.Net EF Core千万级数据实践
Posted Stacking
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.Net EF Core千万级数据实践相关的知识,希望对你有一定的参考价值。
.Net 开发中操作数据库EF一直是我的首选,工作和学习也一直在使用。EF一定程度的提高了开发速度,开发人员专注业务,不用编写sql。方便的同时也产生了一直被人诟病的一个问题性能低下。
EF Core + mysql的组合越来越流行,所以本文数据库使用MySql完成相关示例。
说明
由于工作中也一直使用Sql Server,所以记录这篇文章时也学习了很多MySql的内容。
MySql安装,打开官网(https://dev.mysql.com/downloads/installer/)下载安装。
示例项目说明:
.Net 5.0 + 最基本的 EF Code First 模型。两个Entity,分别为Order和OrderItem。
数据库:
Order数据量500W
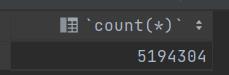
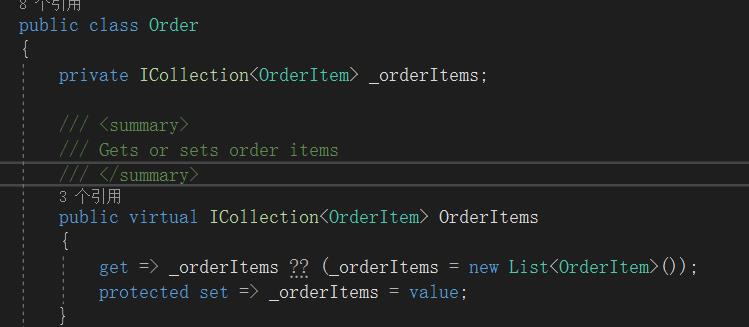
Order实体除了基本字段定义还定义了一个OrderItems
OrderItems数据量800W
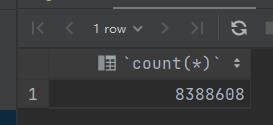
OrderItem定义了一个Order virtual 属性
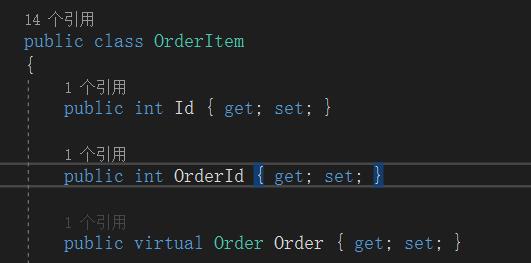
并在实体和表映射是定义了外键关联

正常系统中单表最大可能就千万级数据,数据再多便会考虑分表,所以最初设想是单个表准备1000W+的数据,但是没有考虑到我这个老年笔记本,所以实际操作时数据做了适当减少。
MySql记录
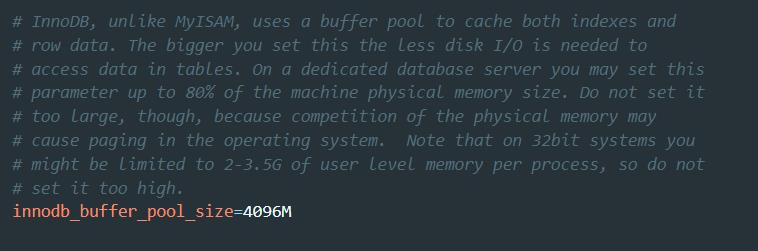
准备好测试数据后写了一些简单的SQL查询来做测试,一些稍微复杂点的查询耗时就十秒、二十秒。此时应该从数据库的优化入手,优化EF查询不能解决我们的问题。优化MySql查询和排序最简单有效的办法就是创建索引,根据业务需求合理的创建索引,保证索引的命中(最左原则),还要设置一个足够大的innodb-buffer-pool-size。
参考文章
必须掌握的 MySQL 优化原理:https://mp.weixin.qq.com/s/wuGbnvo3bCThO2ERqHpPAQ
MySQL 性能优化的21条实用技巧:https://mp.weixin.qq.com/s/pyAddBuxjodmT7gkOBamTw
