超级攻略!PandasNumPyMatrix用于金融数据准备
Posted 程序员野客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超级攻略!PandasNumPyMatrix用于金融数据准备相关的知识,希望对你有一定的参考价值。
数据准备是一项必须具备的技术,是一个迭代且灵活的过程,可以用于查找、组合、清理、转换和共享数据集,包括用于分析/商业智能(BI)、数据科学/机器学习(ML)和自主数据集成中。具体来说,数据准备是在处理和分析之前对原始数据进行清洗和转换的过程,通常包括重新格式化数据、更正数据和组合数据集来丰富数据等。
本次数据分析实战系列运用股市金融数据,并对其进行一些列分析处理。处理金融数据是量化分析的基础,当然方法都是通用的,换做其他数据也同样适用。本文回顾数据分析常用模块Pandas和NumPy,回顾DataFrame、array、matrix 基本操作。
股市数据获取的几个模块
Tushare
Tushare是一个免费、开源的python财经数据接口包。主要实现对股票等金融数据从数据采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究与实现上。
首先使用pip安装第三方依赖库
tushare下载股市数据。(国内)
pip install tushare -i https://pypi.douban.com/simple/
然后在
tushare.pro注册用户,注意获取你自己的token。使用daily函数获取日线数据。
# 导入tushare库
import tushare as ts
# 设置token
ts.set_token('your token here')
# 初始化pro接口
pro = ts.pro_api()
# 获取日线数据
df = pro.daily(ts_code='000001.SZ', start_date='20180701', end_date='20180718'
Baostock
证券宝(http://www.baostock.com)是一个免费、开源的证券数据平台(无需注册)。提供大量准确、完整的证券历史行情数据、上市公司财务数据等。通过python API获取证券数据信息,满足量化交易投资者、数量金融爱好者、计量经济从业者数据需求。
首先使用pip安装第三方依赖库
baostock下载股市数据。(国内)
pip install baostock -i https://pypi.douban.com/simple/
然后使用
query_history_k_data_plus函数获取日线数据
import baostock as bs
import pandas as pd
# 登陆系统
lg = bs.login()
# 获取沪深A股历史K线数据
rs_result = bs.query_history_k_data_plus("sh.600000",
fields="date,open,high, low, close,preclose,volume,amount,adjustflag",
start_date='2017-07-01',
end_date='2017-12-31',
frequency="d",
adjustflag="3")
df_result = rs_result.get_data()
# 登出系统
bs.logout()
Yfinance
yfinance的老版本是fix_yahoo_finance,二者都可以使用,推荐使用新版本。
首先使用pip安装第三方依赖库
fix_yahoo_finance下载yahoo股市数据。(国外)
pip install fix_yahoo_finance -i https://pypi.douban.com/simple/
如果发生报错:ModuleNotFoundError: No module named 'yfinance',则需要事先安装'yfinance',最新版本已经将fix_yahoo_finance调整'yfinance'为
pip install yfinance -i https://pypi.douban.com/simple/
然后使用
pdr_override函数获取日线数据
import yfinance as yf
# 输入
symbol = 'AMD'
start = '2014-01-01'
end = '2018-08-27'
dataset=yf.pdr_override(symbol,start,end)
dataset.head()
下面开始本节主要内容,运用数据处理最常用的第三方模块Pandas和NumPy获取数据,为后续数据分析、机器学习做数据准备。
pandas
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
# Pandas Library
>>> import pandas as pd
>>> import warnings
>>> warnings.filterwarnings("ignore")
获取中国平安股票数据
>>> import baostock as bs
# 登陆系统
>>> lg = bs.login()
# 获取沪深A股历史K线数据
>>> rs_result = bs.query_history_k_data_plus("sh.601318",
fields="date,open,high,low,close,volume",
start_date='2018-01-01',
end_date='2021-03-31',
frequency="d",
adjustflag="3")
>>> df_result = rs_result.get_data()
# 登出系统
>>> bs.logout()
login success!
logout success!
