彻底搞懂程序链接过程之动态链接
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了彻底搞懂程序链接过程之动态链接相关的知识,希望对你有一定的参考价值。
通过静态链接,可以生成一个可执行文件,这个可执行文件既可以是完全链接的也可以是部分链接的,对于部分链接的可执行文件,有些符号引用需要等到可执行文件加载时甚至是运行时才会进行符号解析和重定位。
动态链接与静态链接一样包括符号解析和重定位两个任务,静态链接和动态链接的区别之一就是符号解析和重定位的时机,动态链接分为加载时动态链接和运行时动态链接,本篇文章将拆分成3个部分阐述:
1.可执行文件的结构和加载过程。
2.加载时动态链接。
3.运行时动态链接。
可执行文件的结构和加载过程
可执行文件的结构
可执行文件的结构与可重定位目标文件的结构类似,都是采用ELF文件格式,不同的是它们包括的节有差异,另外可执行文件增加了程序头部表(program header table),如下图所示
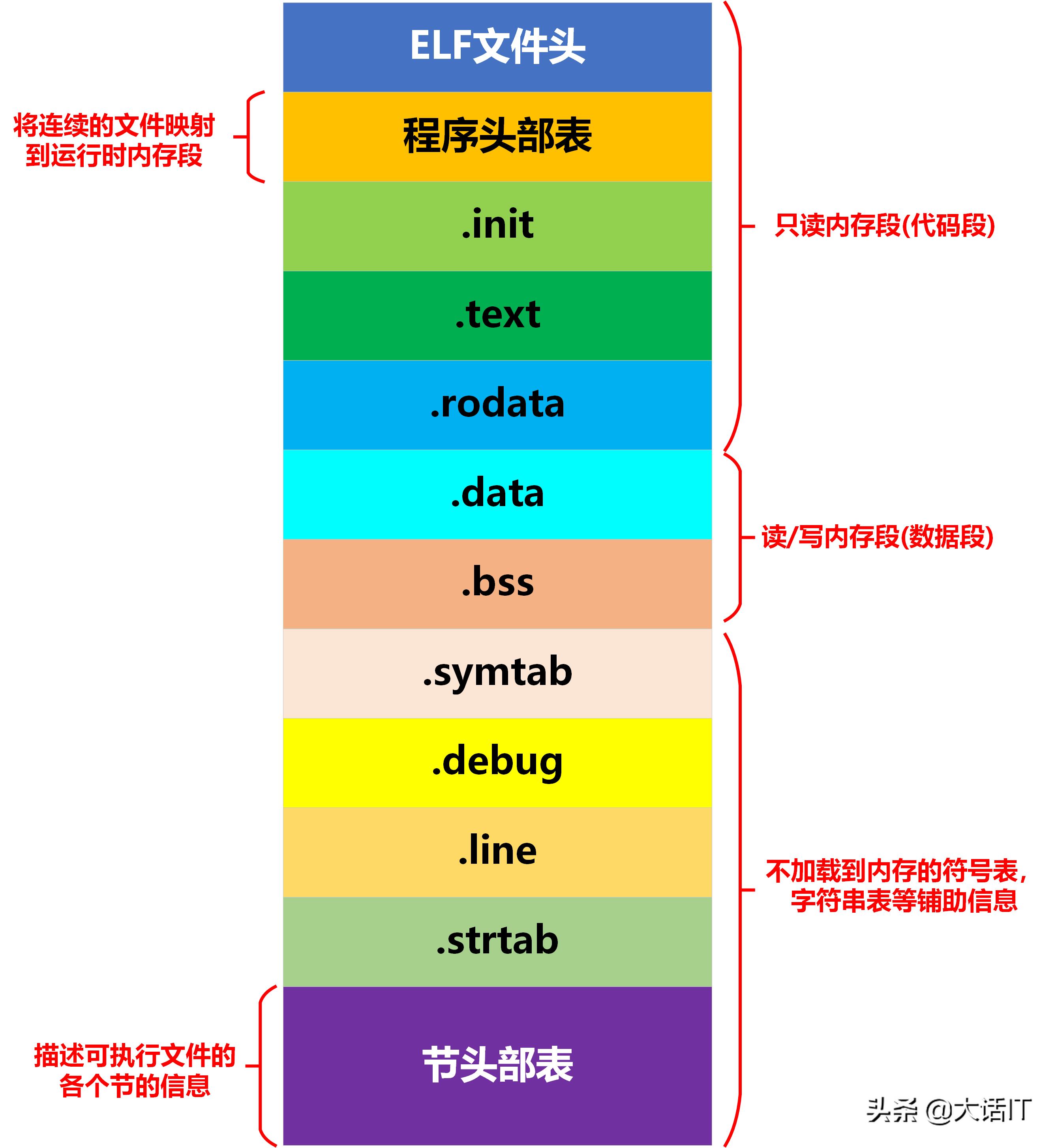
可执行文件结构图
如上图所示,对于可执行文件来说,ELF文件头中的程序入口地址字段不再为空,入口地址指向了第一条指令的虚拟内存地址,.init是一个函数,这个函数在程序加载时,做一些初始化的工作。
可执行文件中只有一部分内容能够加载到内存中,如上图所示,.init,.text,.rodata这几个节,程序头部表以及ELF文件头会加载到内存中代码段中,代码段的权限只读,.data,.bss这两个节加载到内存的数据段,数据段的权限是读和写,其它节不能加载到内存中,只起到辅助作用。
可执行文件与可重定位目标文件相比较多出了一个程序头部表,下面阐述下程序头部表的作用。
程序头部表:
程序头部表负责将可执行文件中连续的内容映射到连续的内存段,通过【objdump -dx 可执行文件】可以查看可执行文件的结构,其中可以看到程序头部表的描述信息,如下图
