10000+ gif表情包不是梦,get这一篇文就够了!!!小哥哥快到碗里来,再也不怕斗图没有表情包了
Posted 程序媛一枚~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了10000+ gif表情包不是梦,get这一篇文就够了!!!小哥哥快到碗里来,再也不怕斗图没有表情包了相关的知识,希望对你有一定的参考价值。
10000+ gif表情包不是梦,get这一篇文就够了!!!小哥哥快到碗里来,再也不怕斗图没有表情包了

最近看的爬虫的博客太多,小小的学习了下。主要是http请求,分析网页的http请求拼接(分页),返回值html 或者json的解析(用到正则表达式re或者json模块);
先上一张成果图:
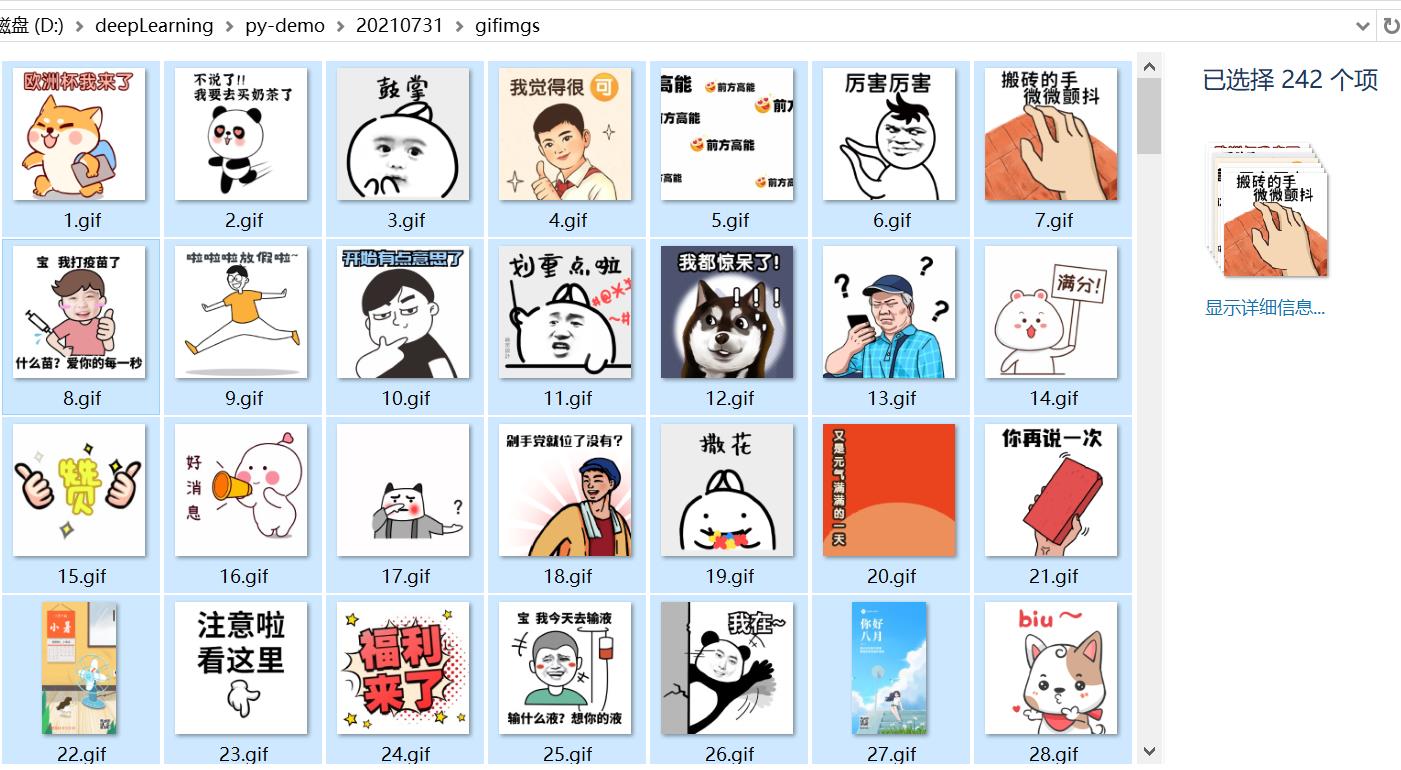


1. 依赖模块及安装
pip install request
pip install json
pip install re
2. 查找网页规律
主要是:寻找分页规律 & 返回值规律 & 找到返回值的gif的真实路径
https://www.gaoding.com/api/aggregate/search?q=&page_size=120&page_num=1&design_cid=&channel_cid=&industry_cid=&filter_id=1612599&type_filter_id=1612599&channel_filter_id=&channel_children_filter_id=&sort=&styles=&colors=&ratios=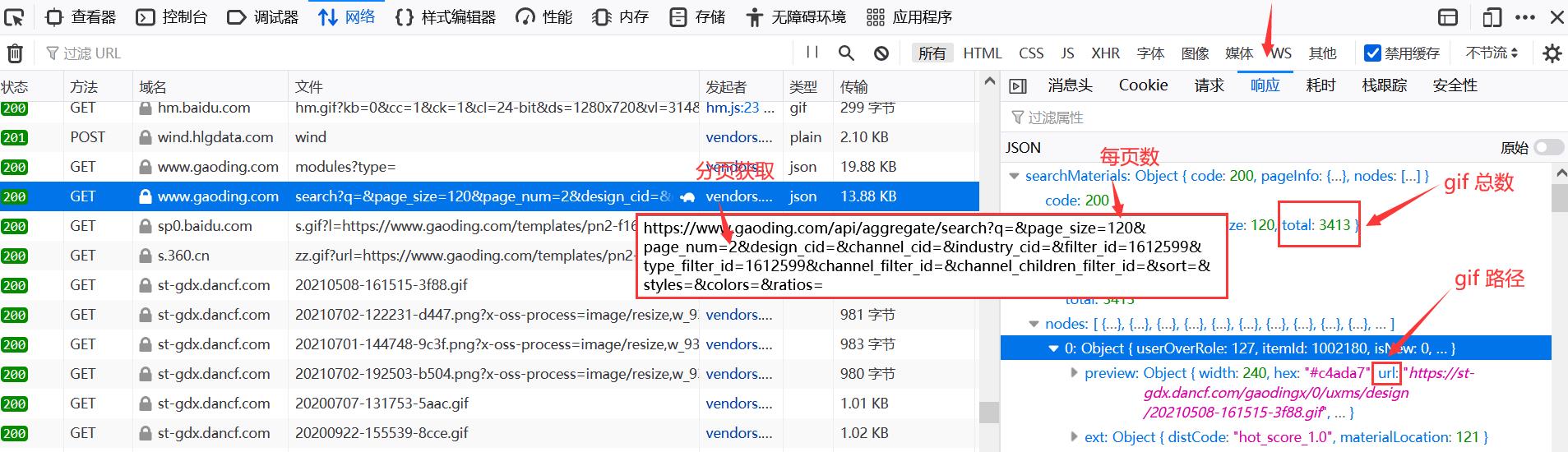 运行效果如下图:
运行效果如下图:
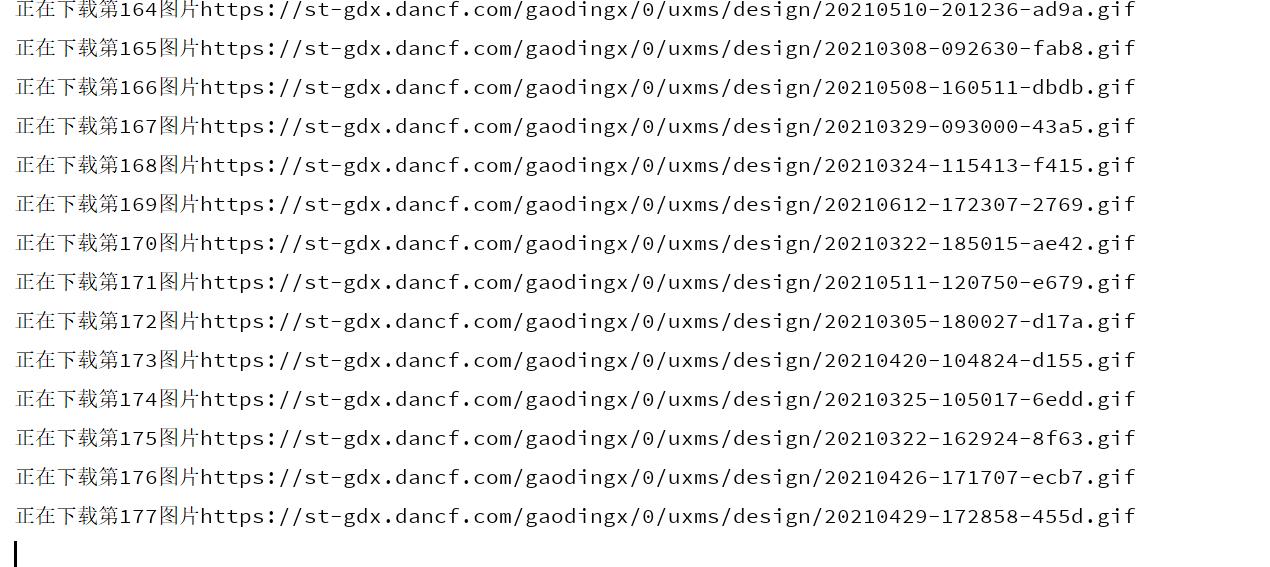 再也不怕斗图没有表情包了,欧耶~~
再也不怕斗图没有表情包了,欧耶~~
3. 源码
# url = 'https://www.gaoding.com/templates/f1612599' 网站获取动图gif
# -*- coding:utf-8 -*-
import json
