真棒!5 个 Python 技巧让我的数据科学工作更轻松!
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了真棒!5 个 Python 技巧让我的数据科学工作更轻松!相关的知识,希望对你有一定的参考价值。
数据科学的主要工作就是分析数据,从数据中挖掘潜在业务价值,在本文中,我将给大家分享在工作中学到的5个技巧,这些技巧对我提高工作效率很有帮助。希望这些能对你的旅程有所帮助。
我们开始吧!
1、基于Pandas的时间序列数据处理
如果你使用时间序列数据,很可能花费大量时间来处理丢失的记录,可以通过编写自定义函数以特定的时间粒度聚合数据。Pandas 有一个非常有效的 resample 函数,它可以帮助我们以特定的频率处理数据,只需将 DataFrame 索引设置为 timestamp 列。
我将使用"占用检测数据集"给出此函数的示例,这个数据集以分钟为单位记录观察结果。
数据集地址为:https://archive.ics.uci.edu/ml/datasets/Occupancy+Detection+
import pandas as pd
data = pd.read_csv('occupancy_data/datatest.txt').reset_index(drop = True)
data.head(5)
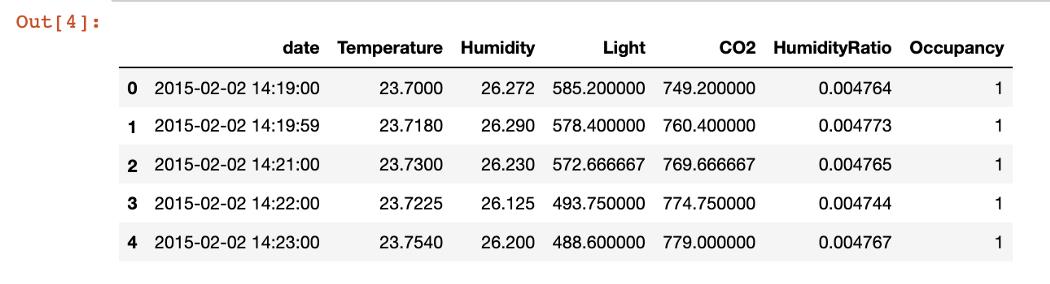
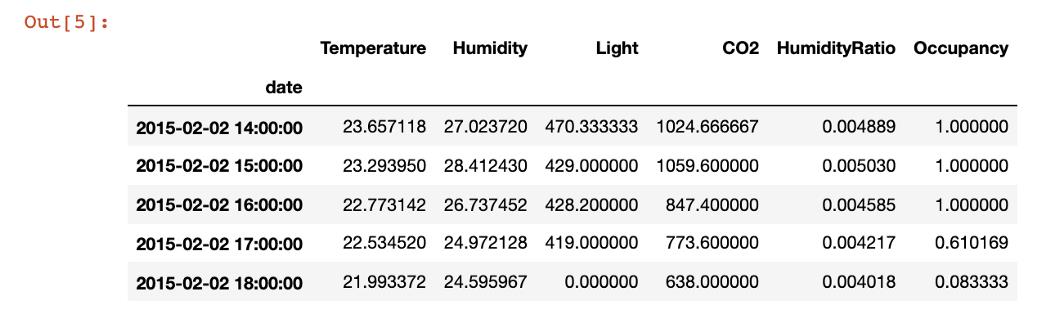
首先,我展示了一个简单的聚合,可以在每小时一次的级别上获取度量。
data.index = pd.to_datetime(data['date'])
pd.DataFrame(data.resample('H').agg({'Temperature':'mean','Humidity':'mean','Light':'last','CO2':'last','HumidityRatio' : 'mean','Occupancy' : 'mean'})).head(5)
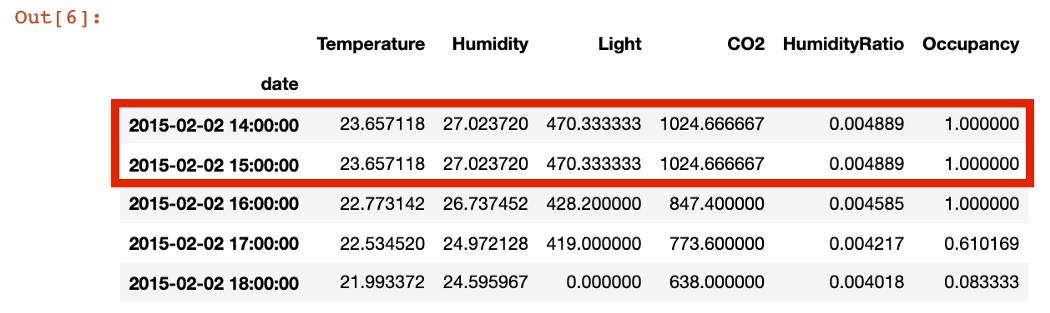
在现实场景中,人们经常会遇到缺少记录的数据。考虑这些记录很重要,可能需要输入0,或者使用上一个或下一个时间步骤进行插补。下面,我删除了15小时的记录,以显示如何使用14小时的时间戳来插补丢失的值:
data = pd.read_csv('occupancy_data/datatest.txt').reset_index(drop = True)
data_missing_records = data[~(pd.to_datetime(data.date).dt.hour == 15)].reset_index(drop = True)
data_missing_records.index = pd.to_datetime(data_missing_records['date'])
data_missing_records.resample('H', base = 1).agg({'Temperature':'mean','Humidity':'mean','Light':'last','CO2':'last','HumidityRatio' : 'mean','Occupancy' : 'mean'}).fillna(method = 'ffill').head(5)
2、通过Plotly Express快速可视化
从分析到模型训练再到模型报告,通常都需要可视化。特别是对于时间序列图,我通常需要花很多时间在作图上。
在我改用 plotly express 之后,我把制作图形的时间减少了70%。如果我想在视觉效果中实现特定的细节,我仍然可以使用 Plotly Graph 对象来实现。
此外,Plotly 还提供了许多简单的选项,例如在绘图中设置组颜色,从而产生更强大的可视化效果。