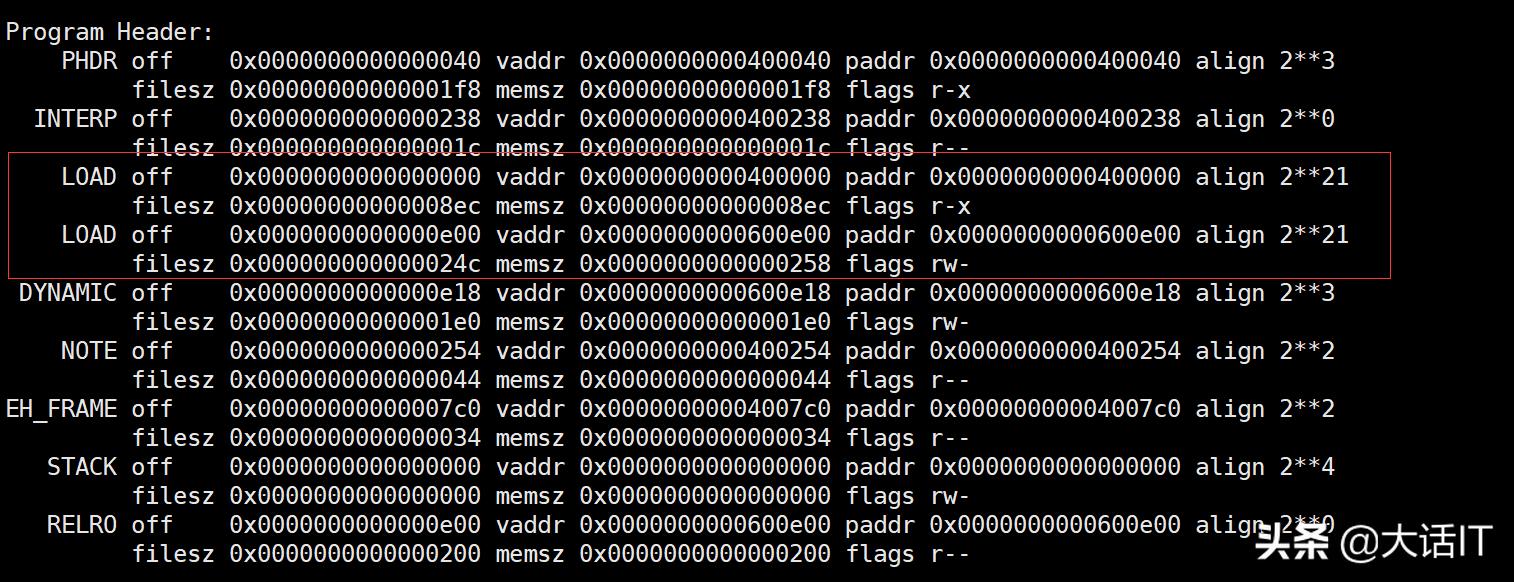
程序头部表
由上图得知程序头部表包括了9个表项,我们重点关注2个LOAD表项。
第一个LOAD表项:这个表项用于将可执行文件的.init,.text,.rodata这几个节,程序头部表以及ELF文件头的内容映射到只读内存段即代码段,其中off=0x0000000000000000表示从可执行文件偏移0处开始映射,filesz=0x00000000000008ec表示映射范围的大小,vddr=paddr=0x0000000000400000表示映射到代码段的开始地址为0x0000000000400000,memsz=0x00000000000008ec表示映射的代码段大小,flags=r-x表示代码段是可读,可执行的,align=2的21次方表示代码段的开始地址必须是2的21次方的整数倍,通常来说off%align=vadd%align。
第二个LOAD表项:这个表项用于将可执行文件的.data,.bss这两个节的内容映射到读写内存段即数据段,其中off=0x0000000000000e00表示从可执行文件偏移0x0000000000000e00处开始映射,filesz=0x000000000000024c表示映射范围的大小,vddr=paddr=0x0000000000600e00表示映射到数据段的开始地址为0x0000000000600e00,memsz=0x0000000000000258表示映射的数据段大小,flags=rw-表示数据段是可读,可写的,align=2的21次方表示数据段的开始地址必须是2的21次方的整数倍,通常来说off%align=vadd%align。
可执行文件的结构就介绍到这里了,下面介绍下可执行文件的加载过程。
可执行文件的加载
