用 Python 进行 OCR 图像识别
Posted Python猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 Python 进行 OCR 图像识别相关的知识,希望对你有一定的参考价值。

数据采集就怕遇到图片,只能看不能复制怎么办。手动将文字提取出来,要耗费很大的工作量。
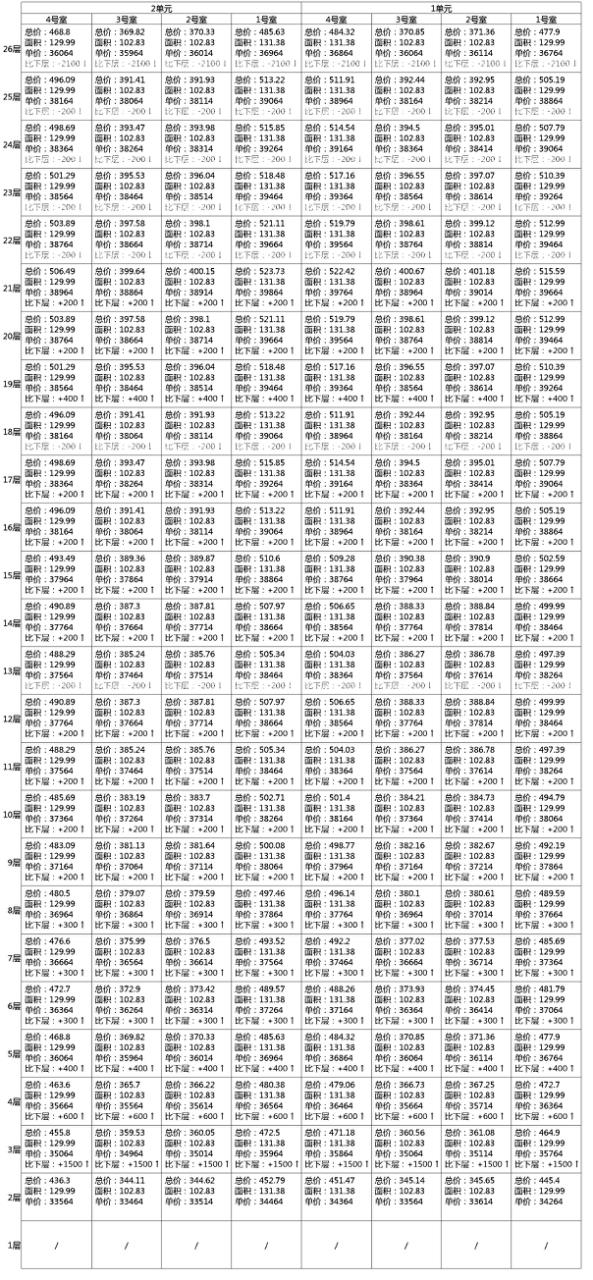
例如下图,某楼盘的一房一价表,怎么样发现单价低位的房子?光凭肉眼很难发现吧,能否让计算机进行文字的识别,然后再对这些数值型信息进行数据分析?
