爬取国家统计局人口与就业统计数据,看了你的文章,我朋友晚上托梦告诉我牢饭很好吃
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取国家统计局人口与就业统计数据,看了你的文章,我朋友晚上托梦告诉我牢饭很好吃相关的知识,希望对你有一定的参考价值。
大家好,我是辣条。
爬取目标
网站:国家统计局
效果展示
工具使用
开发工具:pycharm
开发环境:python3.7, Windows10
使用工具包:requests,lxml
重点内容学习
-
requests的使用
-
xpath的提取数据方法
-
获取Excel下载地址
项目思路解析
数据来源:http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/lefte.htm 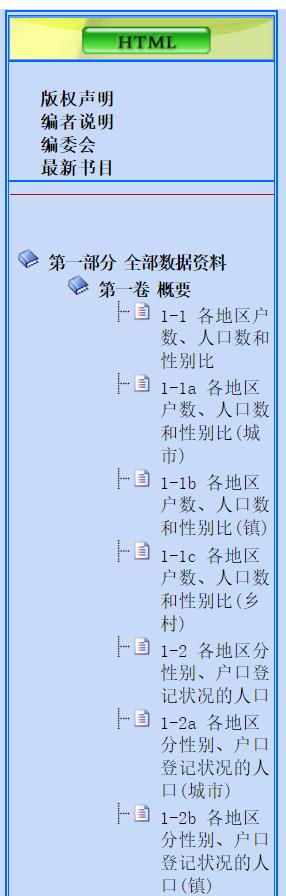
每个选项对应的是单独的表格数据 请求数据来源地址 通过xpath的方式提取出数据的下载地址 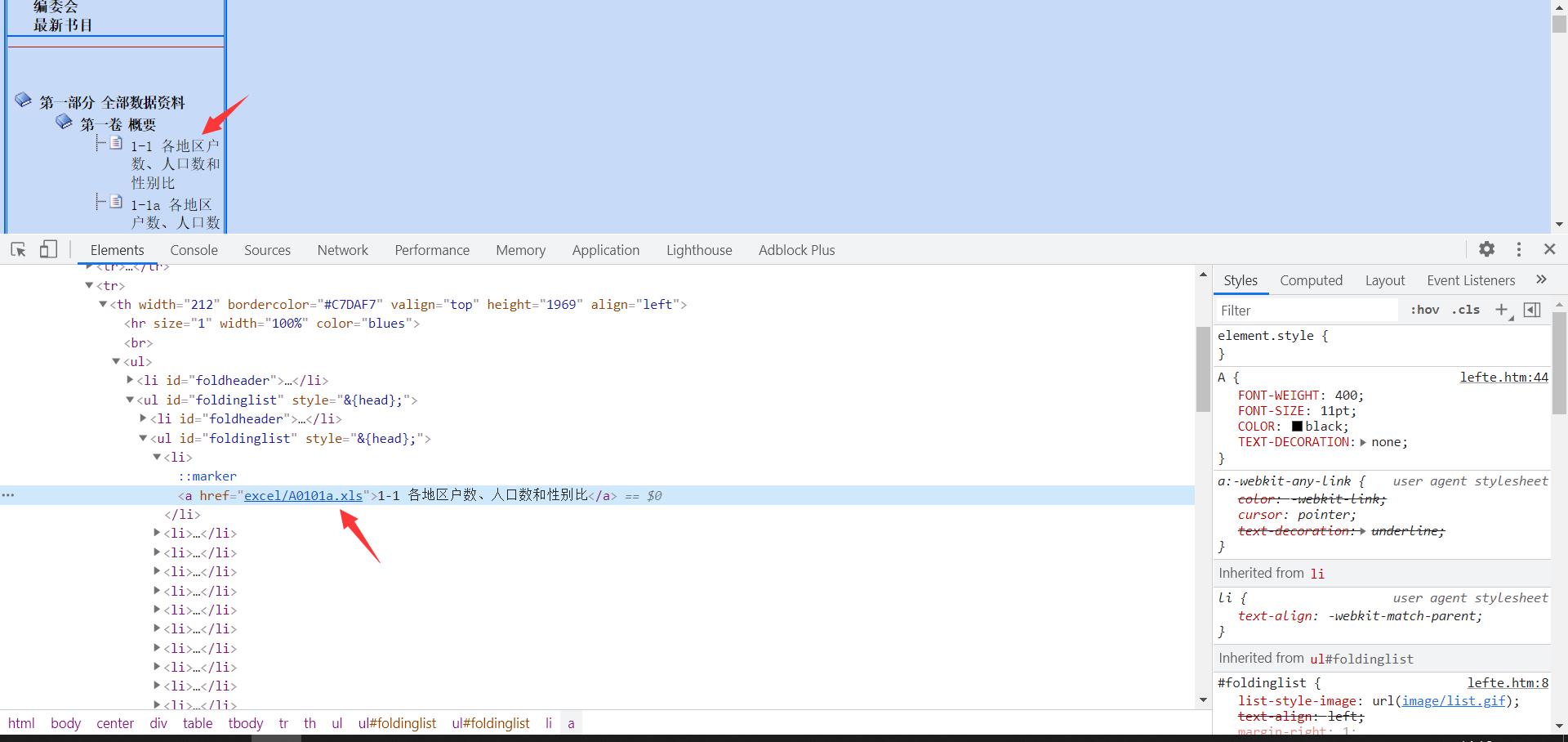 提取出数据的href属性 提取出数据的标题
提取出数据的href属性 提取出数据的标题 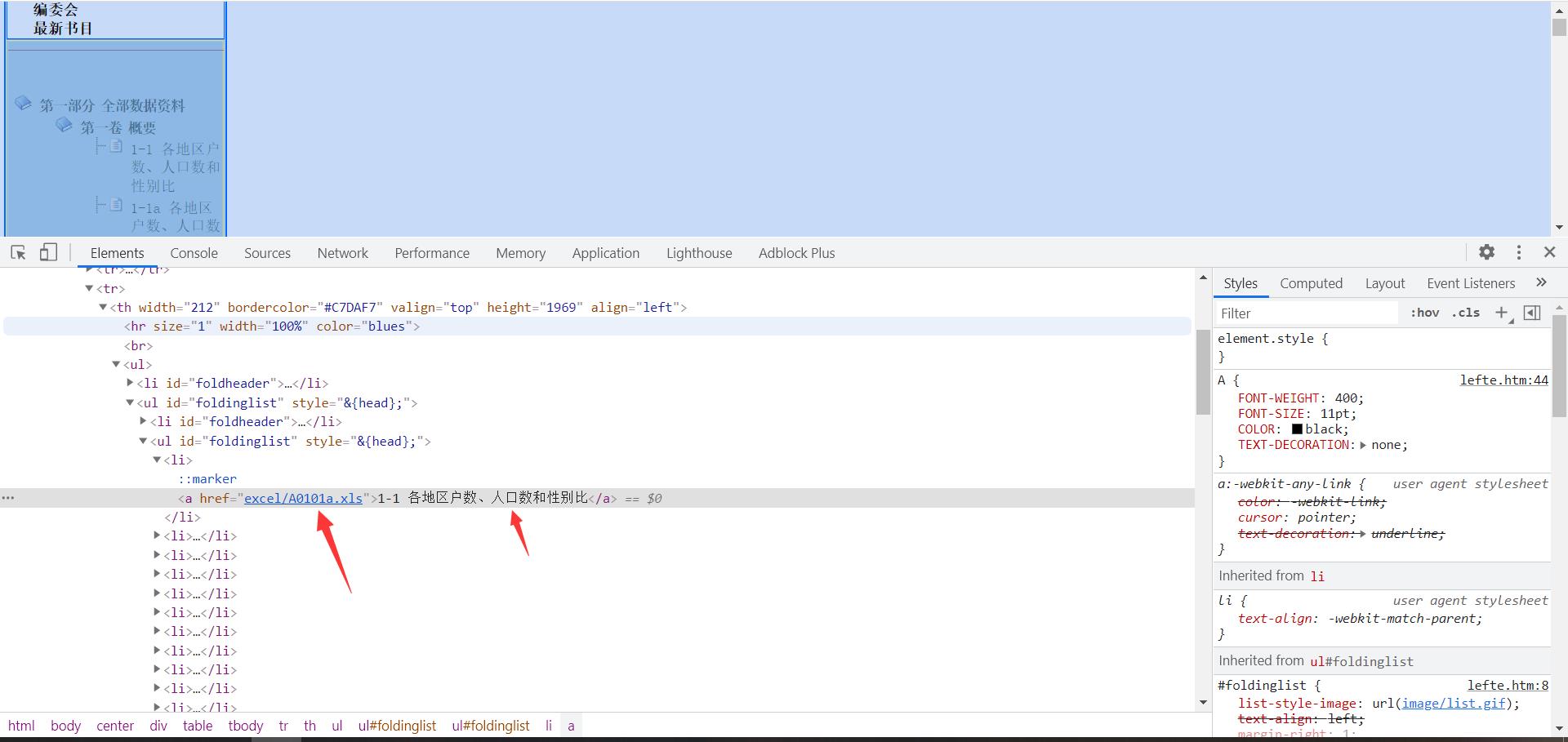
url = 'http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/lefte.htm'
response = Tools(url).content.decode('gbk')