我们经常通过./prog 命令加载一个可执行文件,prog是可执行文件的名称,当执行这个命令时,操作系统会调用内核中的一个加载器(loader),通过加载器来运行可执行文件,另外在Linux中也可以采用execve函数来调用加载器。
加载器加载一个可执行文件时,会执行以下步骤:
1.创建一个进程上下文和进程虚拟地址空间,如下图为进程虚拟地址空间
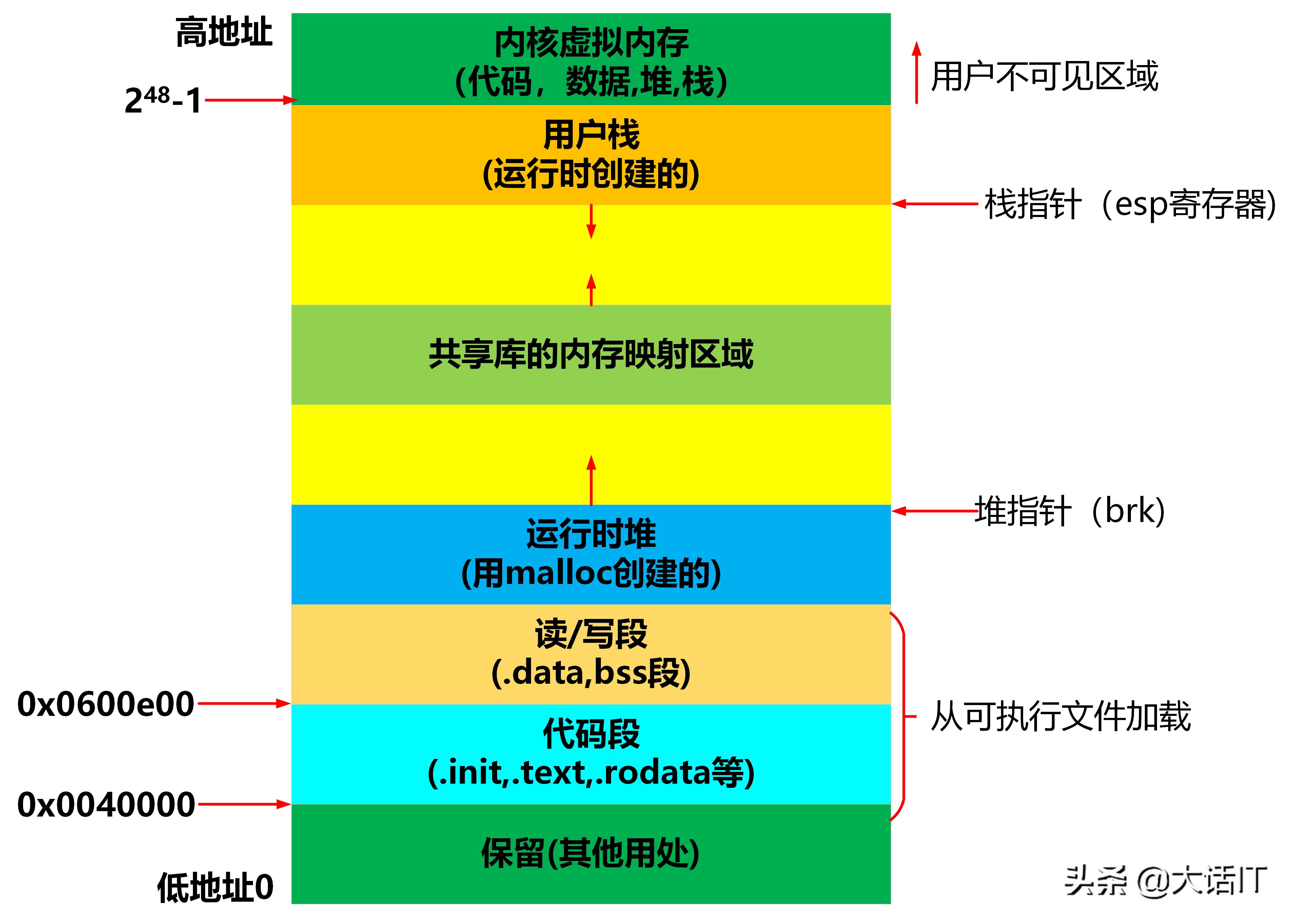
2.建立可执行文件的内容(按照页大小)和虚拟地址空间页的映射关系(依据程序头部表),依据程序头部表可以得出,代码段总是从0x0000000000400000开始的,数据段则是从0x0000000000600e00开始的,代码段的大小为0x00000000000008ec,数据段的大小为0x0000000000000258。
3.将可执行文件的文件头信息加载到内存。
以上就是加载一个可执行文件的过程,可以看出加载的过程并没有把可执行文件中的代码和数据加载到内存,当CPU第一次调度进程时,加载器才会根据文件头中的程序入口地址,开始执行第一条指令,当执行这条指令时,发现指令不在内存中,发生了缺页中断,才会将虚拟页加载到内存中。
程序的入口地址往往指向_start函数,_start函数调用系统启动函数__libc_start_main,这个系统启动函数定义在libc.so中,它负责初始化执行环境,调用用户层提供的main函数,同时负责处理main函数的返回值,并在合适的时机交由内核处理。
加载时动态链接
静态链接是在执行链接命令时开始链接过程,通常链接的是静态库,另外静态库可以实现按需链接即用到了到哪个函数就链接哪个函数到可执行文件中。
不过静态库有以下几个弊端:
1.静态库的内容发生了变化,其它依赖静态库的程序需要重新编译。
2.静态链接时,将静态库的函数和数据复制到了可执行文件中,因此多个可执行文件就会有多份函数和数据,这个会耗费大量的磁盘空间,如果将这些可执行文件加载到内存则会耗费大量的内存。