深入理解MySQL索引之B+Tree:https://blog.csdn.net/b_x_p/article/details/86434387
MySql最左匹配原则解析:https://www.cnblogs.com/wanggang0211/p/12599372.html
日志记录和诊断
项目中添加了两种方式查看EF生成的SQL和执行耗时。做一下简单说明实际开发中可自行选择。
Microsoft.Extensions.Logging
确保项目安装了Microsoft.Extensions.Logging包。
添加一个ILoggerFactory类型静态属性
public static readonly ILoggerFactory MyLoggerFactory = LoggerFactory.Create(builder => { builder.AddConsole(); });
EF Core 注册此实例
options.EnableSensitiveDataLogging()
.UseLoggerFactory(MyLoggerFactory)
.EnableDetailedErrors()
MiniProfile
安装MiniProfiler.AspNetCore.Mvc包
Startup的ConfigureServices方法增加代码
services.AddMiniProfiler(options => { // All of this is optional. You can simply call .AddMiniProfiler() for all defaults // (Optional) Path to use for profiler URLs, default is /mini-profiler-resources options.RouteBasePath = "/profiler"; // (Optional) Control which SQL formatter to use, InlineFormatter is the default options.SqlFormatter = new StackExchange.Profiling.SqlFormatters.InlineFormatter(); // (Optional) You can disable "Connection Open()", "Connection Close()" (and async variant) tracking. // (defaults to true, and connection opening/closing is tracked) options.TrackConnectionOpenClose = true; // (Optional) Use something other than