mysql存储过程与事务
Posted 一乐乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql存储过程与事务相关的知识,希望对你有一定的参考价值。
mysql存储过程与事务
一、存储过程
1, 存储过程 -----类似函数---面向过程
2, 存储过程的定义,调用,定义变量、赋值变量,判断条件,通过使用游标、设置continue句柄,更改循环结构为repeat结构
☆分有参无参,其中有参(in 标志输入变量,out 标记输出变量,inout 标志既能做输入也能做输出变量)
2-1,定义存储过程procedure
(1)存储关键字:procedure,创建、删除跟表跟视图差不多
(2)创建前需要先定义存储过程结束的符号,关键字 delimiter(修改结束符,避免与默认的;矛盾)
(3)create procedure 的标志是以begin 要存储的过程(查询的过程吧) end 结束符号
(4)修改结束符号为原来的;(复原结束符)
2-2,调用存储--使用关键字call 存储过程()
▪无参:call 存储过程();
▪有参:call存储过程(@参数1,@参数2…);
select @参数1,@参数2…;
2-3,存储过程定义变量,以及赋值变量
☆也就是参数变量,局部变量那么回事,记住个关键字declare、set标志一下就行啦
其实也没啥,就是定义变量,赋值变量时,多了个标志的关键字declare、set而已。
declare 变量 变量类型;
set 变量=值;
2-4,存储过程使用判断条件
if…then 如果怎么怎么,则怎么怎么
elseif … then 否则如果怎么怎么,则怎么怎么
else … 否则怎么怎么
end if;
还有结构:case when…then …end case 都一样。
2-5,游标:游标游标,就是循环遍历时使用啦!一般应用于存储过程内部时,查询可能返回多条记录,如果数据量大,则需要使用光标来逐条读取查询结果集的记录,跟java的结果集resultSet,通过next() 操作差不多。
(1)数据量小的情况下,游标的使用情况,直接使用在while结构


(2)数据量大时需要改写循环结构:改成repeat 结构 until 结束条件 end repeat;
过程中通过定义continue句柄 for not found set 结束条件。
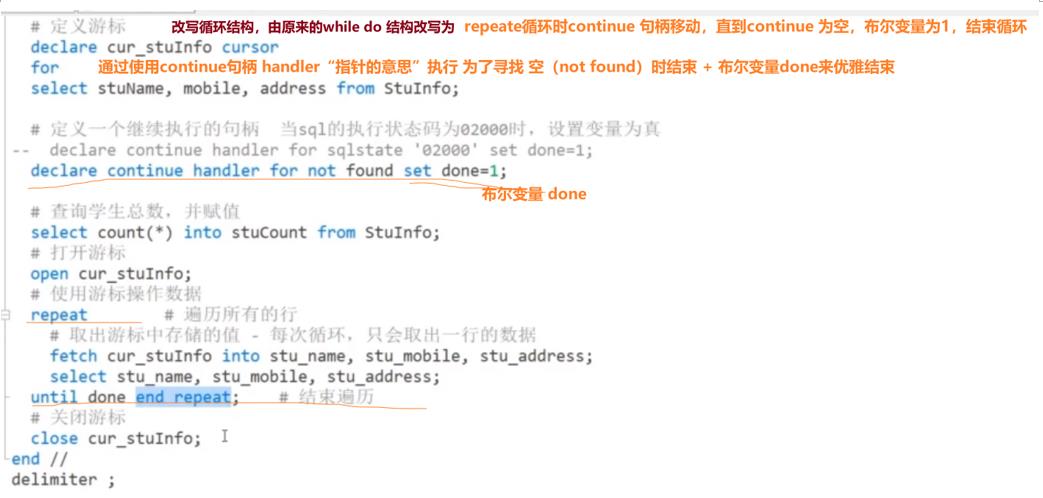
✿注意:游标是只读的!且只能往前滚动---下一行下一行,所以性能不高,而且使用游标容易造成死锁,造成内存开发比较大,所以游标一般使用在存储过程,函数,触发器中。
例如复制,进行数据库的维护,例如主从分离,进行数据库的优化。。。遍历取出每一行。。。
3, 存储过程的优缺点:
☼ 优点:
①预编译,执行速度快,具有更好的性能。存储过程经过编译之后会比单独一条一条执行要快。但这个效率真是没太大影响。如果是要做大数据量的导入、同步,我们可以用其它手段。
②创建一次可以重复使用,减少开发员的工作量
③减少网络传输,尤其是在高并发情况下,减低网络的负载。存储过程主要是在服务器上运行,减少对客户机的压力。所有的数据访问都在服务器内部进行,不需要传输数据到其它终端。但我们的用户服务器通常与数据库是在同一内网,大数据的访问的瓶颈会是硬盘的速度,而不是网速(可使用Redis缓存解决)。
