这几个爬虫利器让5年的程序员大佬发量还非常惊人赶紧收藏
Posted 日常分享Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这几个爬虫利器让5年的程序员大佬发量还非常惊人赶紧收藏相关的知识,希望对你有一定的参考价值。
目录
程序员,戏称“码农”、“头冷e族”,由于常年与代码为伴,用数据说话,难免给人留下了一种“木讷”“EQ低”的刻板印象
然而互联网的发展离不开程序员们的努力正是因为有了他们与bug和需求的“相爱相杀”,才有了如今互联网的兴盛。
博主听闻有人说程序员头发越少,收入越高,想来他们一定是因为压力山大,才发际线渐渐消失的吧~

那么今天,我就来说说爬虫中有什么利器可以保住自己的头发。
工欲善其事必先利其器,Python之所以流行在于她有非常丰富的第三方包,无论是Web框架还是机器学习框架、抑或是爬虫框架,多得让人眼花缭乱,这给了开发者极大的选择性,这是其它语言没法企及的。6个牛逼的爬虫利器,助你轻松搞定爬虫。
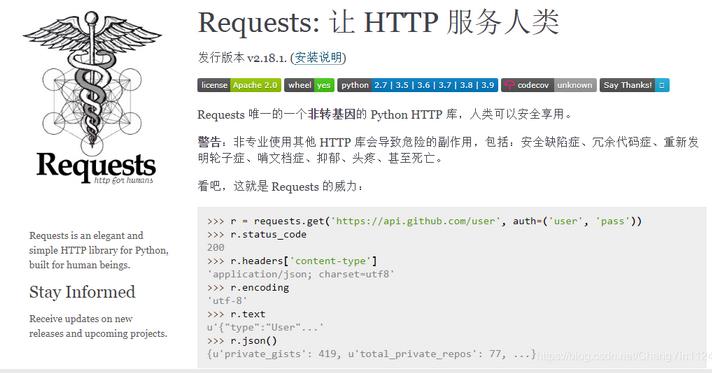
1、Requests
官网地址:https://docs.python-requests.org/zh_CN/latest/
Requests是一个HTTP请求库,完美体现了Python简单、优雅、易勇的编程哲学,开发者经常拿它的源代码作为参考,是不可多得的源代码学习资料。
2、BeautifulSoup
官方地址: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
如果说 Requests 是最好的 HTTP 请求库,那么 BeautifulSoup 就是最好的 html 解析库,HTML 文档返回之后需要解析,我们可以用 BeautifulSoup 解析,它的API对程序员来说非常友好、用起来简单,API非常人性化,支持css选择器,有人说它的速度慢,在数据量并不是特别的情况下,其实没人care,人力成本可以机器成本高多了。

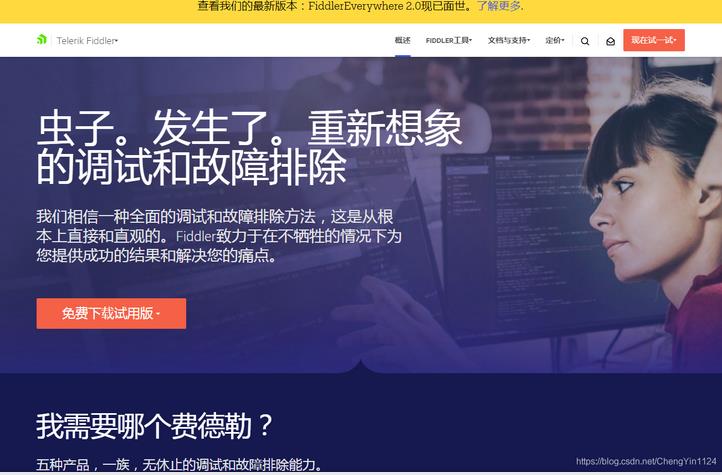
3、Fiddler
官网:https://www.telerik.com/fiddler
Fiddler 本质上不是爬数据的,而是一个爬虫辅助工具,在分析爬虫的请求时,有时候仅仅依靠浏览器来跟踪请求力量太显单薄了,特别是针对移动设备的爬虫束手无策,Fiddler 简直就是移动设备上爬虫的克星,手机上如何HTTP请求都可以被Fiddler监控,有了它,再也不要担心爬不到手机上的数据了。
4、Selenium
官网:https://www.selenium.dev/
当你无法通过Requests获取数据时,换一种方案用Selenium,Selenium 是什么?本身是自动化测试工具。如果你在浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试,当然也可以用于爬虫。比如自动打开百度:

5、Tesseract
GtiHub地址:https://github.com/tesseract-ocr
Tesseract 是一个文字识别工具,在一些复杂的爬虫情景下,服务器的反爬虫需要用户输入验证码才能进行下一步操作,而 Tesseract 可以自动识别出验证码,如果你懂一点机器学习算法,自己训练一套数据,就算12306这样的验证码也不是什么难事。
6、Scrapy
官网:https://scrapy.org/
写爬虫用Requests只能是搞搞小项目,适合刚入门的小白学习或者是简单的业务场景,如果是做大规模爬虫,Scrapy 的效率、性能都是工业级别的,你无需自己造轮子。分布式爬虫就用Scrapy。
7、总结
 下面是我整理的一些学习资料,面试题答案以及游戏源码,给需要的小伙伴【+q裙881744585】获取,希望大家的努力都不负所望,收入越来越多。 学习交流的地方,广告勿加【否则你做什么就亏什么,永远赚不到钱】
下面是我整理的一些学习资料,面试题答案以及游戏源码,给需要的小伙伴【+q裙881744585】获取,希望大家的努力都不负所望,收入越来越多。 学习交流的地方,广告勿加【否则你做什么就亏什么,永远赚不到钱】

以上是关于这几个爬虫利器让5年的程序员大佬发量还非常惊人赶紧收藏的主要内容,如果未能解决你的问题,请参考以下文章
根据Git推算程序员大佬作息:同样是熬夜,为什么他发量那么多?
今天大佬教你用python爬虫简单代码爬取图片,赶紧收藏!!!