the "light" color scheme. // (defaults to "light") options.ColorScheme = StackExchange.Profiling.ColorScheme.Auto; // The below are newer options, available in .NET Core 3.0 and above: // (Optional) You can disable MVC filter profiling // (defaults to true, and filters are profiled) options.EnableMvcFilterProfiling = true; // ...or only save filters that take over a certain millisecond duration (including their children) // (defaults to null, and all filters are profiled) // options.MvcFilterMinimumSaveMs = 1.0m; // (Optional) You can disable MVC view profiling // (defaults to true, and views are profiled) options.EnableMvcViewProfiling = true; // ...or only save views that take over a certain millisecond duration (including their children) // (defaults to null, and all views are profiled) // options.MvcViewMinimumSaveMs = 1.0m; }).AddEntityFramework();
Startup的Configure方法增加如下代码
app.UseMiniProfiler();
_ViewImports.cshtml文件中添加引用和对应taghelper
@using StackExchange.Profiling
@addTagHelper *, MiniProfiler.AspNetCore.Mvc
在视图文件中添加MiniProfiler
<mini-profiler />
.Net Core 5 提供了IQueryable的ToQueryString()方法可以直接获取Linq查询对应的SQL语句。
查询数据
先说明两个实例中没有出现的基本查询优化方案
1.大表避免整表返回(sql中的select *),简化查询实体仅返回业务需要的字段,返回多个字段时可以将Select查询映射到匿名类。
