的目标类,预定义的目标类是离散时为分类,连续时为回归。
- 分类属于监督学习,而聚类属于无监督学习,其主要区别是:训练过程中是否知道结果或是否存在类标。比如让小孩给水果分类,给他苹果时告诉他这是苹果,给他桃子时告诉他这是桃子,经过反复训练学习,现在给他一个新的水果,问他“这是什么?”,小孩对其进行回答判断,整个过程就是一个分类学习的过程,在训练小孩的过程中反复告诉他对应水果真实的类别。而如果采用聚类算法对其进行分析,则是给小孩一堆水果,包括苹果、橘子、桃子,小孩开始不知道需要分类的水果是什么,让小孩自己对水果进行分类,按照水果自身的特征进行归纳和判断,小孩分成三堆后,再给小孩新的水果,比如是苹果,小孩把它放到苹果堆的整个过程称之为聚类学习过程。
总之,分类学习在训练过程中是知道对应的类标结果的,即训练集是存在对应的类标的;而聚类学习在训练过程中不知道数据对应的结果,根据数据集的特征特点,按照“物以类聚”的方法,将具有相似属性的数据聚集在一起。
4.性能评估
分类算法有很多,不同的分类算法又有很多不同的变种,不同的分类算法有不同的特点,在不同的数据集上表现的效果也不同,我们需要根据特定的任务来选择对应的算法。选择好了分类算法之后,我们如何评价一个分类算法的好坏呢?
本书主要采用精确率(Precision)、召回率(Recall)和F值(F-measure或F-score)来评价分类算法。
(1) 精确率(Precision)和召回率(Recall)
精确率定义为检索出相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率定义为检索出的相关文档数和文档库中所有相关文档数的比率,衡量的是检索系统的查全率。公式如下:
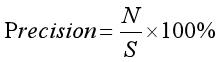
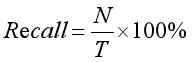
其中,参数N表示实验结果中正确识别出的聚类类簇数,S表示实验结果中实际识别出的聚类类簇数,T表示数据集中所有真实存在的聚类相关类簇数。
(2) F值(F-measure或F-score)
精确率和召回率两个评估指标在特定的情况下是相互制约的,因而很难使用单一的评价指标来衡量实验的效果。F-值是准确率和召回率的调和平均值,它可作为衡量实验结果的最终评价指标,F值更接近两个数中较小的那个。F值指的计算公式如下公式所示:
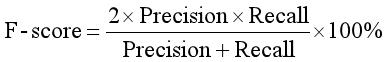
(3) 其他指标
其他常用的分类算法的评价指标包括:
- 准确率(Accuracy)
- 错误率(Error Rate)
- 灵敏度(Sensitive)
- 特效度(Specificity)
- ROC曲线
- …
二.决策树
1.算法实例描述
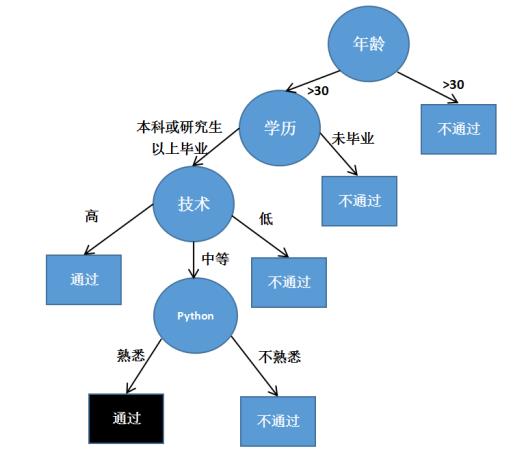
下面通过一个招聘的案例讲述决策树的基本原理及过程。假设一位程序员与面试官的初次面试的简单对话,我们利用决策树分类的思想来构建一棵树形结构。对话如下:
面试官:多大年纪了?
程序员:25岁。
面试官:本科是不是已经毕业呢?
程序员:是的。
面试官:编程技术厉不厉害?