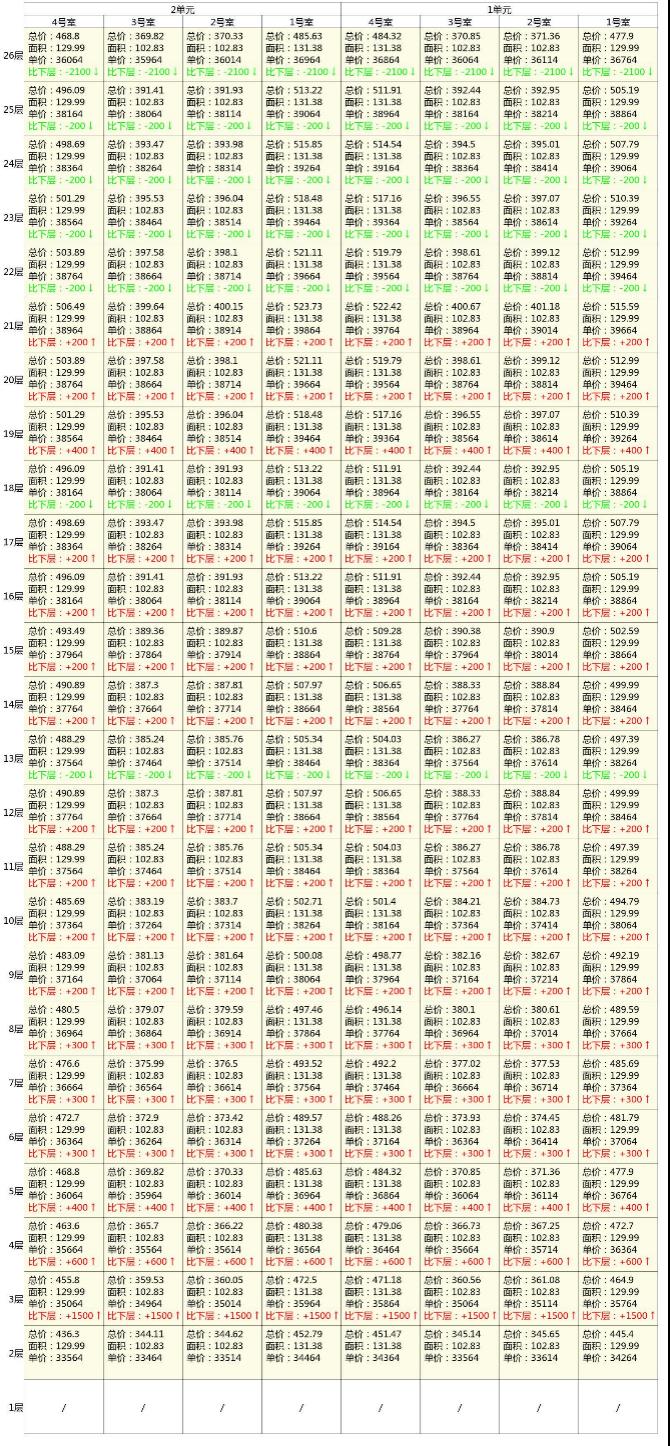
首先把图片中的单价提取出来,
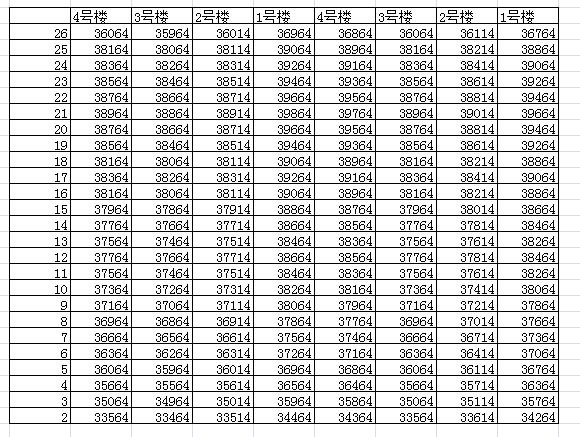
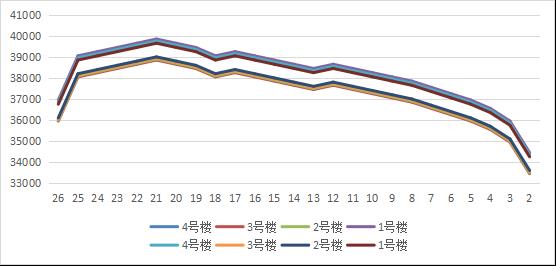
进而生成图像:
用python就可以实现,采用现在流行的OCR图像识别。主要思路是使用机器学习模式,通过已有图片手动训练出一个图像识别模型,具体步骤如下:
一、将图片预处理,更方便计算机识别
(一)把图像灰化
使用open-cv库对图片进行处理。