2.如果只是单纯的获取列表不需要更新从数据库中检索到的实体,应使用AsNoTracking方法设置非跟踪查询,无需设置更改跟踪信息(EF 在内部维护跟踪实例的字典),更快速地执行查询。
Find
示例中实现两个方法 GetByIdAsync和GetByIdFromSql,实现如下
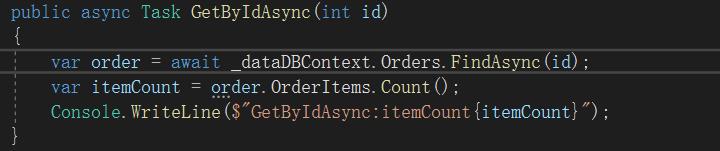

启动项目看到如下输出:
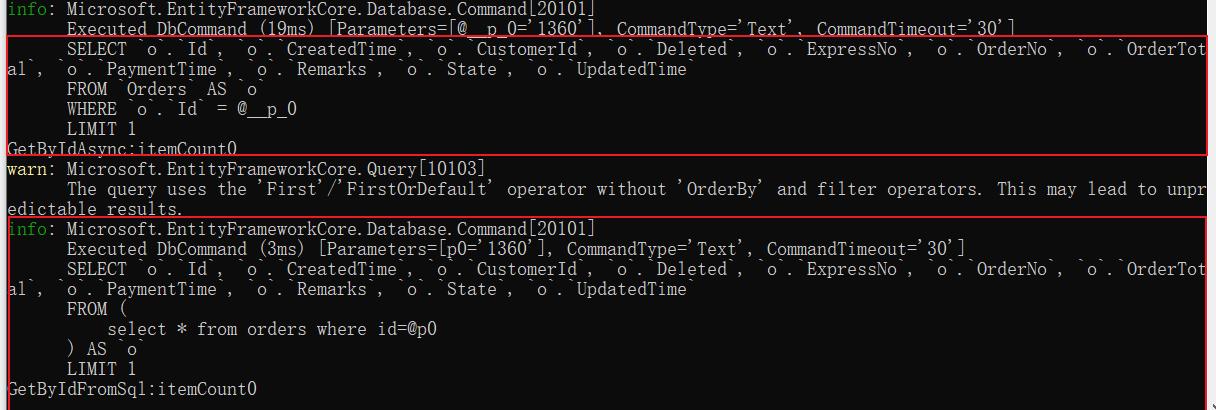
EF的Find方法生成了一个简单的sql语句执行耗时19ms,反而通过FromSqlInterpolated调用自己写的SQL却生成一个看着怪异的sql语句,执行耗时3ms。MiniProfiler中查看耗时差不多
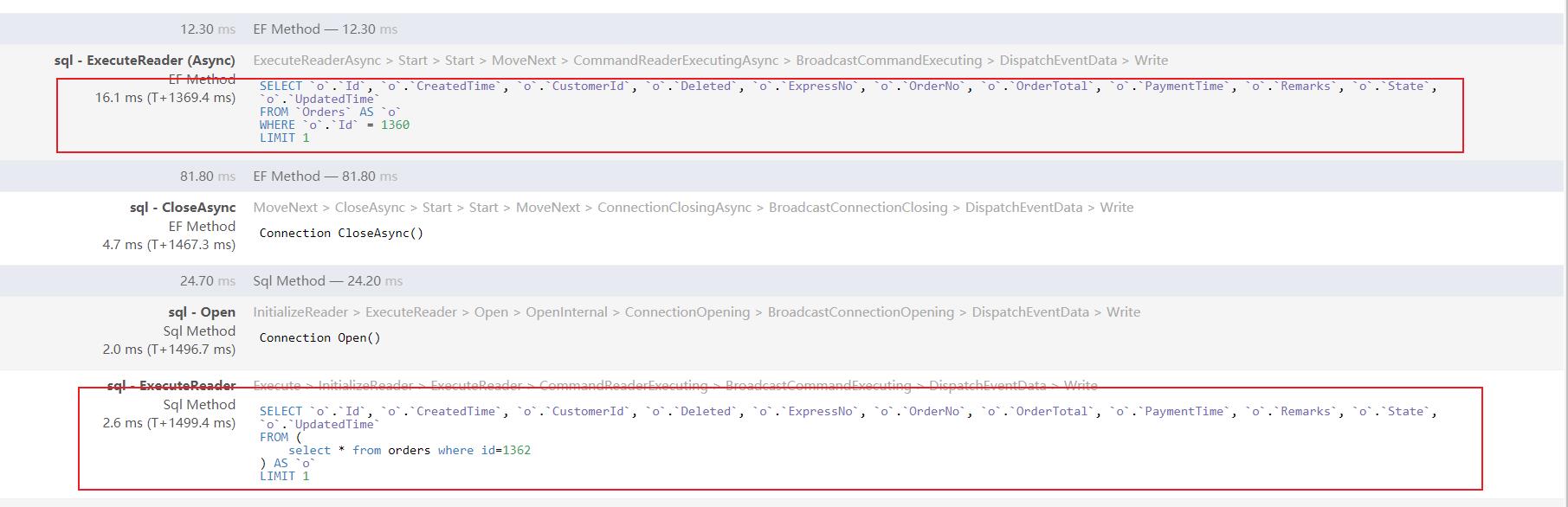
两个SQL耗时不应该有这么大的差距,把两个SQL复制到数据库中执行时发现两个SQL执行时间基本相同,说明调用EF方法EF到SQL的转换耗时也计算在内,因为EF的缓存机制再次调用时发现两个方法的耗时基本持平。
两种方式返回的Order中OrderItems数量为零,解决这个问题就涉及到EF加载相关数据的知识。
这里演示预先加载和延迟加载两种方式
预先加载
修改GetByIdAsync代码:
var order = await _dataDBContext.Orders.Include(a => a.OrderItems).FirstOrDefaultAsync(a => a.Id == id);
此时EF生成的代码就会关联查询OrderItem,EF生成SQL如下
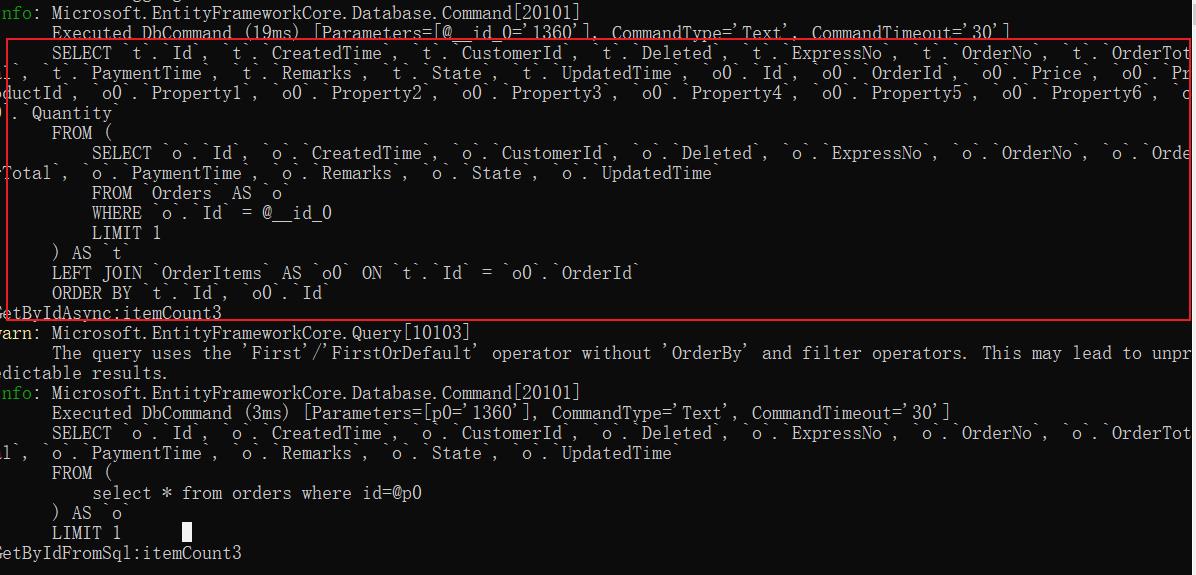
查看打印的log会发现一个问题,我们修改EF代码为预先加载,SQL查询生成的SQL相同却会关联查询出OrderItems的数据。
再次修改代码

并修改GetByIdFromSql方法参数为1362(之前和GetByIdAsync参数一样为1360),运行
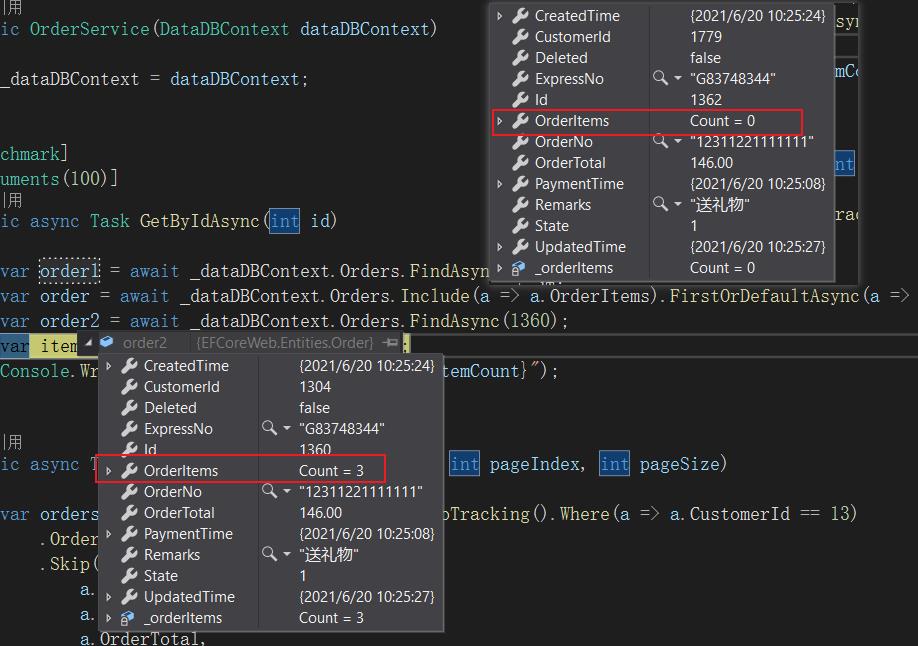
同样是Find查找,1362对应的OrderItems为空,1360对应的OrderItems的Count却为3,对应Sql查询的1362的OrderItems也为空。应该是EF的缓存机制造成的这种情况,有兴趣和精力的可以查看一下EF Core的源码。
延时加载
AddDbContext时增加UseLazyLoadingProxies方法调用
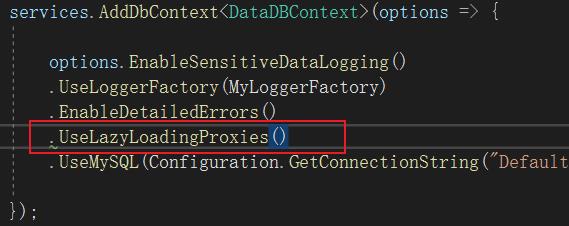
此时不管是EF的Find还是原始SQL都能查询出OrderItems的值。