程序员:不算太厉害,中等水平。
面试官:熟悉Python语言吗?
程序员:熟悉的,做过数据挖掘相关应用。
面试官:可以的,你通过了。
这个面试的决策过程就是典型的分类树决策。相当于通过年龄、学历、编程技术和是否熟悉Python语言将程序员初试分为两个类别:通过和不通过。假设这个面试官对程序员的要求是30岁以下、学历本科以上并且是编程厉害或熟悉Pyhon语言中等以上编程技术的程序员,这个面试官的决策逻辑过程用图3表示。
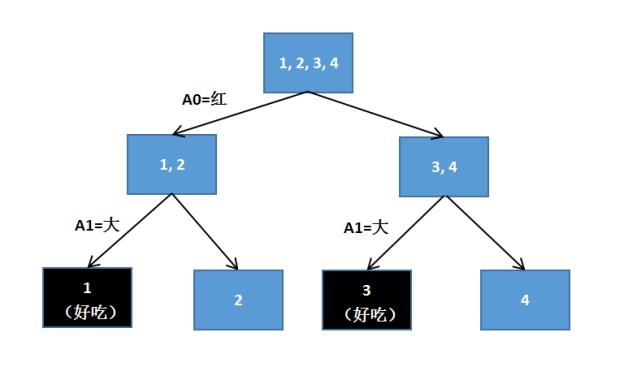
第二个实例是典型的决策树判断苹果的例子,假设存在4个样本,2个属性判断是否是好苹果,其中第二列1表示苹果很红,0表示苹果不红;第三列1表示苹果很大,0表示苹果很小;第4列结果1表示苹果好吃,0表示苹果不好吃。
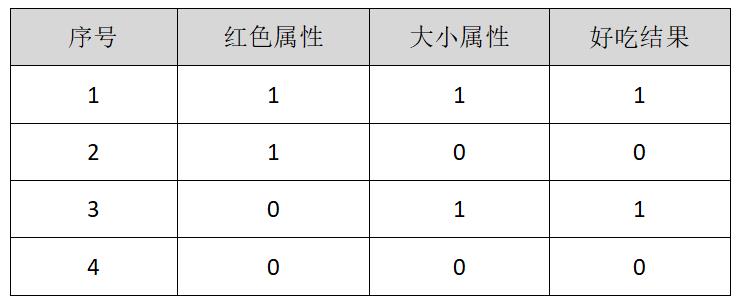
样本中有2个属性,即苹果红色属性和苹果大小属性。这里红苹果用A0表示,大苹果用A1表示,构建的决策树如图19.4所示。图中最顶端有四个苹果(1、2、3、4),然后它将颜色红的苹果放在一边(A0=红),颜色不红的苹果放在另一边,其结果为1、2是红苹果,3、4是不红的苹果;再根据苹果的大小进行划分,将大的苹果判断为好吃的(A1=大),最终输出结果在图中第三层显示,其中1和3是好吃的苹果,2和4是不好吃的苹果,该实例表明苹果越大越好吃。
决策树算法根据数据的属性并采用树状结构构建决策模型,常用来解决分类和回归问题。常见的决策树算法包括:
- 分类及回归树(Classification And Regression Tree,简称CART)
- ID3算法(Iterative Dichotomiser 3)
- C4.5算法
- 随机森林算法(Random Forest)
- 梯度推进机算法(Gradient Boosting Machine,简称GBM)
决策树构建的基本步骤包括4步,具体步骤如下:
- 第一步:开始时将所有记录看作一个节点。
- 第二步:遍历每个变量的每一种分割方式,找到最好的分割点。
- 第三步:分割成两个节点N1和N2。
- 第四步:对N1和N2分别继续执行第二步和第三步,直到每个节点足够“纯”为止。
决策数具有两个优点:
- 模型可以读性好,描述性强,有助于人工分析。
- 效率高,决策树只需要一次构建,可以被反复使用,每一次预测的最大计算次数不超过决策树的深度。
2.DTC算法
Sklearn机器学习包中,实现决策树(DecisionTreeClassifier,简称DTC)的类是:
- sklearn.tree.DecisionTreeClassifier
它能够解决数据集的多类分类问题,输入参数为两个数组X[n_samples,n_features]和y[n_samples],X为训练数据,y为训练数据标记值。DecisionTreeClassifier构造方法为:
sklearn.tree.DecisionTreeClassifier(criterion='gini'
, splitter='best'
, max_depth=None
, min_samples_split=2
, min_samples_leaf=1
, max_features=None
, random_state=None
, min_density=None
, compute_importances=None
, max_leaf_nodes=None)
DecisionTreeClassifier类主要包括两个方法:
- clf.fit(train_data, train_target)
用来装载(train_data,train_target)训练数据,并训练分类模型。 - pre = clf.predict(test_data)
用训练得到的决策树模型对test_data测试集进行预测分析。
3.决策树分析鸢尾花
前面第12篇文章介绍过逻辑回归分析鸢尾花的实例,这里再次讲解决策树分析鸢尾花实例,从而加深读者印象。
(1) 数据集回顾
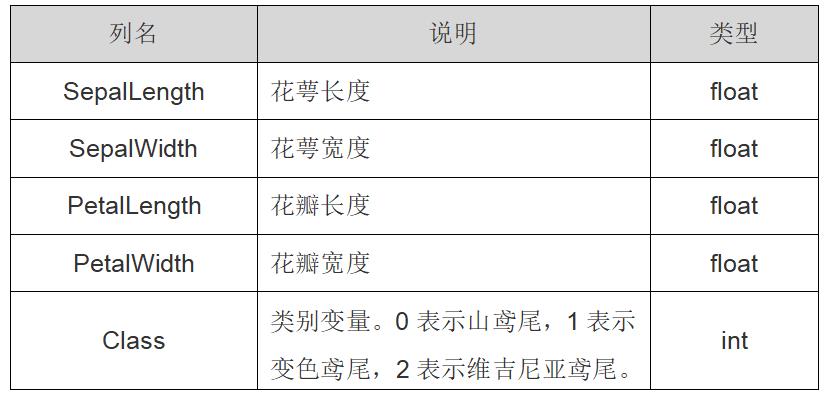
在Sklearn机器学习包中,集成了各种各样的数据集,包括糖尿病数据集、鸢尾花数据集、新闻数据集等。这里使用的是鸢尾花卉Iris数据集,它是一个很常用的数据集,共150行数据,包括四个特征变量:
- 萼片长度
- 萼片宽度
- 花瓣长度
- 花瓣宽度。
同时包括一个类别变量,将鸢尾花划分为三个类别,即:
- 山鸢尾(Iris-setosa)
- 变色鸢尾(Iris-versicolor)
- 维吉尼亚鸢尾(Iris-virginica)
表2为鸢尾花数据集,详细信息如下表所示。
iris是鸢尾植物,这里存储了其萼片和花瓣的长宽,共4个属性,鸢尾植物分三类。 iris数据集中包括两个属性iris.data和iris.target。其中,data数据是一个矩阵,每一列代表了萼片或花瓣的长宽,一共4列,每一行数据代表某个被测量的鸢尾植物,一共采样了150条记录。载入鸢尾花数据集代码如下所示:
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data)
print(iris.target)

(2) 决策树简单分析鸢尾花
下述代码实现了调用Sklearn机器学习包中DecisionTreeClassifier决策树算法进行分类分析,并绘制预测的散点图。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-06
#导入数据集iris
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data) #输出数据集
print(iris.target) #输出真实标签
print(len(iris.target))
print(iris.data.shape) #150个样本 每个样本4个特征
#导入决策树DTC包
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(iris.data, iris.target) #训练
print(clf)
predicted = clf.predict(iris.data) #预测
#获取花卉两列数据集
X = iris.data
L1 = [x[0] for x in X]
L2 = [x[1] for x in X]
#绘图
import numpy as np
import matplotlib.pyplot as plt
plt.scatter(L1, L2, c=predicted, marker='x') #cmap=plt.cm.Paired
plt.title("DTC")
plt.show()
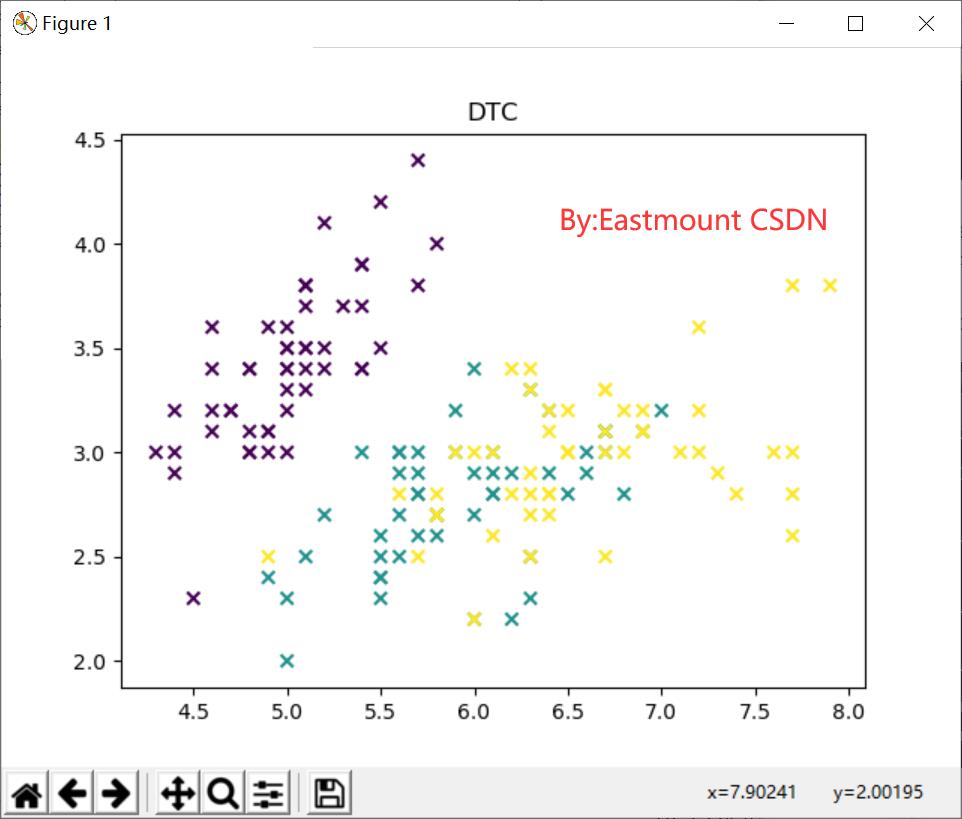
输出结果如图5所示,可以看到决策树算法将数据集预测为三类,分别代表着数据集对应的三种鸢尾花,但数据集中存在小部分交叉结果。预测的结果如下:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