<baostock.data.resultset.ResultData at 0x28d05a44ac8>
>>> df_result.head()
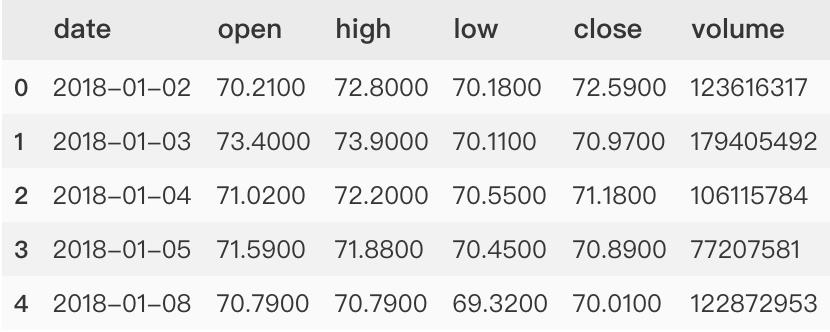
获取腾讯股票数据
>>> import yfinance as yf
>>> symbol = 'TCEHY'
>>> start = '2016-01-01'
>>> end = '2021-03-31'
>>> yf.pdr_override()
>>> dataset = yf.download(symbol,start,end)
[*********************100%***********************] 1 of 1 completed
>>> dataset.head()

查看尾部数据
dataset.tail()
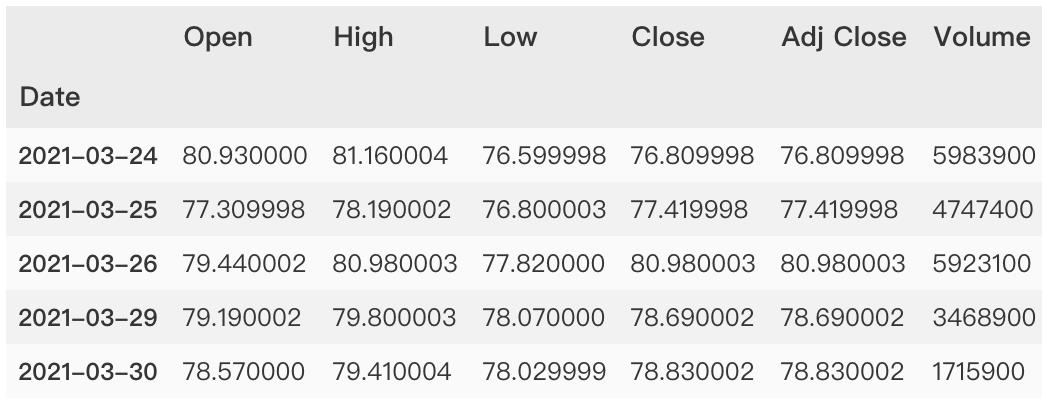
>>> dataset.shape
(1320, 6)
滚动窗口计算
dataset.rolling(window=5).mean() # 求最后4行的均值

函数解析
dataset.rolling(
window,
min_periods=None,
center=False,
win_type=None,
on=None,
axis=0,
closed=None,)
提供滚动窗口计算。
window:也可以省略不写。表示时间窗的大小,注意有两种形式(int or offset)。如果使用int,则数值表示计算统计量的观测值的数量即向前几个数据。 如果是offset类型,表示时间窗的大小。
min_periods:每个窗口最少包含的观测值数量,小于这个值的窗口结果为NA。值可以是int,默认None。offset情况下,默认为1。
center: 把窗口的标签设置为居中。布尔型,默认False,居右
win_type: 窗口的类型。截取窗的各种函数。字符串类型,默认为None。各种类型
on: 可选参数。对于dataframe而言,指定要计算滚动窗口的列。值为列名。
axis: int、字符串,默认为0,即对列进行计算
closed:定义区间的开闭,支持int类型的window。对于offset类型默认是左开右闭的即默认为right。可以根据情况指定为left both等。
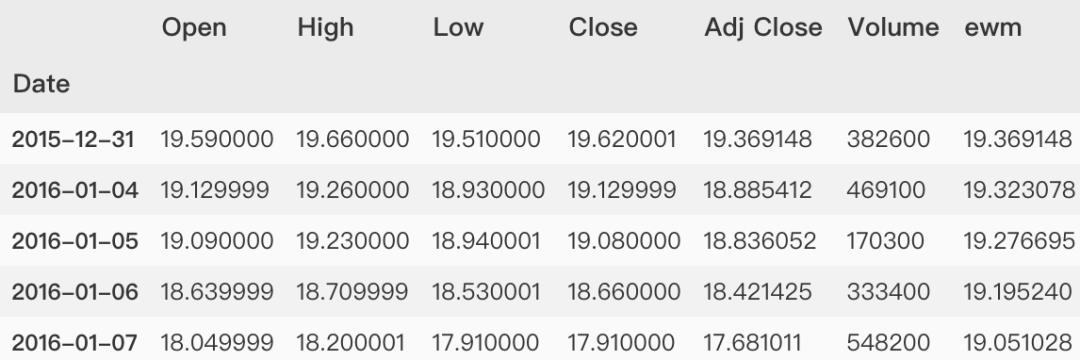
指数加权函数ewm
>>> dataset['ewm'] = dataset['Adj Close'].ewm(span=20,
min_periods=0,
adjust=False,
ignore_na=False).mean()
>>> dataset.head()
函数解析
DataFrame.ewm(com=None,
span=None,
halflife=None,
alpha=None,
min_periods=0,
adjust=True,
ignore_na=False,
axis=0,
times=None)
提供指数加权(EW)函数。可用EW功能:mean(),var(),std(),corr(),cov()。参数:com,span,halflife,或alpha必须提供。
com float, optional
根据质心指定衰减,
span float, optional
跨度,根据跨度指定衰减,
halflife float, str, timedelta, optional
半衰期,根据半衰期指定衰减,如果
times指定,则观察值衰减到其值一半的时间单位(str或timedelta)。仅适用于mean(),半衰期值不适用于其他功能。alpha float, optional
直接地指定平滑系数 ,
min_periods int, default 0
窗口中具有值的最小观察数(否则结果为NA)。adjust bool, default True
调整,在开始期间除以递减的调整因子,以解决相对权重的不平衡问题(将EWMA视为移动平均值)。
当
adjust=True(默认)时,EW功能是使用权重计算的 。例如,该系列的EW移动平均值 将会当
adjust=False为时,将以递归方式计算指数加权函数:
ignore_na bool, default False
计算权重时忽略缺失值;指定True重现0.15.0之前的行为。
当
ignore_na=False(默认)时,权重基于绝对位置。例如,权重 和 用于计算 的最终加权平均数,如果adjust=True,则权重分别是 和 1。如果adjust=False,权重分别是