查询结果集及外键关联数据
定义如下方法查询结果为某个用户订单及关联数据
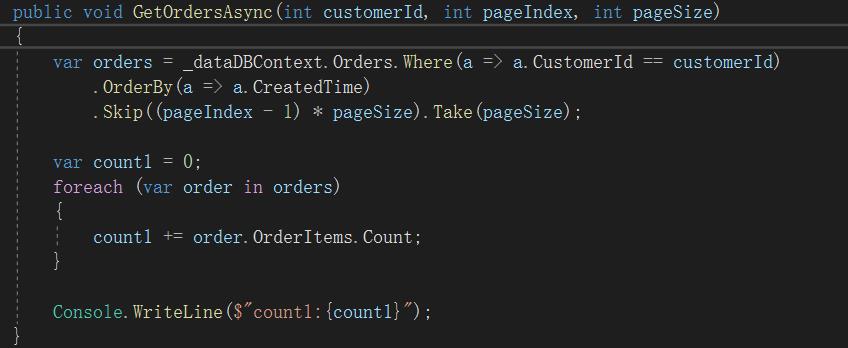
运行代码,会遇到使用EF时经常遇到的一个错误

因为获取orders时已经建立一个连接,当我们循环orders获取OrderItems时(当前设置为延时加载)需要在建立连接从而引发这个异常。修改代码通过ToList来避免这个异常

此时可以正常获取OrderItems的数据,通过MiniProfiler查看生成的sql
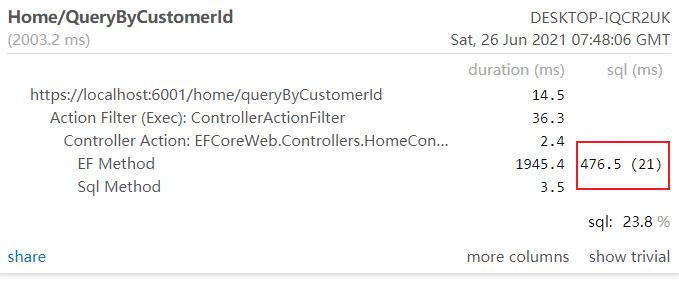
这个EF方法生成了21(1条查询orders+20条延时查询orderitems)条sql。再次修改代码,改为预先加载的方式,查询Order的同时返回OrderItems数据。
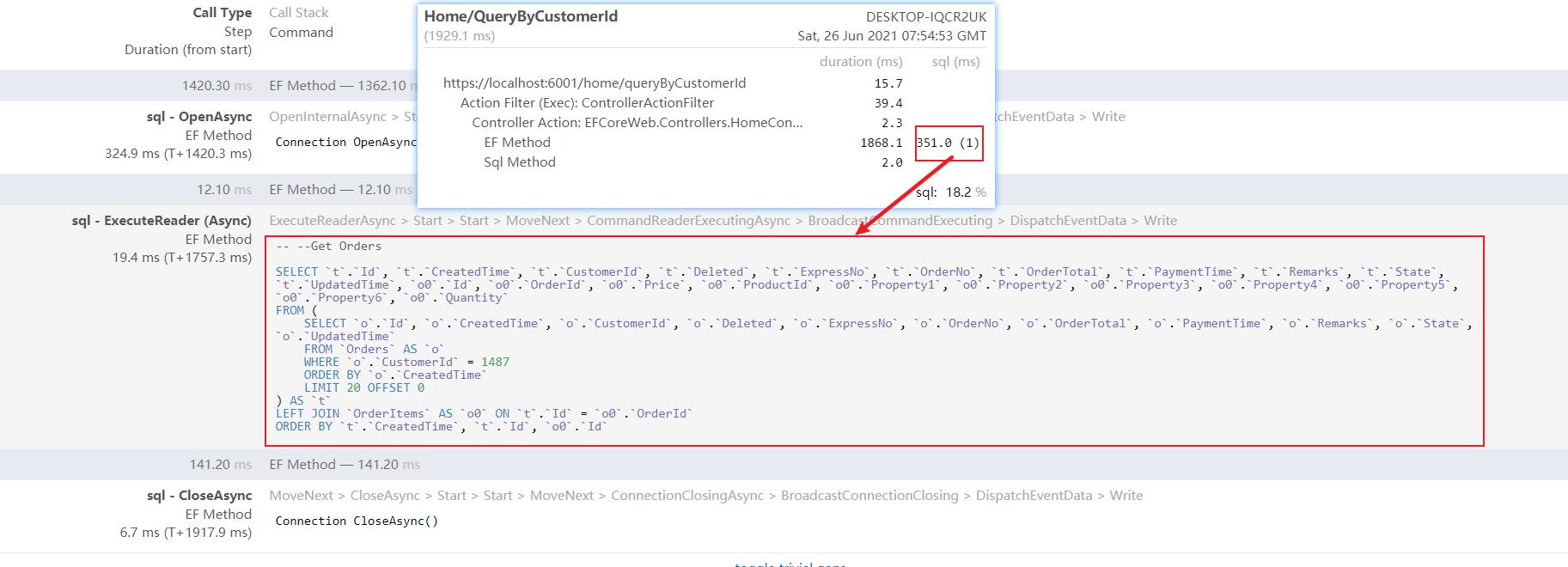
EF生成的sql从21条变为1条。
拆分查询
EF Core 5.0 中引入拆分查询功能以避免“笛卡尔爆炸”问题,可以将指定 LINQ 查询拆分为多个 SQL 查询,仅在使用 Include 时可用。
单个EF查询调用AsSplitQuery方法启用拆分查询。也可以全局启用拆分查询,在设置应用程序数据库连接上下文时调用UseQuerySplittingBehavior开启全局拆分。
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder) { optionsBuilder .UseSqlServer( @"Server=(localdb)\\mssqllocaldb;Database=EFQuerying;Trusted_Connection=True;ConnectRetryCount=0", o => o.UseQuerySplittingBehavior(QuerySplittingBehavior.SplitQuery)); }
设置拆分查询为默认的查询方式后,可以再调用AsSingleQuery方法指定具体的EF查询为单个查询模式。
为了测试这个功能我又添加了一张Customer表,修改代码如下:
public async Task GetOrdersAsync(int customerId, int pageIndex, int pageSize) { var order = await _dataDBContext.Orders.Where(a => a.CustomerId == customerId) .OrderBy(a => a.CreatedTime) .Skip((pageIndex - 1) * pageSize).Take(pageSize) .Include(a => a.OrderItems).Include(a => a.Customer) .TagWith("--Get Orders").AsSplitQuery().FirstOrDefaultAsync(); var orders = await _dataDBContext.Orders.Where(a => a.CustomerId == customerId) .OrderBy(a => a.CreatedTime) .Skip((pageIndex - 1) * pageSize).Take(pageSize) .Include(a => a.OrderItems).Include(a => a.Customer) .TagWith("--Get Orders").AsSplitQuery().ToListAsync(); var count1 = 0; foreach (var _order in orders) { count1 += order.OrderItems.Count; } Console.WriteLine($"count1:{count1}"); }
上面并不是一个能正常执行的代码,抛出异常MySql.Data.MySqlClient.MySqlException (0x80004005): There is already an open DataReader associated with this Connection which must be closed first。
Github的issues提到这个问题,拆分查询需要开启Sql Server的MARS(MultipleActiveResultSets=true)。但是MySql不持支MARS,目前我不知道如何在MySql下正常运行AsSplitQuery的代码。
拆分查询当前实现执行为每个查询的往返(类似延时加载), 这个将来会修改为单次往返中执行所有查询。
更新数据
EF Core 默认情况下,仅在单个批处理中执行最多42条语句,可以调整这些阈值实现可能更高的性能,但在修改之前应进行基准测试确保有更高的性能。
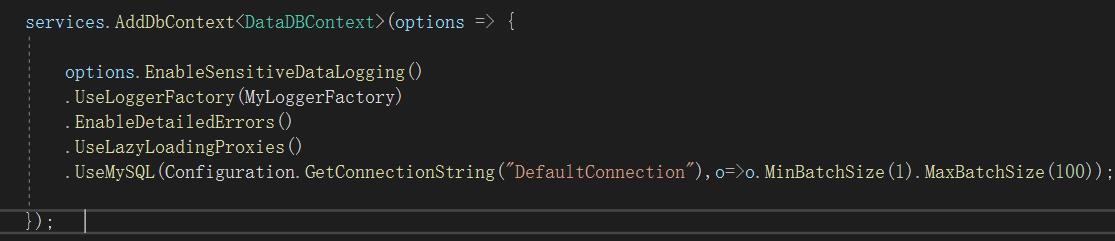
摘自官网的一个段示例说明
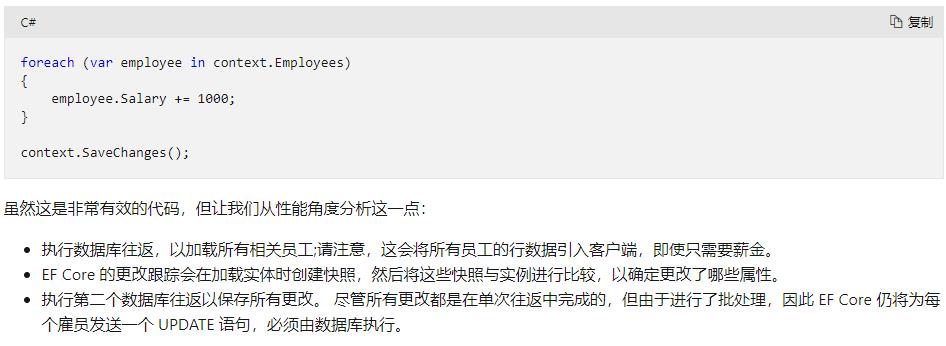
很遗憾EF目前还不支持批量更新和删除操作,官网也给出了优化方案,用原始SQL来执行:
context.Database.ExecuteSqlRaw("UPDATE [Employees] SET [Salary] = [Salary] + 1000");
B站活跃用户杨中科老师的一篇文章也有介绍:https://www.bilibili.com/read/cv8545714