import plotly.express as px
data['Temp_Bands'] = np.round(data['Temperature'])
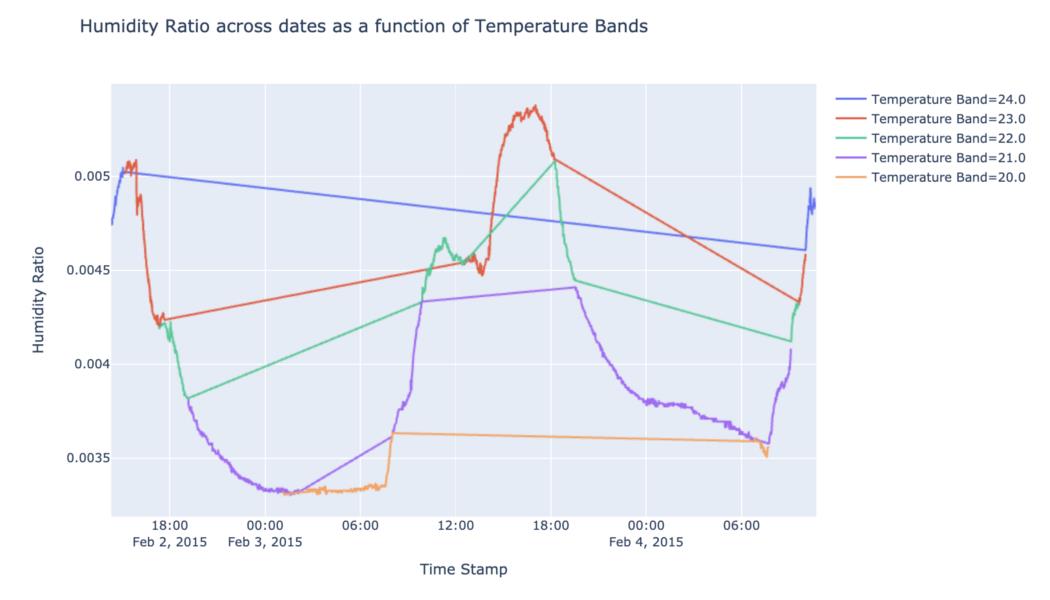
fig = px.line(data, x = 'date',y = 'HumidityRatio',color = 'Temp_Bands',title = 'Humidity Ratio across dates as a function of Temperature Bands',labels = {'date' : 'Time Stamp','HumidityRatio' : 'Humidity Ratio','Temp_Bands' : 'Temperature Band'})
fig.show()
使用上面提到的数据集,我使用 plotly express 创建带有颜色分组的线图。我们可以看到用两个函数创建这些图是多么容易。
3、通过Swifter加速
有时会遇到等待很长时间来处理这些列,即使是在一个有大实例的笔记本上运行代码。相反,有一个简单的做法,可以用来加速数据帧中的apply功能。
def custom(num1, num2):
if num1 > num2:
if num1 < 0:
return "Greater Negative"
else:
return "Greater Positive"
elif num2 > num1:
if num2 < 0:
return "Less Negative"
else:
return "Less Positive"
else:
return "Rare Equal"
import swifter
import pandas as pd
import numpy as np
data_sample = pd.DataFrame(np.random.randint(-10000, 10000, size = (50000000, 2)), columns = list('XY'))
我创建了一个5000万行的数据帧,并比较了通过swifter apply()和vanilla apply()处理它所花费的时间。我还创建了一个带有简单if-else条件的虚拟函数来测试这两种方法。
results_arr = data_sample.apply(lambda x : custom(x['X'], x['Y']), axis = 1)

results_arr = data_sample.swifter.apply(lambda x : custom(['X'], x['Y']), axis = 1)

我们能够将处理时间从7分53秒减少到2分38秒,减少64.4%。
####4、Python中的多处理
在 python 中使用多处理可以通过使用多个worker来帮助我节省时间。我使用上面创建的5000万行数据帧演示了多处理的有效性。
import pandas as pd
import numpy as np
import random
string = 'AEIOU'
data_sample = pd.DataFrame(np.random.randint(-10000, 10000, size = (50000000, 2)), columns = list('XY'))
data_sample['random_char'] = random.choices(string, k = data_sample.shape[0])
unique_char = data_sample['random_char'].unique()
我使用 concurrent.futures 中的 for 循环和进程池执行器来演示我们可以实现的运行时缩减。
arr = []
for i in range(len(data_sample)):
num1 = data_sample.X.iloc[i]
