爬虫日记(88):Scrapy的Downloader类
Posted caimouse
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫日记(88):Scrapy的Downloader类相关的知识,希望对你有一定的参考价值。
接着下来我们来分析下载的过程以及数据返回之后的处理,在这个过程里要小心地安排处理的步骤,否则会比较容易出错。
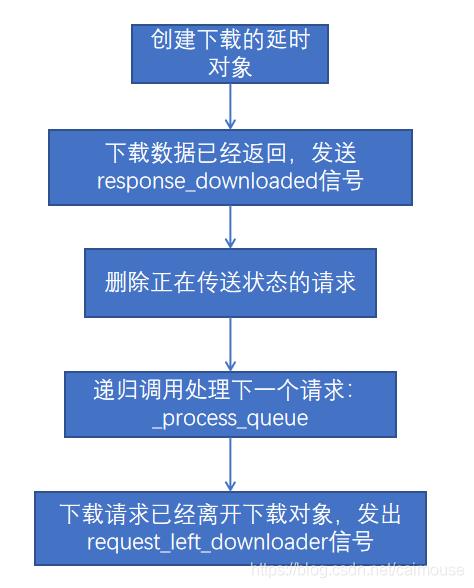
在这里按这个流程图来处理,详细的代码如下:

第160行定义了下载函数,传入是slot对象、请求对象、蜘蛛类对象。
第164行创建一个延时对象,这个延时对象执行的是self.handlers.download_request函数,它会把请求的种类进行分类,如果是HTTP就调用HTTP类,如果是文件,就调用文件下载协议。
以上是关于爬虫日记(88):Scrapy的Downloader类的主要内容,如果未能解决你的问题,请参考以下文章