但是复杂的更新业务写SQL同样是让人头疼的一件事,不想写一行SQL语句,又想实现批量更新和删除操作可以借助第三方库Zack.EFCore.Batch或Z.EntityFramework.Extensions.EFCore(https://entityframework-extensions.net)。
性能提升
DbContext 池
AddDbContextPool 启用可重用上下文实例的池,上下文池可以重复使用上下文实例,而不用每个请求创建新实例,从而提高大规模方案(如 web 服务器)的吞吐量。在请求上下文实例时,EF 首先检查池中是否有可用的实例。 请求处理完成后,实例的任何状态都将被重置,并且实例本身会返回池中。
services.AddDbContextPool<BloggingContext>(options => options.UseSqlServer(connectionString));
poolSize 参数 AddDbContextPool 设置池保留的最大实例数 中128。 一旦 poolSize 超出,就不会缓存新的上下文实例,EF 会回退到按需创建实例的非池行为。
上下文池的工作方式是跨请求重复使用同一上下文实例。 上下文池适用于上下文配置(包括解析的服务)在请求之间固定的场景。 对于需要作用域服务或需要更改配置的情况,请勿使用池。 池的性能提升通常很小,仅在高度优化的方案中采用。
预编译查询
执行普通Linq查询的时会执行一次Compile,虽然EF对查询的Linq有缓存机制,但是编译的查询比自动缓存的 LINQ 查询效率更高。对于多次执行结构类似的查询可以通过预编译,仅编译查询一次并在每次执行时使用不同参数的方法来提高性能。
示例代码:
Func<DataDBContext, decimal, IQueryable<int>> errorCompiled = EF.CompileQuery<DataDBContext, decimal, IQueryable<int>>( (ctx, total) => ctx.OrderItems.AsNoTracking().IgnoreAutoIncludes() .GroupBy(a => a.ProductId).Select(a => new { ProductId = a.Key, Quantity = a.Sum(b => b.Quantity), Price = a.Sum(b => b.Price), }).Where(a => a.Price > total).Select(a => a.ProductId));