num2 = data_sample.Y.iloc[i]
if num1 > num2:
if num1 < 0:
arr.append("Greater Negative")
else:
arr.append("Greater Positive")
elif num2 > num1:
if num2 < 0:
arr.append("Less Negative")
else:
arr.append("Less Positive")
else:
arr.append("Rare Equal")

def custom_multiprocessing(i):
sample = data_sample[data_sample['random_char'] == unique_char[i]]
arr = []
for j in range(len(sample)):
if num1 > num2:
if num1 < 0:
arr.append("Greater Negative")
else:
arr.append("Greater Positive")
elif num2 > num1:
if num2 < 0:
arr.append("Less Negative")
else:
arr.append("Less Positive")
else:
arr.append("Rare Equal")
sample['values'] = arr
return sample
我创建了一个函数,允许我分别处理每个元音分组:
import concurrent
def main():
aggregated = pd.DataFrame()
with concurrent.futures.ProcessPoolExecutor(max_workers = 5) as executor:
results = executor.map(custom_multiprocessing, range(len(unique_char)))
if __name__ == '__main__':
main()

我们看到CPU时间减少了99.3%。尽管必须记住小心使用这些方法,因为它们不会序列化输出,因此通过分组使用它们是利用此功能的好方法。
5、MASE
随着使用机器学习和深度学习方法进行时间序列预测的兴起,有必要使用一个度量,而不仅仅是基于预测值和实际值之间的距离。
预测模型的度量应该使用时间趋势的误差来评估模型的性能,而不仅仅是时间点误差估计。我们将模型误差与原始预测误差进行了比较。
def MASE(y_train, y_test, pred):
naive_error = np.sum(np.abs(np.diff(y_train)))/(len(y_train)-1)
model_error = np.mean(np.abs(y_test - pred))
return model_error/naive_error
如果 MASE>1,则模型的性能比随机游走差。MASE越接近于0,预测模型就越好。
总结
在本文中,我介绍了一些经常使用的技巧,这些技巧可以让我们的工作更轻松。如果你有更好、更棒的技巧,请在评论区告诉我!
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友超过2000人,添加方式如下:
如下方式均可,添加时最好方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式一、发送如下图片至微信,进行长按识别,回复加群;
- 方式二、直接添加小助手微信号:pythoner666,备注:来自CSDN
- 方式三、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于真棒!5 个 Python 技巧让我的数据科学工作更轻松!的主要内容,如果未能解决你的问题,请参考以下文章