高并发:通用设计方法
Posted 看,未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高并发:通用设计方法相关的知识,希望对你有一定的参考价值。
有言在先
这个系列我写完之后会再进行重组,因为觉得这些单篇讲的东西有点少。
处理办法简介
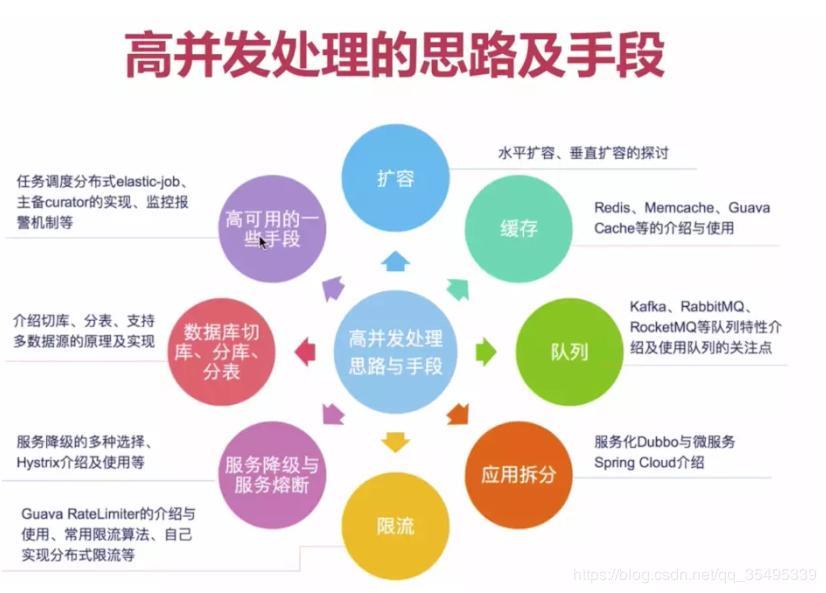
我们再面对高并发大流量时采取的办法,总结起来有以下三种:
1、Scale-out(横向拓展):采用分布式部署的方式把流量分开,让每个服务器都承担一部分并发和流量。这也是我最喜欢的一种方法,虽然我菜了点。
2、缓存:使用缓存来提高系统的性能。这是我一直嚷嚷着要用的方法,不过还没融合到系统中,这次的项目会用上。
3、异步:在某些场景下,未处理完成之前,我们可以让请求先返回,在数据准备好之后再通知请求方。这种方法,嗯,可能跟我们平时理解的异步不同哦。
Scale-up && Scale-out
Scale-up,纵向拓展,一种简单粗暴的方法,通过购买性能更好的硬件来提高系统的并发处理能力。
Scale-out,通过多个低性能的机器组成一个分布式集群来对抗高并发的流量。
如何做选择呢?这两种方法各有千秋吧。一般来说,系统设计初期的时候,考虑使用Scale-up的方式,因为这种方案足够简单。但是当系统的并发超过了单机处理的极限时,这个方法就行不通了。
而Scale-out可以突破单机的限制,但也会引入一些复杂的问题,碧如说:设计困难、环境搭建困难、节点的安全性、数据的同步等。
缓存
为什么缓存可以大幅度提升系统的性能呢?
