Python爬虫爬取酷狗TOP500的数据
Posted Vax_Loves_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫爬取酷狗TOP500的数据相关的知识,希望对你有一定的参考价值。
该文利用Requests和BeautifulSoup第三方库,爬去酷狗网榜单中酷狗TOP500的信息。
首先分析页面:https://www.kugou.com/yy/rank/home/1-8888.html
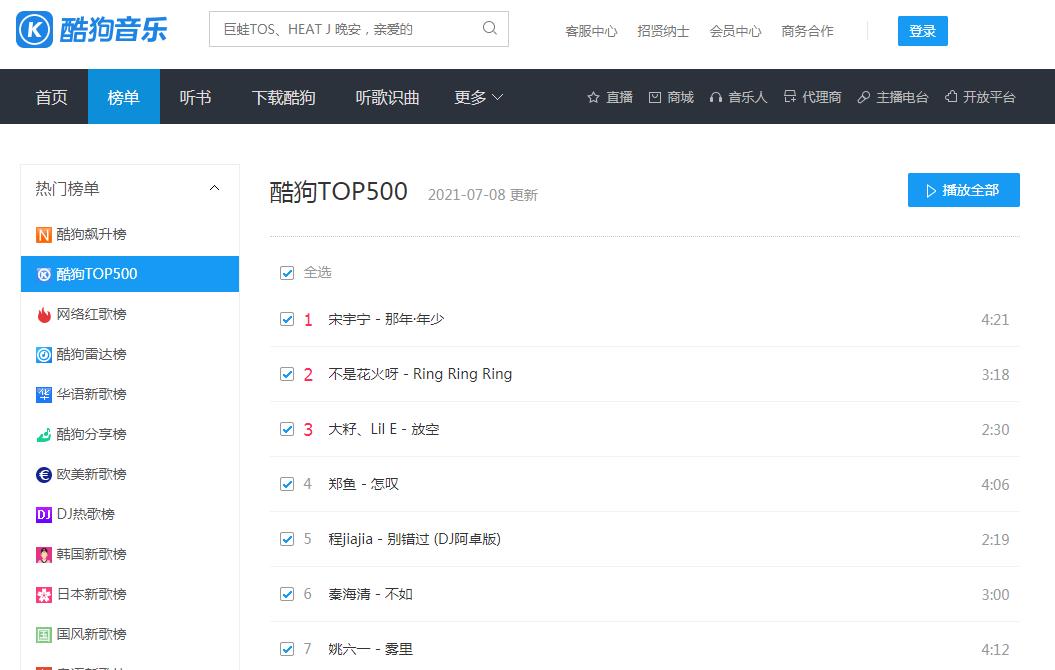
网页版酷狗不能手动翻页,进行下一步的浏览,但观察url可以尝试把1-8888的1替换成为2,在进行浏览,恰好返回的是第二页的信息。
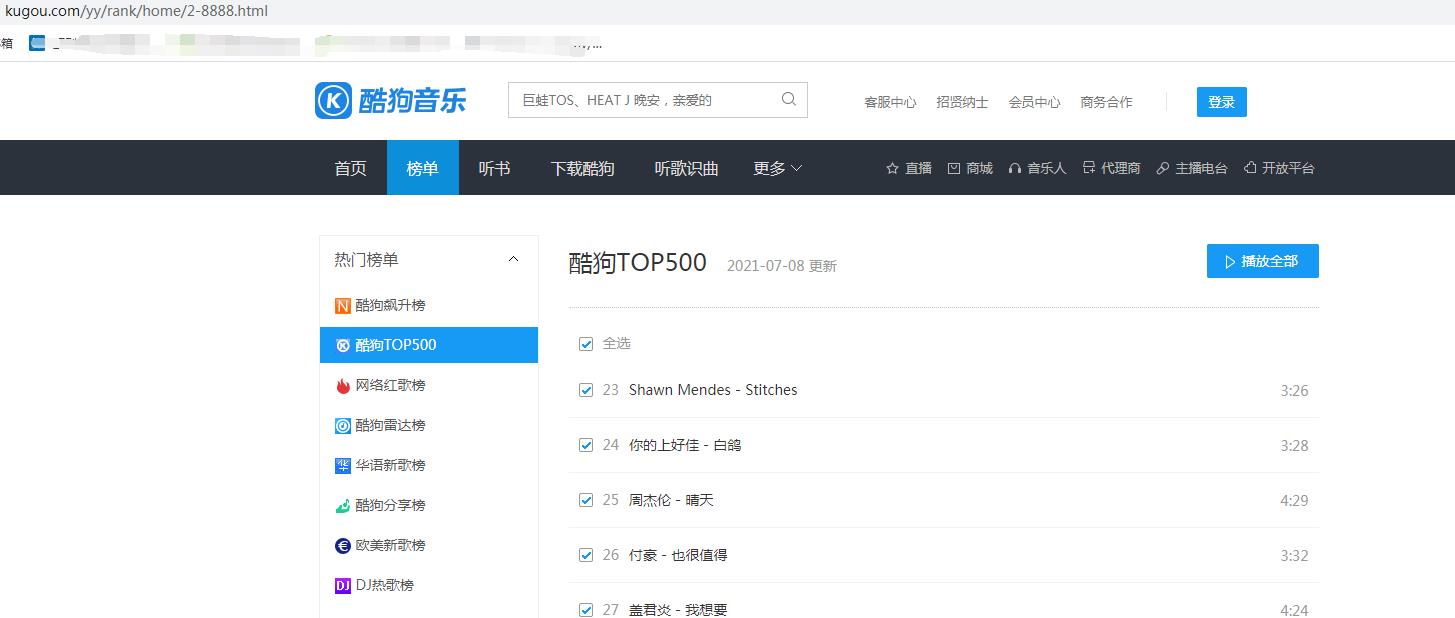
经过多次尝试。发现更换不同数字,即跳转不同的页面,因此只需要更改home/后面的数字即可,由于每页只显示22条信息,所以我们抓取前500总共需要23个页面。
我们爬取的信息由排名情况、歌手、歌曲名和歌曲时长。

代码如下:
import requests
from bs4 import BeautifulSoup
import time
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
def get_info(url):
wb_data = requests.get(url,headers=headers)
soup = BeautifulSoup(wb_data.text,'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
'rank':rank.get_text().strip(),
'singer':title.get_text().split('-')[0],
'song':title.get_text().split('-')[0],
'time':time.get_text().strip()
}
print(data)
if __name__ == '__main__':
urls = ['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,24)]
for url in urls:
get_info(url)
time.sleep(1)程序分析:
- 第1-3行导入程序需要的库,Requests库用于请求网页获取网页数据,BeautifulSoup库用于解析网页数据,time库的sleep()方法可以让程序暂停
- 第5-8行通过Chrome浏览器的开发者工具,复制User-Agent,用于伪装为浏览器,便于爬虫的稳定性。
- 第10-23行,定义get_info()函数,用于获取网页信息并输出。传入url后,进行请求和解析,通过Chrome浏览器的“检查”并Copy selector获取相应的信息,由于信息数据为列表数据结构,因此可以通过多重循环,构造字典类型,输出并打印信息。
- 第25-29行,作为程序的主入口,通过对网页url的观察,利用列表的推导式构造23个url,并依次调用get_info()函数,time.sleep(1)的意思是每循环一次,让程序暂停一秒,防止请求网页频率过快而导致爬虫失败。
实现效果:

以上是关于Python爬虫爬取酷狗TOP500的数据的主要内容,如果未能解决你的问题,请参考以下文章