由于EF Core 5.0 增加了单个查询和拆分查询的概念,返回的类型为SingleQueryingEnumerable,上面的代码抛出Expression of type \'Microsoft.EntityFrameworkCore.Query.Internal.SingleQueryingEnumerable`1[System.Int32]\' cannot be used for return type \'System.Linq.IQueryable`1[System.Int32]\' 这个错误。
正确写法:
var compiledProductReports = EF.CompileQuery( (DataDBContext ctx, decimal total) => ctx.OrderItems.AsNoTracking().IgnoreAutoIncludes() .GroupBy(a => a.ProductId).Select(a => new { ProductId = a.Key, Quantity = a.Sum(b => b.Quantity), Price = a.Sum(b => b.Price), }).Where(a => a.Price > total).Select(a => a.ProductId)); var productIds = compiledProductReports(_dataDBContext, 100000).ToList();
Any
Count和Any
当有个需求判断满足条件的数据是否存在通常会有如下写法
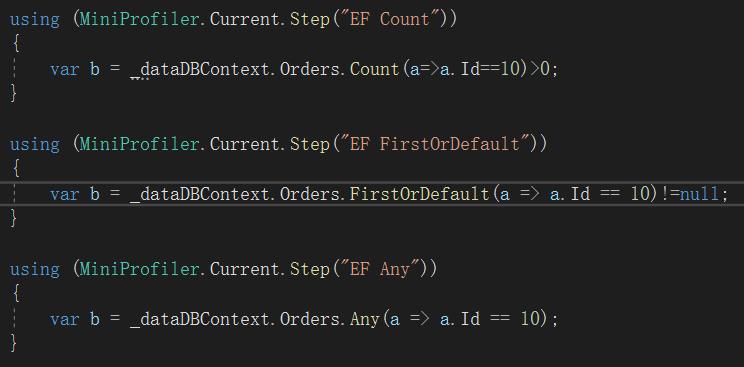
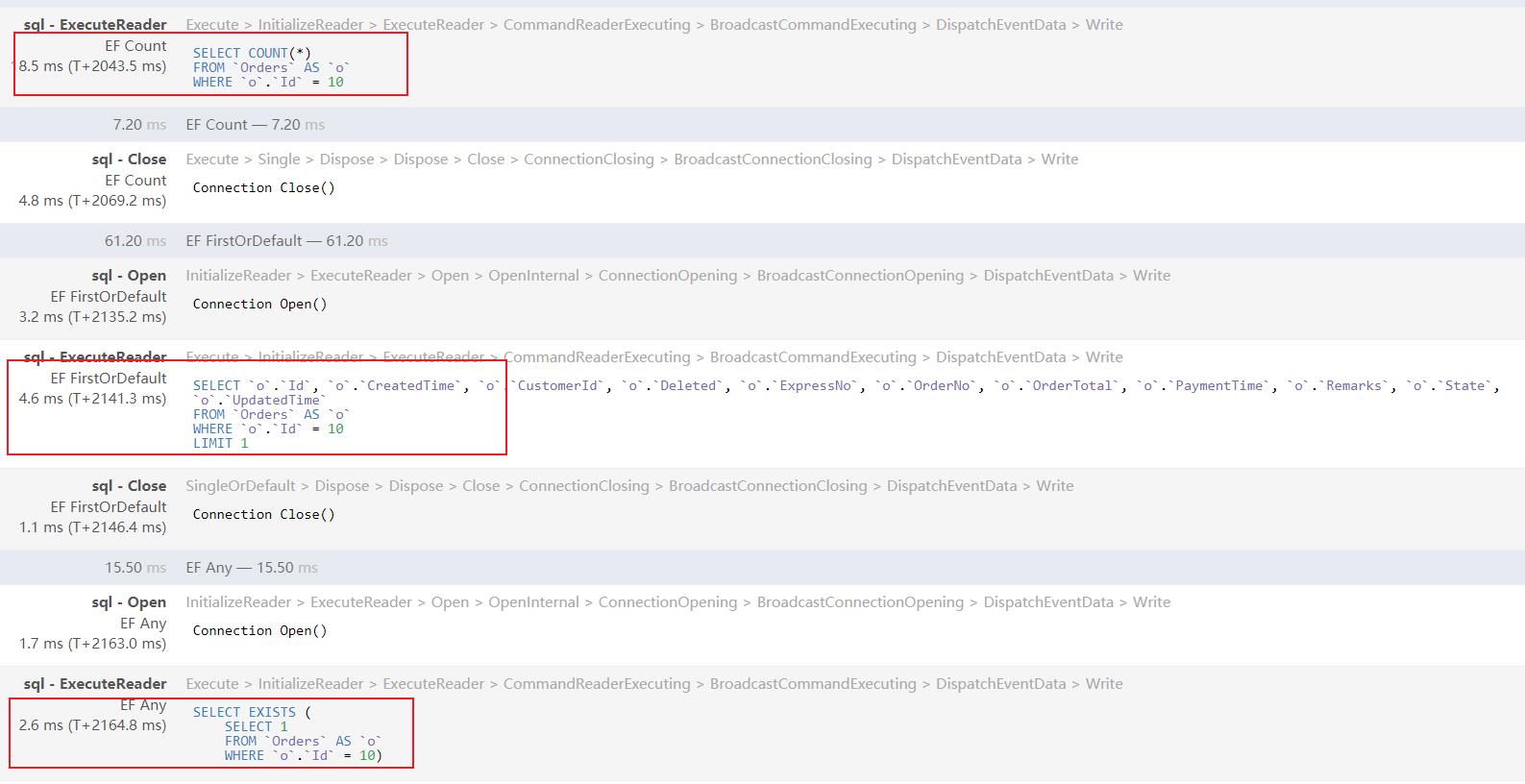
查看三种方式生成的SQL和执行耗时,Any是效率最高的一种。
补充
提升EF的性能还有很多办法,分为三大类:数据库性能(纯数据库优化)、网路传输(减少数据传输和连接次数)和EF运行时开销(跟踪和生成SQL语句)。还有很多优化技巧没能提及到如AsEnumerable方法改为
流式处理处理每次只获取一条数据,但是会增加数据连接。想进一步提醒程序的性能最简单的办法就是在加入缓存机制(Redis缓存等),缓存模式介绍(https://mp.weixin.qq.com/s/iUDA8L30-z_36XvYP8Dq1w),EF的拦截器也为我们提供了更多的解决方案(https://docs.microsoft.com/zh-cn/ef/core/logging-events-diagnostics/interceptors#example-advanced-command-interception-for-caching)。
Github地址:https://github.com/MayueCif/EFCore
以上是关于.Net EF Core千万级数据实践的主要内容,如果未能解决你的问题,请参考以下文章