使用灰化后的图片,如下图,排除干扰信息,能让识别更加稳定。
(二)把图片分割
将图片分割成小方块,一是提高识别精度,二是方便将数据储存为表格形式。可以设定好参数,根据坐标系把图片裁剪成一个个小方块,如下图,储存为jpg格式。

二、建立图像识别模型
(一)将分割好的小方块图片合并成tiff文件
下载jTessBoxEditor,打开jTessBoxEditor.jar,使用tools下的merge tiff工具,将图片合并成tiff文件。
(二)使用已有模型对tiff文件进行初识别
下载并安装tesseract,并配置好环境变量,将Tesseract-OCR和tessdata的路径加入到环境变量下的path下面。
Tesseract自带图像识别的模型,例如中文简体汉字识别模型chi_sim.traineddata,英文识别模型eng.traineddata,这些模型可以网上下载,放到tessdata里面即可使用。
然后进入tiff所在文件夹。在命令窗口,输入:tesseract ***.tif *** -l +++ -psm 7 batch.nochop makebox,按回车生成box文件。其中***为tif的文件名,+++为要生成的traindata的文件名。
(三)使用jTessBoxEditor对tiff和box文件进行调整
打开jTessBoxEditor.jar,在box editor中的open按钮,打开要编辑的tif文件。编辑之后保存,生成box文件。保存在同一个文件夹里。
(四)使用tiff和box文件生成模型
在tiff和box的文件中,在命令窗口输入以下代码,最终生成模型(traindata文件)
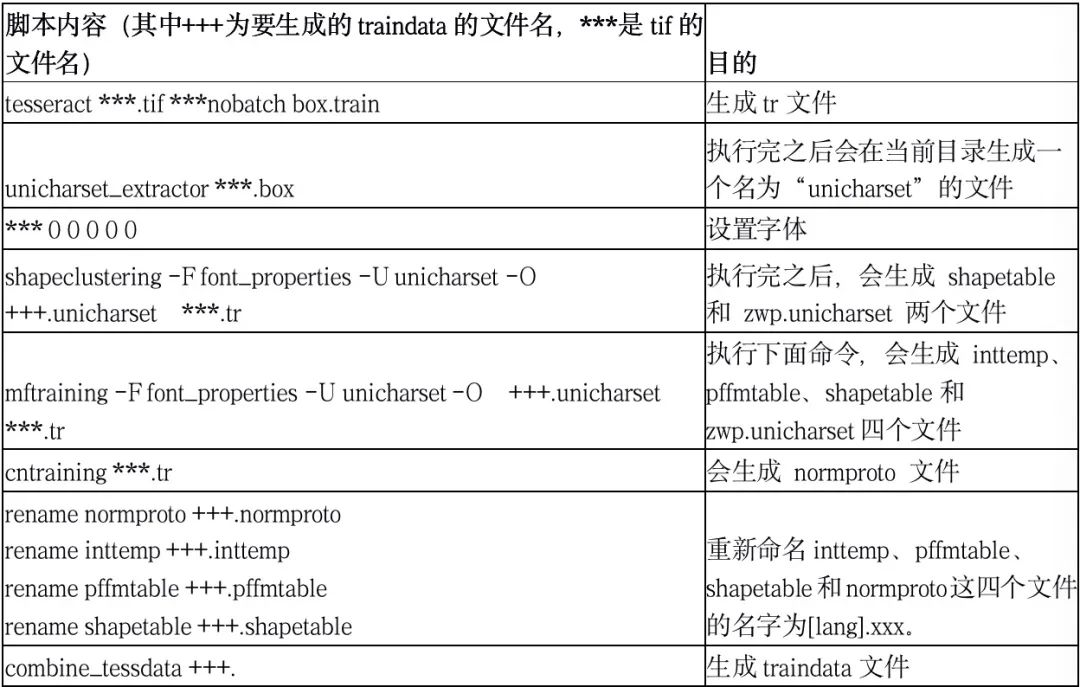
上述脚本也可以写在bat文件中,运行脚本来生成traindata,最终仅需要将traindata复制到tessdata里面,即可使用该模型。
三、应用图像识别模型
安装完,训练完模型之后,就要在python中使用模型了。安装pytesseract,找到pytesseract.py文件,打开编辑,将其中的“tesseract_cmd = 'tesseract'”,改成tesseract的安装路径(如C:\\Program Files\\Tesseract-OCR\\\\tesseract)。
因为模型是采用灰化后的图片训练的,所以在识别时也要使用灰化。

四、优化图像识别模型
在使用中,如果有错误,可以存下来,加入训练库,优化图像识别模型。在一般是识别错误的图片,积攒一阵子后。累积做成tif文件。注意:同类错误选择几个记号了,训练库尽量小而精。

Python猫技术交流群开放啦!群里既有国内一二线大厂在职员工,也有国内外高校在读学生,既有十多年码龄的编程老鸟,也有中小学刚刚入门的新人,学习氛围良好!想入群的同学,请在公号内回复『交流群』,获取猫哥的微信(谢绝广告党,非诚勿扰!)~
还不过瘾?试试它们
▲谷歌工程师开源:Python 调试神器 Cyberbrain
如果你觉得本文有帮助
请慷慨分享和点赞,感谢啦!
以上是关于用 Python 进行 OCR 图像识别的主要内容,如果未能解决你的问题,请参考以下文章