因此,共享库就诞生了,它在内存中独一份,共享库是个共享目标文件,也是采用ELF文件格式,通常是以.so作为文件后缀,这里顺别提一下微软的共享库是DLL文件。
当可执行文件加载时,由动态链接器加载共享库到内存中,然后和可执行文件进行链接,因此这个过程叫做加载时动态链接。
可以通过【gcc -shared -fpic -o allvector.so addvec.c multvec.c】命令生成一个共享库,对于-fpic表示生成位置无关的共享库,一般来说生成共享库必须有这个选项,后续会单独介绍。
生成了共享库后,可以通过【gcc -o proglib mainlib.c ./allvector.so】命令生成一个可执行文件,当然这个命令并也需要执行静态链接,通过静态链接将一些需要静态链接的目标文件进行链接,链接后生成一个部分链接的可执行文件,当可执行文件加载时,通过动态链接器链接allvector.so这个共享库。
可执行文件加载时,有一个.interp节,这个节包含了动态链接器的文件路径,动态链接器也是一个共享库,操作系统负责加载和运行这个动态链接器,然后由这个动态链接器来负责加载共享库,动态链接器接下来共享库的链接过程。
以【gcc -o proglib mainlib.c ./allvector.so】这个命令生成的可执行文件为例,加载可执行文件时,动态链接的过程大致如下:
1.加载共享库libc.so这个共享库中的数据和代码到内存段,并进行符号解析和重定位。
2.加载共享库allvector.so这个共享库中的数据和代码到内存段,并进行符号解析和重定位。
3.对proclib可执行文件中涉及到的未定义的符号引用进行解析和重定位。
可执行文件运行时动态链接
除了在可执行文件加载时进行动态链接,也可以在应用程序运行过程中,加载和运行一个共享库,然后进行动态连接。
运行时动态连接有两个常见场景:
1.分发软件包,例如采用共享库来作为一个软件升级包,用户下载这个这个共享库后,替换了旧版本,应用程序运行时,会自动加载这个共享库并进行重新链接。