150
(150, 4)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
下面对上述核心代码进行简单描述。
- from sklearn.datasets import load_iris
- iris = load_iris()
该部分代码是导入sklearn机器学习包自带的鸢尾花数据集,调用load_iris()函数导入数据,数据共分为数据(data)和类标(target)两部分。
- from sklearn.tree import DecisionTreeClassifier
- clf = DecisionTreeClassifier()
- clf.fit(iris.data, iris.target)
- predicted = clf.predict(iris.data)
该部分代码导入决策树模型,并调用fit()函数进行训练,predict()函数进行预测。
- import matplotlib.pyplot as plt
- plt.scatter(L1, L2, c=predicted, marker=‘x’)
该部分代码是导入matplotlib绘图扩展包,调用scatter()函数绘制散点图。
但上面的代码中存在两个问题:
- 代码中通过“L1 = [x[0] for x in X]”获取了第一列和第二列数据集进行了分类分析和绘图,而真实的iris数据集中包括四个特征,那怎么绘制四个特征的图形呢? 这就需要利用PCA降维技术处理,参考前一篇文章。
- 第二个问题是在聚类、回归、分类模型中,都需要先进行训练,再对新的数据集进行预测,这里却是对整个数据集进行分类分析,而真实情况是需要把数据集划分为训练集和测试集的,例如数据集的70%用于训练、30%用于预测,或80%用于训练、20%用于预测。
4.数据集划分及分类评估
这部分内容主要是进行代码优化,将数据集划分为80%训练集-20%预测集,并对决策树分类算法进行评估。由于提供的数据集类标是存在一定规律的,前50个类标为0(山鸢尾)、中间50个类标为1(变色鸢尾)、最后50个类标为2(维吉尼亚鸢)。即:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
这里调用NumPy库中的 concatenate() 函数对数据集进行挑选集成,选择第0-40行、第50-90行、第100-140行数据作为训练集,对应的类标作为训练样本类标;再选择第40-50行、第90-100行、第140-150行数据作为测试集合,对应的样本类标作为预测类标。
代码如下,“axis=0”表示选取数值的等差间隔为0,即紧挨着获取数值。
#训练集
train_data = np.concatenate((iris.data[0:40, :], iris.data[50:90, :], iris.data[100:140, :]), axis = 0)
#训练集样本类别
train_target = np.concatenate((iris.target[0:40], iris.target[50:90], iris.target[100:140]), axis = 0)
#测试集
test_data = np.concatenate((iris.data[40:50, :], iris.data[90:100, :], iris.data[140:150, :]), axis = 0)