④安全性:安全性高,存储过程可以屏蔽对底层数据库对象的直接访问,使用EXECUTE权限调用存储过程,无需拥有访问底层数据库对象的显式权限。(合理使用)
☼缺点:
① 不可移植性,由于存储过程将应用程序绑定到 SQL Server,因此使用存储过程封装业务逻辑将限制应用程序的可移植性。
② 架构不清晰,不够面向对象,不是OO的,本质上还是过程化的,面对复杂的业务逻辑,过程化的处理会很吃力。存储过程不太适合面向对象的设计,无法采用面向对象的方式将业务逻辑进行封装,业务逻辑在存储层实现,增加了业务和存储的耦合,代码的可读性也会降低。
③ 不便于调试。基本上没有较好的调试器,很多时候是用print来调试,但用这种方法调试长达数百行的存储过程简直是噩梦。好吧,这一点不算啥,C#/java一样能写出噩梦般的代码。
④ 没办法应用缓存。虽然有全局临时表之类的方法可以做缓存,但同样加重了数据库的负担。如果缓存并发严重,经常要加锁,那效率实在堪忧。
⑤ 无法适应数据库的切割(水平或垂直切割)。数据库切割之后,存储过程并不清楚数据存储在哪个数据库中。
4,❀使用建议:普通的项目开发中,不建议大量使用存储过程,对比SQL语句,存储过程适用于业务逻辑复杂,比较耗时,同时请求量较少的操作,例如后台大批量查询、定期更新等。
(1)当一个事务涉及到多个SQL语句时或者涉及到对多个表的操作时可以考虑应用存储过程
(2)在一个事务的完成需要很复杂的商业逻辑时可以考虑应用存储过程
(3)比较复杂的统计和汇总可以考虑应用后台存储过程
二、事务
▷所谓事务:不过是把多条语句一起,通过transaction 结构…一起commit 过去。
▪ 实际应用场景:是把事务放到存储过程中的。
1,事务是多个操作作为一个整体,要么都执行,要么都不执行。
(默认情况下,每条sql语句视为独立的一个事务)
而我们为了发挥事务的作用:需要实现多条操作共同执行,共同不执行的结果(设置多条语句为一个事务)
-----自动提交关键字: autocommit
▪ 设置事务不再自动提交 set autocommit=0
▪ 事务执行完毕后再设置回事务自动提交 set autocommit=1;
2,❀事务的提出主要是为了解决并发情况下保持数据一致性的问题(类似于多线程)。事务(Transaction)是并发控制的基本单位!

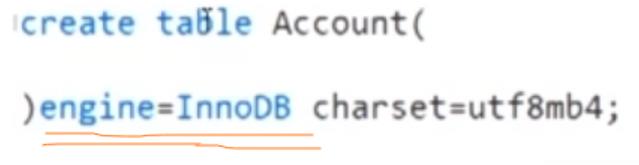
3,✿事务使用注意小细节:如果是表要使用到事务,表的搜索引擎需要设置为InnoDB
4,☼事务:
▷开始事务:start transaction
▷结束事务方式:提交或回滚(根据条件回滚)
•提交事务:commit
•回滚/撤销事务:rollback
5,事务关闭方式之根据条件回滚:条件有业务逻辑条件,也有sql语法或逻辑错误异常【sql异常】
6,事务特(属)性(ACID)
▪ 原子性:整体的操作里,各部分操作不可分割,要么都执行,要么都不执行。操作成功应用到数据库,失败---回滚
▪ 一致性:操作执行前后保持状态一致,例如银行转账问题:总余额保持不变。
▪ 隔离性:多个用户并发访问数据库时,多个并发事务之间要相互隔离开。例如不同用户同时向商家支付,用户之间的各自操作要隔离开来,不受其他用户操作的影响。
▪ 持久性:成功操作后,就提交到数据库啦(数据库的改变是永久的)
以上是关于mysql存储过程与事务的主要内容,如果未能解决你的问题,请参考以下文章