2.构建高性能的Web服务器,很多Web服务器接受客户端的请求生成动态的页面内容,早期的做法是创建一个子进程(fork),然后在这个子进程来生成动态的页面内容,这样的方式性能不是很好,不利于扩展,而高性能的Web服务器则是将每个动态生成页面内容的函数封装成一个共享库,当服务器接受到客户端请求时,会动态链接到合适的函数,然后调用它,这个函数只加载一次,便会缓存在内存中,下一次请求同一个函数时,就是直接获取这个函数指针即可,另外,如果函数发生变化时,不需要重启服务器,只需要重新加载这个共享库就可以了,另外Web服务器也可以动态增加一个新的函数,来满足新的业务需求。
Linux提供了运行时加载共享库的接口,如下所示:
#include <dlfcn.h>
// 打开一个共享库,返回一个共享库句柄
void *dlopen(const char*filenames, int flag);
// 根据一个共享库句柄,查找某个函数名的指针
void *dlsym(void *handle, char*symbol);
// 根据共享库句柄,关闭一个共享库,如果没有其它程序
// 引用这个句柄,则卸载这个共享库
int dlclose(void *handle);
// 用于检查dlopen,dlsym,dlclose操作是不是成功,如果不成功
//则返回错误信息,否则返回NULL
const char *dlerror(void);Java中要调用C函数,通常采用JNI,原理就是将C函数编译成一个共享库(*.so),当一个Java程序运行时,Java解释器调用dlopen接口打开这个共享库,然后通过函数名调用dlsymf返回函数地址,然后调用这个函数。
位置无关代码
共享库的目的是多个程序共享一份库代码,那么多个程序是怎么共享一份库代码呢,一种方式是将一个共享库存储在内存的固定位置,然后程序动态链接时,将符号引用重定位到这个位置就可以了,然后这种方式也有不少弊端:
1.地址空间的使用率不高,例如一个共享库即使没有被使用,它也占用哪个空间,因为这个空间已经被分配出来了。
2.一个共享库的版本发生了变化后,占用的空间可能会扩大,这样很有可能需要选择一个新的内存段来存储这个共享库。
3.新的共享库需要新的内存段,随着时间的推移,会有大量大小不一的共享库,这就会造成很多不能使用的空闲内存。
4.每个系统,库在内存中的分配方式不同,这样就增加了管理难度。
为了解决上述的弊端,现代系统编译共享库代码,这个共享库代码是可以加载到内存的任意位置的,所有用到这个共享库代码的程序,通过【gcc -shared -fpic -o allvector.so addvec.c multvec.c】的方式生成位置无关的代码,其中-fpic就表示生成位置无关的代码。
位置无关代码的实现原理是基于以下一个事实:
可执行文件的代码段中指令引用的数据变量的地址和函数的地址是相对固定的即位置无关的,如下图:
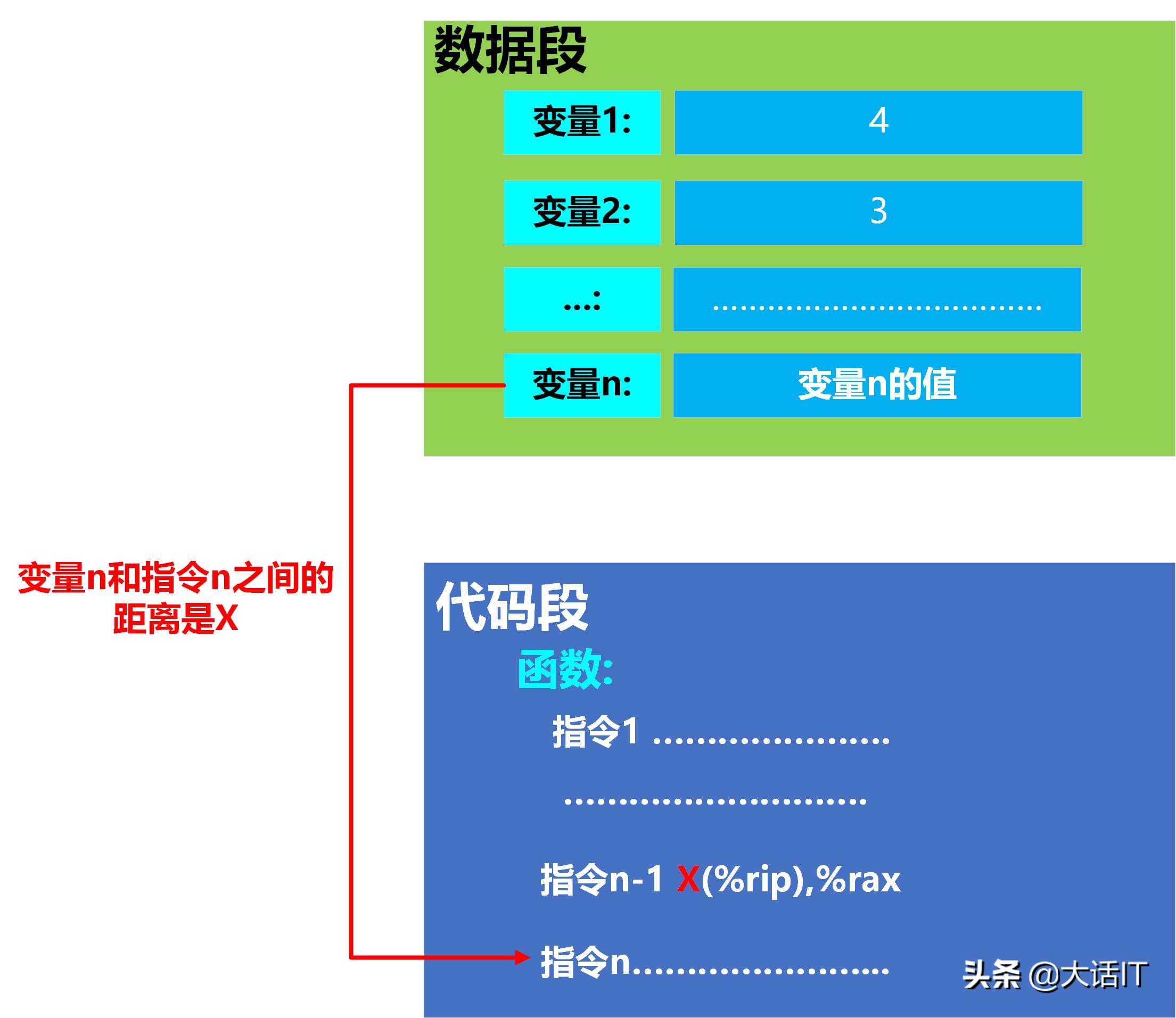
代码段和数据段的距离是固定的X
如上图所示,代码段的【指令n-1】引用到了数据段的【变量n】,当执行【指令n-1】时,(%rip)表示下一条指令即【指令n】的地址,【指令n】的地址与变量n的地址位置差是X,这个X是固定的,与内存无关的,因此执行【指令n-1】时,通过X[%rip]即指令n的地址+X总是能够获取正确的变量n的地址。
位置无关的代码基于上面所述的事实,可以分为两类:全局变量引用的位置无关和函数引用的位置无关,下面分别讨论:
全局变量引用的位置无关:
编译器为了实现全局变量引用的位置无关,引入了一个全局偏移量表(GOT),全局偏移量表为每个全局变量引用增加一个条目,每个条目占用8个字节,每个条目都有一个重定位条目,当可执行文件加载时,会根据重定位条目对全局变量进行重定位,将条目的内容设置为全局变量重定位后的地址,如下图所示
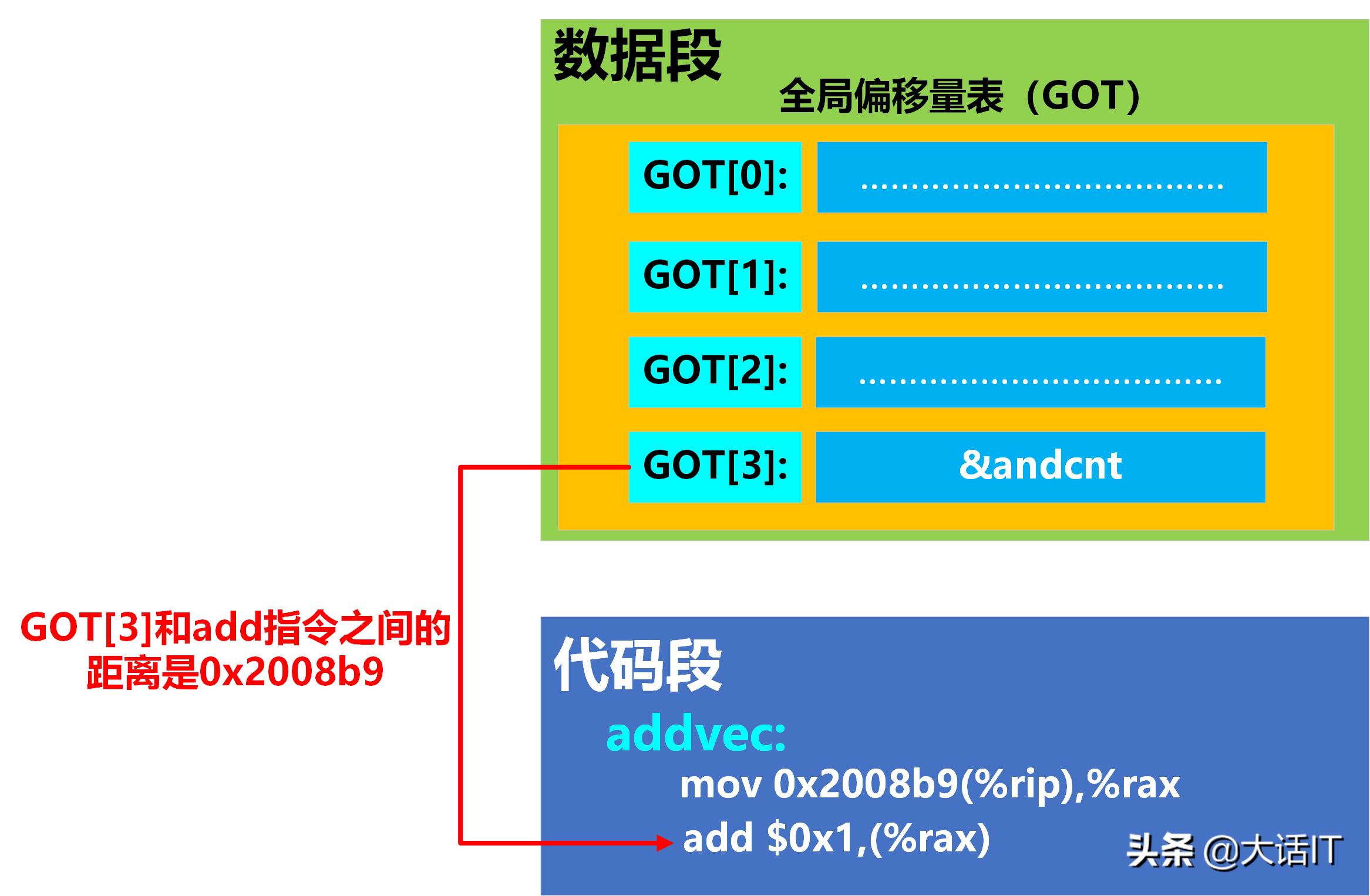
