机器学习实践:了解数据核心的通用方法!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习实践:了解数据核心的通用方法!相关的知识,希望对你有一定的参考价值。
↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale干货
作者:耿远昊,华东师范大学,Datawhale成员
我们常说数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。
机器学习中的数据繁多复杂,我们很容易迷失在无尽的具体数据中,迅速抓住数据集的核心与重点。因此,需要一套高效且能够广泛应用于绝大多数数据的认知方法,快速建立对未知数据模式的有效观察。
这里讲述最常用的结构化数据,按照数据的类型、分布和统计量三个角度来阐述数据观测的策略。

数据类型
现实生活中的数据类型多种多样,我们能够通过某些先验的划分将数据集的特征分类,这是后续数据处理的基础。主要分为以下两类:
原生类型
原生表示数据本身的类型,与数据含义无关。
与数据含义无关就是指我们在此并不关心数据的业务场景。例如:一个数据集中可能出现了两个字符串特征分别代表城市名与人员的身份编码,我们只需统一将其视作字符串特征。
常见的类型包括缺失类型、文本类型、分类类型以及时序类型,数据的原生类型决定了对数据的初步处理方式。
对于缺失数据,我们可以计算缺失值的比例和数量。
对于文本类型,可以利用预训练的语言模型将其映射到给定维数的特征向量,或者根据给定文本的特点来提取一些特征模式(如重复性、唯一性、某些模式的存在性等)。
对于分类类型,我们可以观察类别的均衡度、种数、比例、高频项与低频项分布特点等。
对于时序类型,我们需要观察时间戳的连续性、范围、采样频率、采样特点(如均匀性、是否按固定时间模式采样等)。
总体来说,我们在拿到数据集后应当首先判断数据的原生类型,并基于类别进行基本的特征观察。
业务类型
业务类型由数据特征代表的含义与特征所属的业务类别决定。
业务类型可分为同质特征、同类特征以及异类特征。
同质特征是指原生类型相同且数据含义相似的特征,例如某个商品的近1周销售额、近1月销售额、近3月销售额这3个特征,它们就属于同质特征,对这些特征往往可以进行有意义的简单交叉组合。
同类特征是指数据含义直接相关的特征,例如现有用户购买商品的数据集,那么用户的身高、年龄性别之间就属于同类特征,它们都是用户的属性,而商品的ID、历史销量和价格也属于同类特征,它们都是商品的属性。
相对的,异类特征为数据含义并不直接相关的特征,例如商品ID和用户性别。
业务类型的判断有利于使我们快速建立对特征含义的宏观认识,这是我们后续构造有效特征的基础。
数据统计量
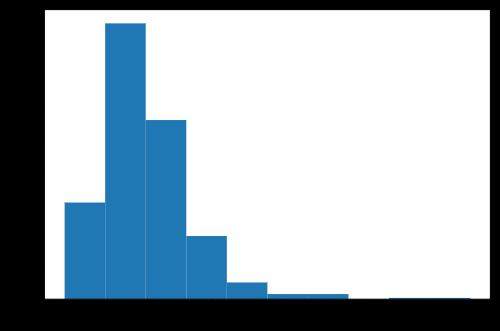
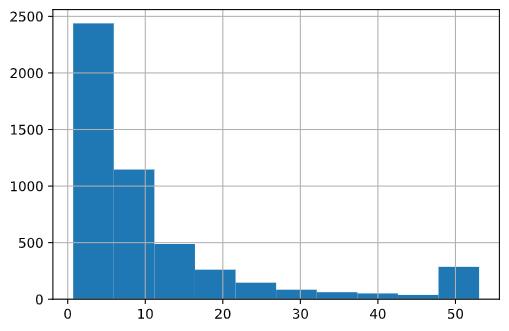
这里用一个数据举例:假设现在存有一个特征列var,其数据分布图如下。
plt.hist(var)
范围型统计量
范围型的统计量包括极差、分位数、排名。因此,也可以基于极值出现的位置构造其他相应统计量。
其中,极差和分位数分别反应了绝对范围和大致范围:
# 取极值和分位数
var.max()-var.min(), np.quantile(var, 0.95)-np.quantile(var, 0.05)
对于时序数据而言,一段时间内的波动情况的极值,可以认为是该段时间内数据的极差:
# 查看极值的波动情况
ts = pd.Series(
var,
index=pd.date_range(
"20200101",
periods=500,
freq="6h"
)
)
ts.plot()
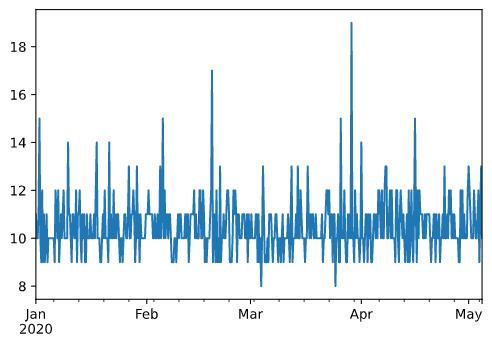
同时,我们还应当关注取到极值的时刻:
# 查看何时会出现极值
ts.index[ts.argmax()], ts.index[ts.argmin()]
需要注意的是,极值出现的时刻可能不唯一:
# 出现多个极值的时刻
ts.index[ts==ts[ts.argmax()]], ts.index[ts==ts[ts.argmin()]]
频率型统计量
频率型统计量包括高频项频数、唯一值、符合某些条件的样本频数。其中,符合某些条件可以指某一个特征是否超过给定阈值或其他布尔条件等。
高频项指多次重复出现的数据,它的出现次数(项数)可通过value_counts获得;唯一值可以通过unique获得:
#高频项项数
var = pd.Series(var)
var.value_counts()
#只出现一次的数据
var.unique()
假设想把0.2与0.8分位数之外的值设为缺失值,可如下写:
var_temp = var.copy()
var_temp[(var<var.quantile(0.2))|(var>var.quantile(0.8))] = np.nan
var_temp.unique()
矩统计量
矩特征包括了常见的均值、方差、偏度、峰度。其中,偏度和峰度分别反应了数据分布单尾和双尾的薄厚程度,它们的计算方法分别为:
当偏度系数为0时,样本分布具有较好的对称性;若偏度系数大于零,此时称分布为正偏或右偏,此时样本的右尾较厚,均值(即密度重心)相较于众数(密度最值)更大,var变量所示的分布即为右偏分布:
var.skew()
如果偏度系数小于零,意味着左尾较厚,此时均值(即密度重心)相较于众数(密度最值)更小,称为左偏分布或负偏分布:
(-var).hist()
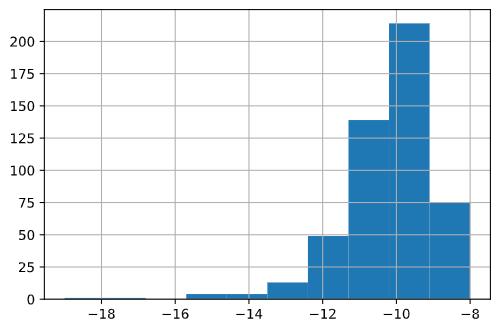
(-var).skew()
对于峰度系数而言,可以证明其值不会小于1。
对于在无穷区间(即随机变量 且 和 中至少有一个为无穷值)上取值的密度,峰度系数越大,意味着分布的尾部越厚,这是由密度积分为1的限制所决定的。
数据分布
单变量分布
在现实生活中,我们经常会接触到分布不均衡的变量,例如每个家庭的年收入、艺术品市场的拍卖价格等等。
在读取变量后,做出直方图经常会遇到如下的情况:
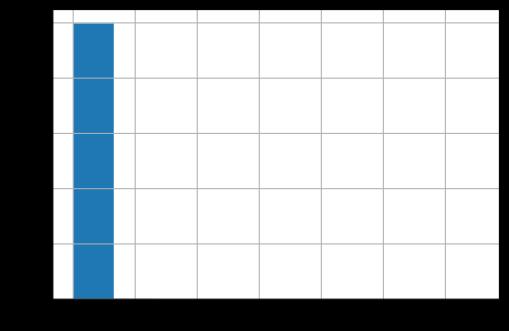
此时,一个有用的技巧是利用clip函数按照分位数进行截断:
a = a.clip(a.min(), a.quantile(0.95))
a.hist()
多变量分布
在机器学习中,我们特别关心测试集和训练集关于标签变量的这两种分布,当两者分布强烈不一致时,此时模型会学习到错误的模式,从而发生误判。
假设当前处理的是二分类问题,我们分别需要观察其与离散分布或连续分布的条件分布。
:tags: [remove_input]
df_train = pd.DataFrame(
{
"X1": np.random.choice(
["a", "b", "c", "d"],
size=1000
),
"X2": np.random.randint(0, 7, 1000),
"Y": np.random.choice([0, 1], size=1000, p=[0.1, 0.9])
}
)
df_test = pd.DataFrame(
{
"X1": np.random.choice(
["a", "b", "c", "d"],
size=1000,
p=[0.1,0.5,0.1,0.3]
),
"X2": np.random.randint(3, 10, 1000),
"Y": np.random.choice([0, 1], 1000, p=[0.2, 0.8])
}
)
df_train.head()
df_test.head()
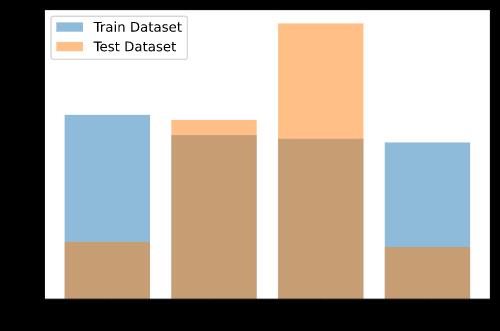
(a)与离散分布的条件分布
以给定 的条件分布为例:
vc_train = df_train.query("Y==1").X1.value_counts()
vc_test = df_test.query("Y==1").X1.value_counts()
plt.bar(
vc_train.index,