html = etree.HTML(response) # 创建HTML对象
title = html.xpath('//ul[@id="foldinglist"]/li/a/text()') # text获取该标签内的文字内容
details = html.xpath('//ul[@id="foldinglist"]/li/a/@href') [:-13]# 下载地址的后缀取出数据拼接出新的url地址 获取到新的表格下载地址  再次请求新的url 保存文件数据
再次请求新的url 保存文件数据 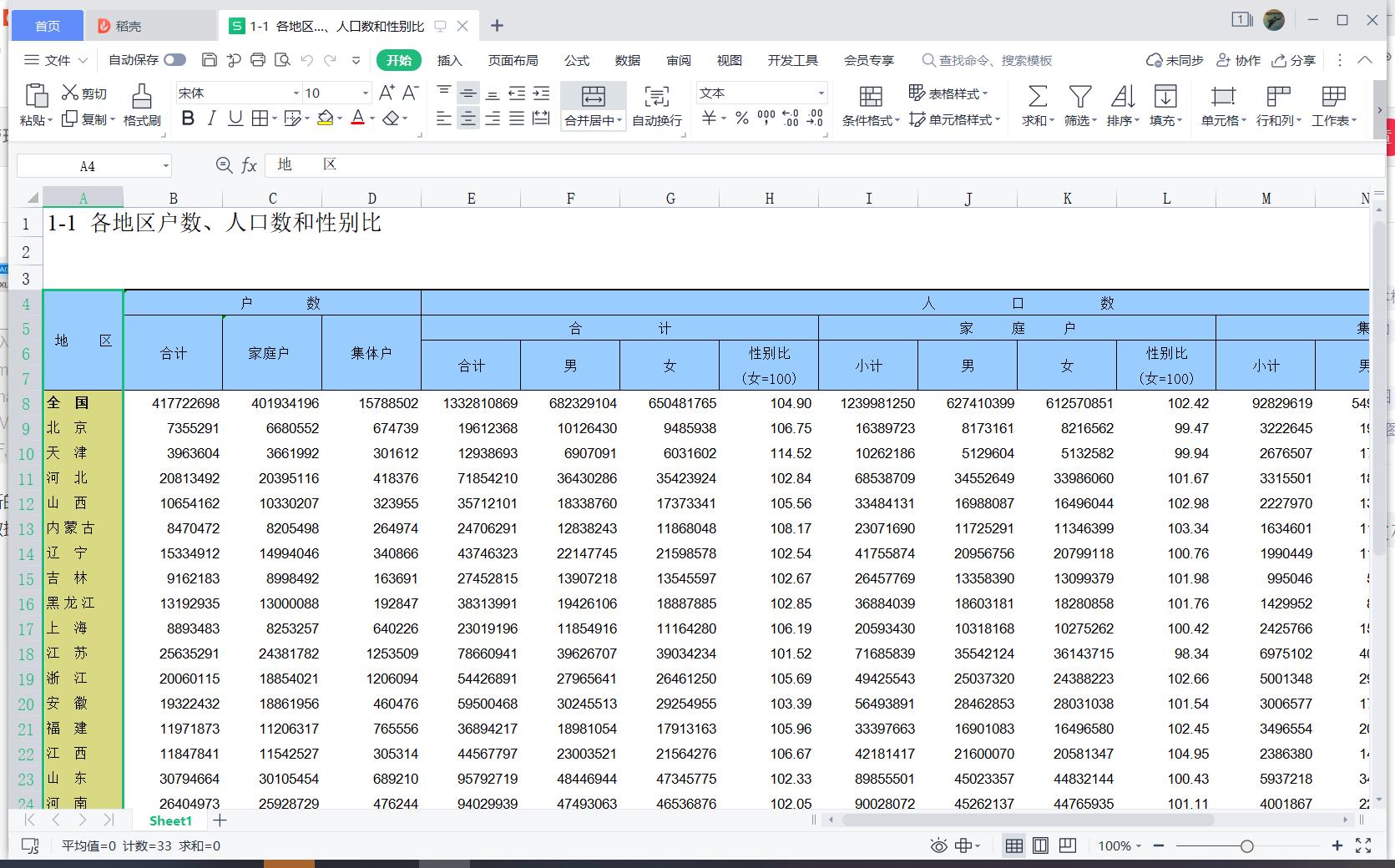
简易源码分享
import requests
from lxml import etree
def Tools(url):
# 模拟浏览器请求 防止被反爬 请求头
headers = {
'Referer': 'http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/indexce.htm',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59'
}
response = requests.get(url, headers=headers)
return response
def Save(name, urls):
'''
请求Excel下载地址 并且保存到代码同路径的 index文件夹
:param name: 存储的名称
:param urls: xls 下载地址
:return:
'''
response = Tools(urls).content # 返回的是字节
f = open('{}.xls'.format(name), 'ab')
f.write(response)
f.close()
print('{}下载完成.....'.format(name))
url = 'http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/lefte.htm'
response = Tools(url).content.decode('gbk')
html = etree.HTML(response) # 创建HTML对象 xml格式
title = html.xpath('//ul[@id="foldinglist"]/li/a/text()') # text获取该标签内的文字内容
details = html.xpath('//ul[@id="foldinglist"]/li/a/@href') [:-13]# 下载地址的后缀
for t, d in zip(title, details):
urls = 'http://www.stats.gov.cn/tjsj/pcsj/rkpc/6rp/' + d
Save(t, urls)
辣条建立了一个小白Python学习交流扣群383855172【广告、大佬勿扰】
以上是关于爬取国家统计局人口与就业统计数据,看了你的文章,我朋友晚上托梦告诉我牢饭很好吃的主要内容,如果未能解决你的问题,请参考以下文章