全局变量GOT
上图是基于如下的代码
int addcnt = 0;
void addvec(int *x,int *y,int *z, int n)
{
int i;
addcnt++;
for(i = 0; i < n; i++){
z[i] = x[i] + y[i];
}
}由上图和上述代码可以看出,addvec函数引用了全局变量addcnt,在addvec函数中执行指令【mov 0x2008b9(%rip),%rax】时,0x2008b9是当前执行指令的下条指令和GOT[3]的距离,这个距离是固定的,与内存无关的,【mov 0x2008b9(%rip),%rax】指令通过访问GOT[3]来间接获取addcnt的全局变量的地址,当addcnt全局变量的内存地址发生变化时,只需要将GOT[3]的内容进行调整,addvec的所有指令不需要进行调整,这就实现了全局变量引用的位置无关。
函数引用的位置无关:
编译器为了实现函数引用的位置无关,采用全局偏移量表GOT和过程链接表PLT共同来完成的,如下图所示:
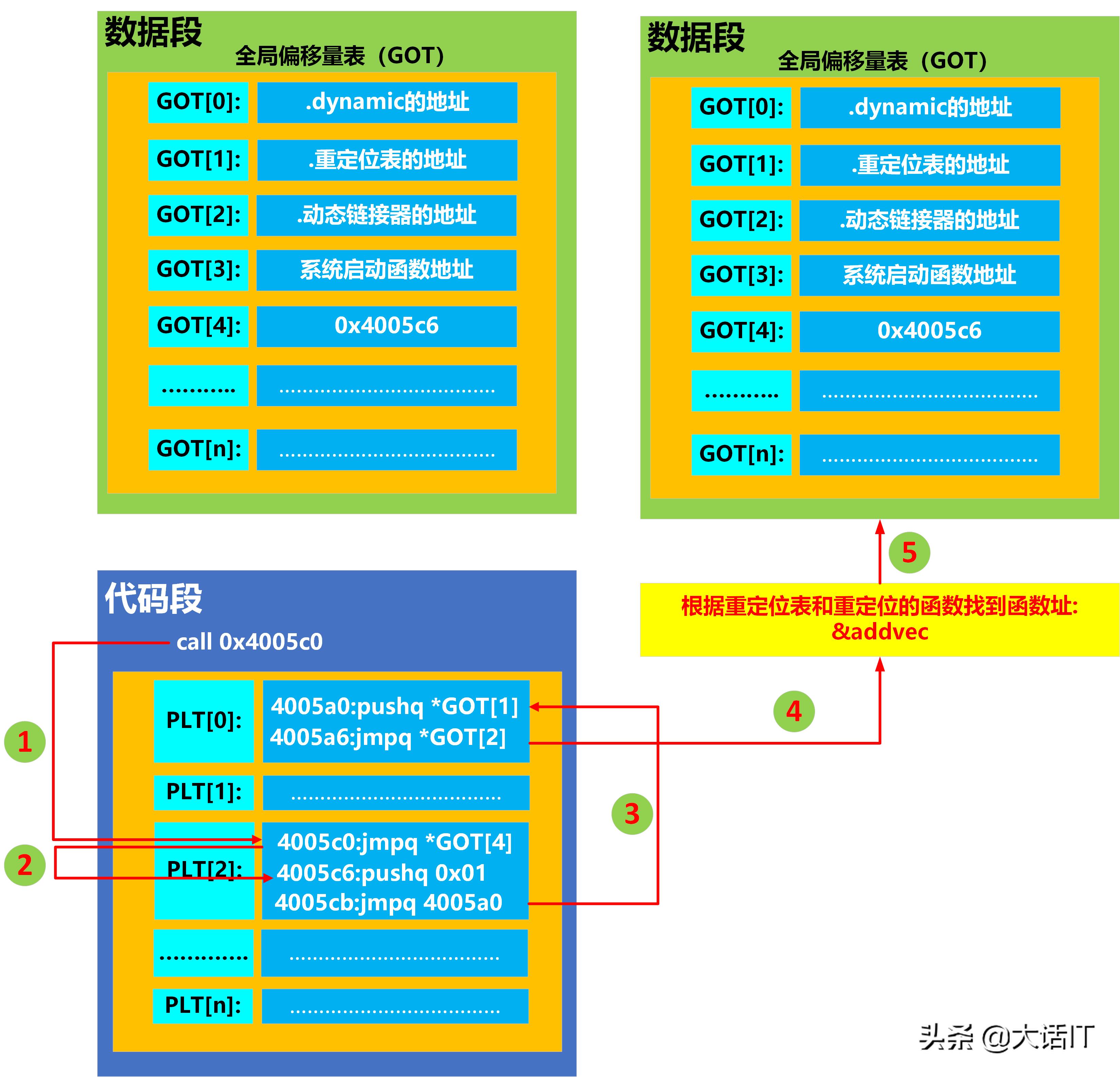
PLT
上图基于如下代码
int addcnt = 0;
void addvec(int *x,int *y,int *z, int n)
{
int i;
addcnt++;
for(i = 0; i < n; i++){
z[i] = x[i] + y[i];
}
}由上图得知:
在代码段中,编译器创建了一个PLT表,PLT包括多个表项,每个表项包括几条指令,PPLT[0]和PLT[1]是内置的表项,PLT[0】用于调用动态链接器,然后重定位某个函数引用的地址,PLT[1]用于跳转到__libc_start_main函数执行初始化工作,这个函数调用了用户程序的main函数,从PLT[2]开始为函数引用的表项,有多少个函数引用就有多少个表项,例如PLT[2]为第一个函数引用的表项,PLT[3]为第三个函数引用的表项,以此类推。