#测试集样本类别
test_target = np.concatenate((iris.target[40:50], iris.target[90:100], iris.target[140:150]), axis = 0)
同时,调用sklearn机器学习包中metrics类对决策树分类算法进行评估,它将输出准确率(Precison)、召回率(Recall)、F特征值(F-score)、支持度(Support)等。
#输出准确率 召回率 F值
from sklearn import metrics
print(metrics.classification_report(test_target, predict_target))
print(metrics.confusion_matrix(test_target, predict_target))
分类报告的核心函数为:
sklearn.metrics.classification_report(y_true,
y_pred,
labels=None,
target_names=None,
sample_weight=None,
digits=2)
其中y_true参数表示正确的分类类标,y_pred表示分类预测的类标,labels表示分类报告中显示的类标签的索引列表,target_names参数显示与labels对应的名称,digits是指定输出格式的精确度。评价公式如下:
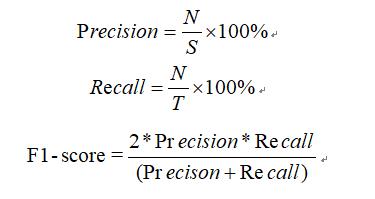
调用 metrics.classification_report() 方法对决策树算法进行评估后,会在最后一行将对所有指标进行加权平均值,详见下面完整代码。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2021-07-06
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
import numpy as np
import matplotlib.pyplot as plt
#导入数据集iris
'''
重点:分割数据集 构造训练集/测试集,80/20
70%训练 0-40 50-90 100-140
30%预测 40-50 90-100 140-150
'''
iris = load_iris()
train_data = np.concatenate((iris.data[0:40, :], iris.data[50:90, :], iris.data[100:140, :]), axis = 0) #训练集
train_target = np.concatenate((iris.target[0:40], iris.target[50:90], iris.target[100:140]), axis = 0) #训练集样本类别
test_data = np.concatenate((iris.data[40:50, :], iris.data[90:100, :], iris.data[140:150, :]), axis = 0[Python从零到壹] 十二.机器学习之回归分析万字总结全网首发(线性回归多项式回归逻辑回归)
[Python从零到壹] 四十四.图像增强及运算篇之图像灰度线性变换详解
[Python从零到壹] 五十四.图像增强及运算篇之局部直方图均衡化和自动色彩均衡化处理
[Python从零到壹] 五十四.图像增强及运算篇之局部直方图均衡化和自动色彩均衡化处理