GPT and BERT
Posted 馒头and花卷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPT and BERT相关的知识,希望对你有一定的参考价值。
概
两个经典的NLP的预训练模型.
主要内容
GPT
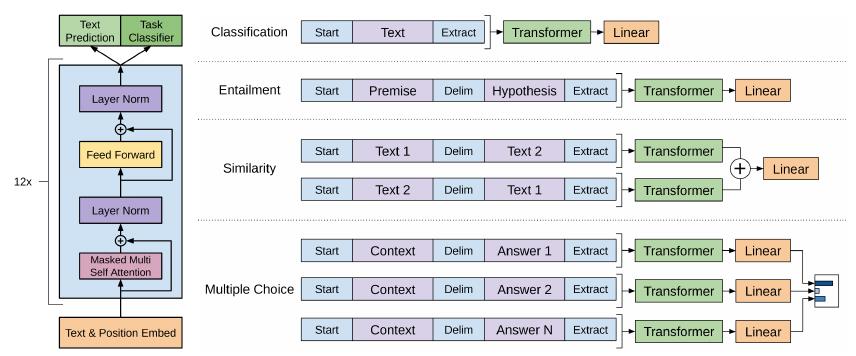
就是普通的transformer, 注意的是tokens之间的联系方式是auto-regressive的:
\\[P(x_i|x_{i-k}, \\cdots, x_{i-1} ;\\theta).
\\]
即每个token仅与之前的tokens有关.
BERT
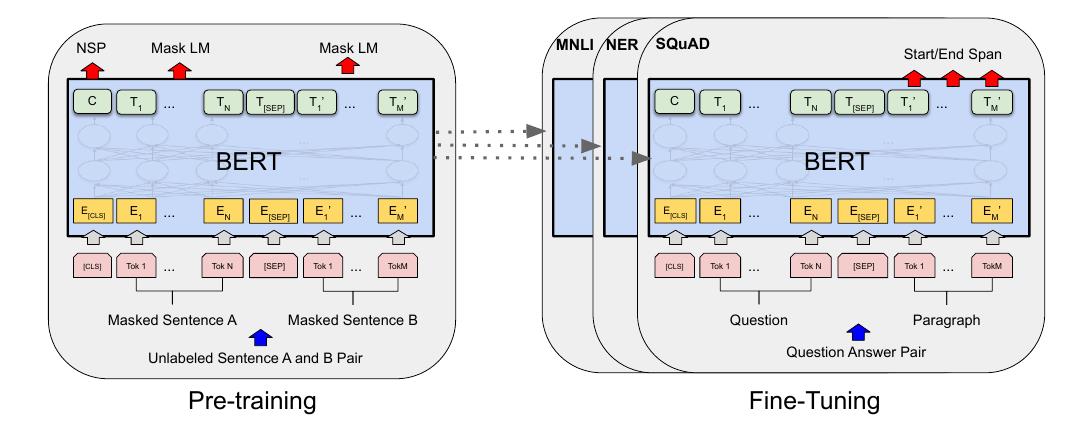
与GPT最为不同的是, BERT并非是auto-regressive的, 即其认为一个词可以通过上下文关联起来:
\\[P(x_i|X),
\\]
在实际中, BERT对部分的词mask掉, 相当于用别的词来推断:
\\[P(x_i|x_j, \\not \\in M).
\\]
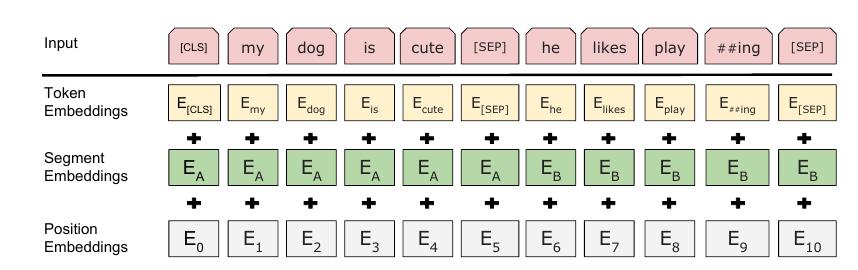
切除了普通的positional embeddings, 额外增加了segment embeddings, 用来标记不同的句子. 这么设计是认为很多下游任务都能通过两个部分的结构来表示.
以上是关于GPT and BERT的主要内容,如果未能解决你的问题,请参考以下文章
自然语言处理NLP之BERTBERT是什么智能问答阅读理解分词词性标注数据增强文本分类BERT的知识表示本质