vc_train.values,
alpha=0.5,
label='Train Dataset'
)
plt.bar(
vc_test.index,
vc_test.values,
alpha=0.5,
label='Test Dataset'
)
plt.legend()
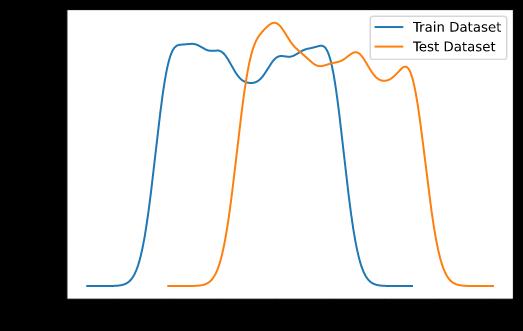
(b)与连续分布的条件分布
以给定 的条件分布为例:
df_train.query("Y==1").X2.plot.kde(label='Train Dataset')
df_test.query("Y==1").X2.plot.kde(label='Test Dataset')
plt.legend()
相同地,我们可以观察以某个特征为给定条件下的其他特征或目标变量的分布,方法类似。
异常识别
异常模式的识别与处理是一个非常复杂的活儿,幸好统计学中早有相关研究。统计学中的假设检验,本质上就是一种异常处理,而 值则对应了对于异常的容忍度。
方法是一类最为基本的异常处理检测机制,在一个数据分布中,处于均值加减三倍标准差之外的点,可以认为其是异常数据点。
var[
(
var>(var.mean()+var.std()*3)
)|(
var<(var.mean()-var.std()*3)
)
]
上面被选出的这些点,从分布图上而言,确实脱离了大多数的数据,但同时我们需要注意,异常也是一种数据模式,不能够无根据地对这些数据进行修改操作。
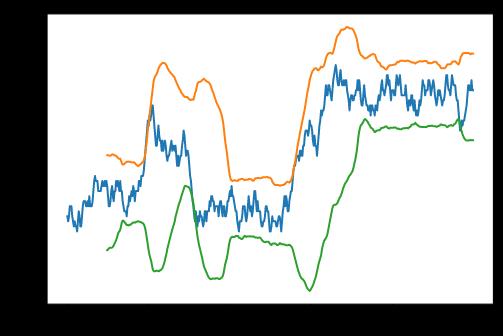
对于时序中的异常数据,我们可以使用滑窗版本的 方法进行识别。下图中,我们可以看见对于几个较为明显的序列下转或上转区,都基本与使用滑窗方法的检验上下界发生了触碰:
np.random.seed(6)
s = np.random.randint(-2,3, 500).cumsum()
s = pd.Series(s)
s.plot()
n = 50
(s.rolling(n).mean()+3*s.rolling(n).std()).plot()
(s.rolling(n).mean()-3*s.rolling(n).std()).plot()
对于常见的异常检测问题,可以选择第三方库,如scikit-learn中的Novelty and Outlier Detection模块,基于规则与无监督方法的ADTK时序异常检测包等等。
练习一下
公众号后台回复关键词【数据练习】,获取练习数据集
1. 美国环境污染数据分析
现有一份有关2000年至2016年的美国环境污染数据集,请利用本文中介绍的数据观测思路对其进行初步分析。
df = pd.read_csv("data/ex-ch11-3-pollution.csv")
df.head()
2. pandas-profiling的使用
pandas-profiling是一个基于DataFrame的数据信息整合库,它能够高效地对数据集的核心重要指标进行计算汇总。设待观测的数据框为df,通过如下命令可以保存数据分析汇总的结果到html格式:
from pandas_profiling import ProfileReport
profile = ProfileReport(
df,
title="My DataFrame Report",
# 当数据集较大计算时间较长时,可以开启精简模式,只计算最重要的指标
# minimal=True,
)
profile.to_file("my_report.html")
现有一份有关印度洋版块地震记录的数据集,请利用pandas-profiling生成html报告,并观察报告中所包含的信息。
df = pd.read_csv("data/ex-ch11-4-earthquake.csv")
df.head()
--end--
后台回复【数据练习】 获取PDF全文&练习数据

创作不易,点赞支持↓
以上是关于机器学习实践:了解数据核心的通用方法!的主要内容,如果未能解决你的问题,请参考以下文章