线性判别分析之python代码分析
Posted ZhiboZhao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线性判别分析之python代码分析相关的知识,希望对你有一定的参考价值。
前几天主要更新了一下机器学习的相关理论,主要介绍了感知机,SVM以及线性判别分析。现在用代码来实现一下其中的模型,一方面对存粹理论的理解,另一方面也提升一下代码的能力。本文就先从线性判别分析开始讲起,不熟悉的可以先移步至线性判别分析(Linear Discriminant Analysis, LDA) - ZhiboZhao - 博客园 (cnblogs.com)对基础知识做一个大概的了解。在代码分析过程中,本文重点从应用入手,只讲API中最常用的参数,能够完成任务即可。
本文代码参考链接:https://github.com/han1057578619/MachineLearning_Zhouzhihua_ProblemSets
一、数据准备
数据集部分我采用周志华《机器学习》书中的 watermelon数据集,数据集前5行如下:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.46 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 是 |
1.1 读取数据:
import pandas as pd
data_path = \'./watermelon3_0_ch.csv\'
data = pd.read_csv(data_path).values # 读取数据并转为np.array类型
这里主要运用 pd.read_csv() 进行 .csv 文件的读取,该模块主要用到的参数如下:
pd.read_csv(file_path, sep, header)
其中:file_path 是目标文件的路径;sep 是目标文件中的分隔符,默认 .csv 文件以 ‘,’ 分隔;header 是整数类型的,它的数值决定了读取 .csv 文件时从第几行开始。举个例子:
# header = 0, 默认第0行为表头,从表头往下开始读取
head_0 = pd.read_csv(data_path, header = 0)
# header = 1, 默认第1行为表头,从表头往下开始读取
head_0 = pd.read_csv(data_path, header = 1)
header_0的结果为:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.46 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
header_1的结果为:
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.46 | 是 |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
1.2 对数据进行 "one-hot" 编码
我们以二维线性判别分析为例,只根据 "密度" 和 "含糖量" 来确定是否是好瓜
X = data[:, 7:9].astype(float) # 提取密度和含糖量的数据作为输入特征
y = data[:, 9] # 提取最后一列作为判别类型
y[y == \'是\'] = 1 # 需要进行one-hot编码,将瓜分类
y[y == \'否\'] = 0
y = y.astype(int)
\'\'\'
以好瓜/坏瓜 来对样本进行分类
\'\'\'
pos = y == 1, neg = y == 0 # 分别找到正负样本的位置
X0 = X[neg], X1 = X[pos] # 以提取正负样本的输入特征
二、线性判别分析
2.1 根据对应模型进行求解
从上一讲中我们得到,线性分类判别模型的最优解为:
其中,
这里面注意一点,为了更符合人的理解习惯,我们在公式 (3) 中,定义的 \\(S_w\\) 是单个向量相乘之后求和;但是矩阵形式则更方便被计算机描述,设 $ X_{0} = {x_{1},x_{2},...,x_{m} }^{T}, X_{1} = {x_{1},x_{2},...,x_{n} }^{T}$,由于 \\(x_{i} \\in R^{p \\times 1}\\),因此\\(X_{0}, X_{1} \\in R^{m \\times p}\\),改写成矩阵形式:
于是,对应代码为:
u0 = X0.mean(0, keepdims=True) # (1, p)
u1 = X1.mean(0, keepdims=True)
sw = np.dot((X0 - u0).T, X0 - u0) + np.dot((X1 - u1).T, X1 - u1)
w = np.dot(np.linalg.inv(sw), (u0 - u1).T).reshape(1, -1) # (1, p)
说明:
mean() 函数在指定维度上求均值,由于 \\(X_{0} \\in R^{m \\times p}\\),所有指定维度为0之后相当于对所有 \\(m\\) 个样本进行求平均,得到 \\(u_{0} \\in R^{1\\times p}\\)
2.2 模型可视化
这一部分代码主要是绘图的一些格式,本文就不多做解释了。
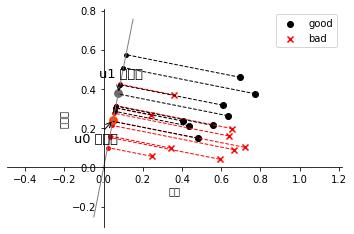
fig, ax = plt.subplots()
ax.spines[\'right\'].set_color(\'none\')
ax.spines[\'top\'].set_color(\'none\')
ax.spines[\'left\'].set_position((\'data\', 0))
ax.spines[\'bottom\'].set_position((\'data\', 0))
plt.scatter(X1[:, 0], X1[:, 1], c=\'k\', marker=\'o\', label=\'good\')
plt.scatter(X0[:, 0], X0[:, 1], c=\'r\', marker=\'x\', label=\'bad\')
plt.xlabel(\'密度\', labelpad=1)
plt.ylabel(\'含糖量\')
plt.legend(loc=\'upper right\')
x_tmp = np.linspace(-0.05, 0.15)
y_tmp = x_tmp * w[0, 1] / w[0, 0]
plt.plot(x_tmp, y_tmp, \'#808080\', linewidth=1)
wu = w / np.linalg.norm(w)
# 正负样板店
X0_project = np.dot(X0, np.dot(wu.T, wu))
plt.scatter(X0_project[:, 0], X0_project[:, 1], c=\'r\', s=15)
for i in range(X0.shape[0]):
plt.plot([X0[i, 0], X0_project[i, 0]], [X0[i, 1], X0_project[i, 1]], \'--r\', linewidth=1)
X1_project = np.dot(X1, np.dot(wu.T, wu))
plt.scatter(X1_project[:, 0], X1_project[:, 1], c=\'k\', s=15)
for i in range(X1.shape[0]):
plt.plot([X1[i, 0], X1_project[i, 0]], [X1[i, 1], X1_project[i, 1]], \'--k\', linewidth=1)
# 中心点的投影
u0_project = np.dot(u0, np.dot(wu.T, wu))
plt.scatter(u0_project[:, 0], u0_project[:, 1], c=\'#FF4500\', s=60)
u1_project = np.dot(u1, np.dot(wu.T, wu))
plt.scatter(u1_project[:, 0], u1_project[:, 1], c=\'#696969\', s=60)
ax.annotate(r\'u0 投影点\',
xy=(u0_project[:, 0], u0_project[:, 1]),
xytext=(u0_project[:, 0] - 0.2, u0_project[:, 1] - 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
ax.annotate(r\'u1 投影点\',
xy=(u1_project[:, 0], u1_project[:, 1]),
xytext=(u1_project[:, 0] - 0.1, u1_project[:, 1] + 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
plt.axis("equal") # 两坐标轴的单位刻度长度保存一致
plt.show()
self.w = w
self.u0 = u0
self.u1 = u1
return self
最终得到的分类结果图如下:
以上是关于线性判别分析之python代码分析的主要内容,如果未能解决你的问题,请参考以下文章