import requests
def getGifUrls():
alist = []
for i in range(1, 20, True):
url_page = 'https://www.gaoding.com/api/aggregate/search?q=&page_size=120&page_num=' + str(
i) + '&design_cid=&channel_cid=&industry_cid=&filter_id=1612599&type_filter_id=1612599&channel_filter_id=&channel_children_filter_id=&sort=&styles=&colors=&ratios='
print(url_page)
# 设置请求超时(20s)
r = requests.get(url_page, timeout=20)
if r.status_code == requests.codes.ok:
print('=== status_code === ', r.status_code) # 响应码
print('=== headers === ', r.headers) # 响应头
print('=== Content-Type === ', r.headers.get('Content-Type')) # 获取响应头中的Content-Type字段
# 解析数据
r.encoding = 'utf-8'
print('content: ', type(r.text))
f = open("./gifimgs/gif-" + str(i) + "-out.json", "w", encoding='utf-8')
f.write(r.text)
f.close()
data2 = json.loads(r.text)
print(type(data2))
materials = data2['searchMaterials']
# print(type(materials))
# print(materials['code'])
pageTotal = materials['pageInfo']['total']
pageNum = materials['pageInfo']['num']
pageSize = materials['pageInfo']['size']
print(pageNum, pageSize, pageTotal)
nodes = materials['nodes']
print('nodes: ', type(nodes))
result = [i['preview']['url'] for i in nodes]
# for i, d in enumerate(nodes):
# print(d['preview']['url'])
# gif = d['preview']['url']
# 打印gif的地址及数
print(str(i), 'gif数:', len(result))
print(str(i), 'gif0:')
print(result[0])
alist.extend(result)
else:
r.raise_for_status() # 抛出异常
return alist
def saveGifs(urls):
num = 1
for gif in urls:
# 设置请求超时(20s)
r = requests.get(gif, timeout=20)
if r.status_code == requests.codes.ok:
with open('./gifimgs/%d.gif' % num, 'wb') as fin:
fin.write(r.content) # 写入图片二进制
print('正在下载第%d图片' % num + gif)
num += 1
else:
r.raise_for_status() # 抛出异常
list = getGifUrls()
giflist = saveGifs(list)
以上是关于10000+ gif表情包不是梦,get这一篇文就够了!!!小哥哥快到碗里来,再也不怕斗图没有表情包了的主要内容,如果未能解决你的问题,请参考以下文章