那肯定是要更普通磁盘进行对比的啊。我们来看看普通磁盘的速度:
普通磁盘的寻道时间是 10ms 左右,而相比于磁盘寻道花费的时间,CPU 执行指令和内存寻址的时间都在是 ns(纳秒)级别,从千兆网卡上读取数据的时间是在μs(微秒)级别。所以在整个计算机体系中,磁盘是最慢的一环,甚至比其它的组件要慢几个数量级。因此,我们通常使用以内存作为存储介质的缓存,以此提升性能。
至于缓存为什么快,因为它是内置的啊,在内存中。不过也有个缺点,就是烧内存。
异步处理
什么是异步,我看到过一个非常形象生动的栗子。
小明想和奶茶,于是他去了奶茶店,发现奶茶店人有点多,这时候小明面临着三个选择:
1、等着,老老实实排队。等到猴年马月不知道,反正前面的人走光了就到他了,这叫无限等待。
如果他给自己定了个时间,十分钟等不到就不喝了,直接走人,这叫有限等待。
不管是哪种,都是属于同步的。
放在IO场景中,这叫阻塞IO。
2、先去做别的事情,隔一段时间回去看一眼,如果人还多,就再隔一段时间再来。
严谨的说,这不是异步,这叫做非阻塞IO。
3、小明给老板留了个电话,让他做好了打电话给他,于是他就去干他的事情了,这才叫异步。
调用方不需要等待方法逻辑执行完成就可以返回执行其他的逻辑,在被调用方法执行完毕后再通过回调、事件通知等方式将结果反馈给调用方。
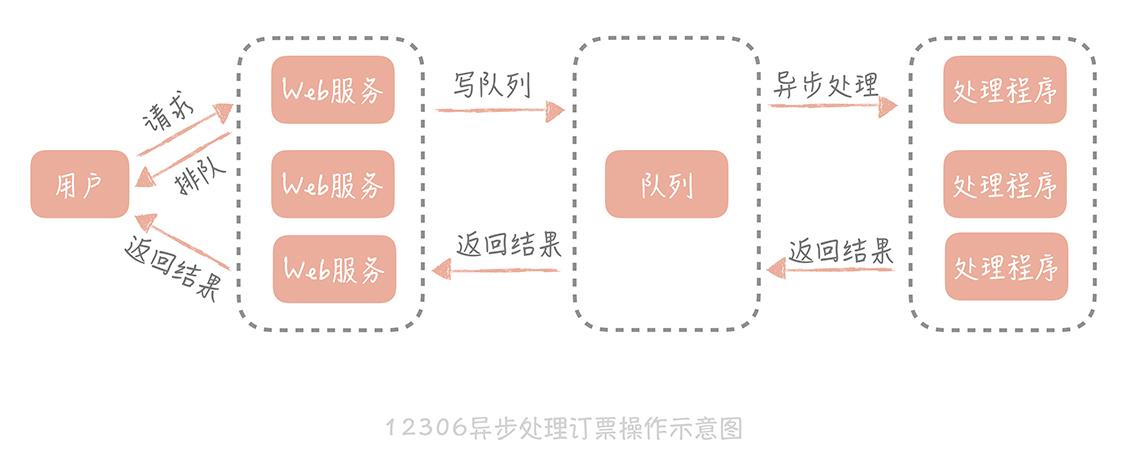
异步调用在大规模高并发系统中被大量使用,比如我们熟知的 12306 网站。当我们订票时,页面会显示系统正在排队,这个提示就代表着系统在异步处理我们的订票请求。采用异步的方式,后端处理时会把请求丢到消息队列中,同时快速响应用户,告诉用户我们正在排队处理,然后释放出资源来处理更多的请求。订票请求处理完之后,再通知用户订票成功或者失败。
处理逻辑后移到异步处理程序中,Web 服务的压力小了,资源占用的少了,自然就能接收更多的用户订票请求,系统承受高并发的能力也就提升了。
真实场景:这些方法都要用上吗?
为什么我说,缓存还没用上,其实那个分布也是我硬塞进去的。。。
不同量级的系统有不同的痛点,也就有不同的架构设计的侧重点。盲目地追从只能让我们的架构复杂不堪,最终难以维护。
一般系统的演进过程应该遵循下面的思路:
1、最简单的系统设计满足业务需求和流量现状,选择最熟悉的技术体系。
2、随着流量的增加和业务的变化,修正架构中存在问题的点,如单点问题,横向扩展问题,性能无法满足需求的组件。
在这个过程中,选择社区成熟的、团队熟悉的组件帮助我们解决问题,在社区没有合适解决方案的前提下才会自己造轮子。
3、当对架构的小修小补无法满足需求时,考虑重构、重写等大的调整方式以解决现有的问题。
以上是关于高并发:通用设计方法的主要内容,如果未能解决你的问题,请参考以下文章