在数据段中,编译器创建为了GOT表,GOT表包括多个表项,每个表项里存储一个地址,GOT[0]~GOT[3]是内置的表项,从GOT[4]开始,每个函数一个表项,例如GOT[4]是第一个函数引用的表项,GOT[5]为第二个函数引用的表项,编译器生成可执行文件时,GOT[4]中存储的地址总是指向了PLT[2]表项的第二条指令,GOT[5]中存储的地址总是指向了PLT[3]表项的第二条指令,因此类推。
以GOT[4]为例,GOT[4]为函数引用addvec的表项。
当一个目标文件第一次调用addvec时,经历了5个步骤:
1.执行指令call 0x4005c0。0x4005c0为PLT[2]表项的地址,这个地址是个相对地址,与内存无关的,生成可执行文件时,就已经确定了。
2.跳转到PLT[2]表项即0x4005c0地址处,开始执行PLT[2]表项的指令,PLT[2]表项的第一条指令就是跳转到GOT[4]指向的地址,这个地址在第一次调用时,刚好是PLT[2]表项的第二条指令地址。
3.跳转到PLT[2]表项的第二条指令后,将函数引用的编号这里是0x01入栈,然后跳转到了PLT[0]表项。
4.开始执行PLT[0]表项的指令,第一条指令是将重定位表的地址入栈,然后调用动态链接器。
5.动态链接器利用传入的重定位表和函数引用编号对函数进行重新定位,找到了函数引用对应的内存地址,然后更新到GOT[4]。
当一个目标文件第二次调用addvec函数时,经历了2个步骤:
1.call 0x4005c0。0x4005c0为函数引用的表项即PLT[2]的地址。
2.跳转到PLT[2]表项,开始执行PLT[2]表项的指令,PLT[2]表项的第一条指令就是跳转到GOT[4]指向的地址,由于GOT[4]刚好是函数引用的地址,直接调用函数了,后面的步骤就不需要了。
以上是关于彻底搞懂程序链接过程之动态链接的主要内容,如果未能解决你的问题,请参考以下文章