带头结点与不带头节点的几点区别
Posted 日月既往、不复可追。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带头结点与不带头节点的几点区别相关的知识,希望对你有一定的参考价值。
下面我们讲下具体带头结点和不带头结点的一个情况。
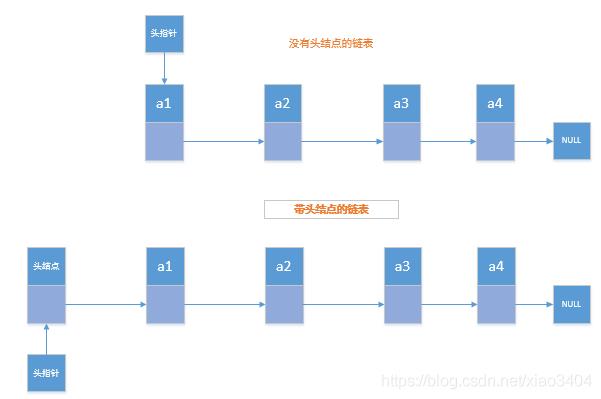
头指针:通常使用“头指针”来标识一个链表,如单链表L,头指针为NULL的时表示一个空链表。链表非空时,头指针指向的是第一个结点的存储位置。
头结点:在单链表的第一个结点之前附加一个结点,称为头结点。头结点的Data域可以不设任何信息,也可以记录表长等相关信息。若链表是带有头结点的,则头指针指向头结点的存储位置。
无论是否有头结点,头指针始终指向链表的第一个结点。如果有头结点,头指针就指向头结点(只不过头结点的数据域为
第一点:
不带头节点: p1->p2->p3 ->p1->p2->p3-> p1…
我们先创建头指针,初始化的时候只需要将头指针赋NULL就可以了;大家想想,如果在这种情况下,我们进行头删操作,最后一步必须得做的事就是: 更新头指针的指向。
或者换句话说,一旦对首元节点(头指针指向首元结点)进行操作,首尾工作必定得进行更新。
带头节点:head-> p1->p2->p3 ->p1->p2->p3-> p1…
与上边相反,每次进行涉及到首元结点的操作后,更新的过程就会很简单。我们不需要再去移动头指针,只需要固定的更新头结点中的指针域就可以了。
第二点:
再者,带头节点可以方便,快速的定位链表第1个节点。
比如循环链表的时候,删除p1 的时候:
head->next = p2;
p3->next = head->next;
free(p1);
思路很清晰,链表开始的第1个节点现在就是head->next 即 p2
否则没有头节点:
p3->next = p1->next;
free(p1);
会不会有一种链表第1个节点到底是哪个的感觉?
第三点:
不带头结点的单链表对于第一个节点的操作与其他节点不一样,需要特殊处理,这增加了程序的复杂性和出现bug的机会,因此,通常在单链表的开始结点之前附设一个头结点
以上是关于带头结点与不带头节点的几点区别的主要内容,如果未能解决你的问题,请参考以下文章