详细讲解word embedding
Posted 常给自己加个油
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详细讲解word embedding相关的知识,希望对你有一定的参考价值。
机器经过阅读大量的words,将每个单词用vector表示,vector的dimension表达着这个单词的属性,意思相近单词,dimension就会呈现出来。vector就是word embedding。
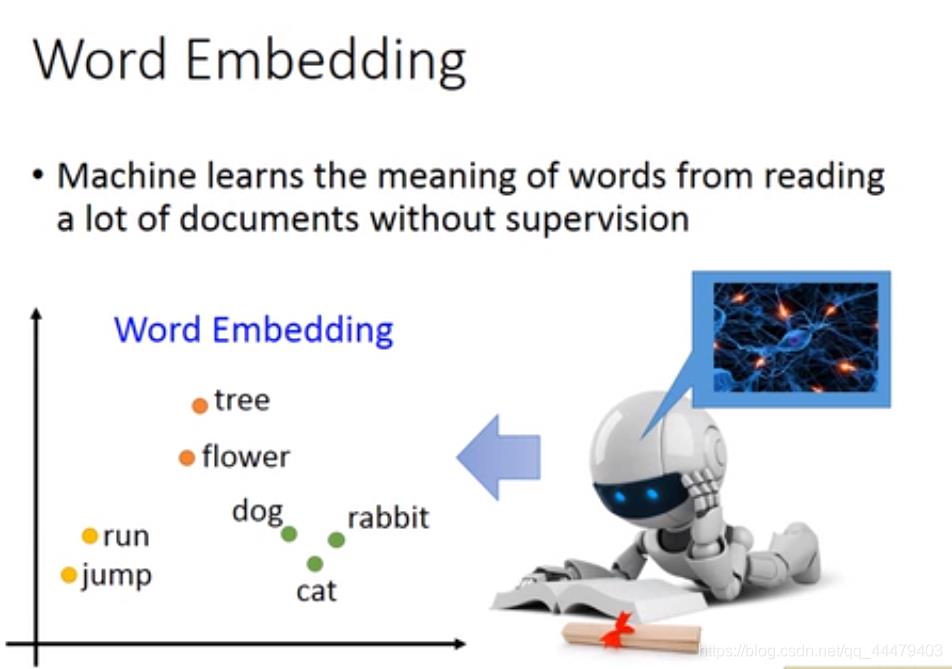
为了表示每个单词之间有联系,用二维vector来表示单词。可以更直观的看出每个单词的所属的类或者具有某种共同点。
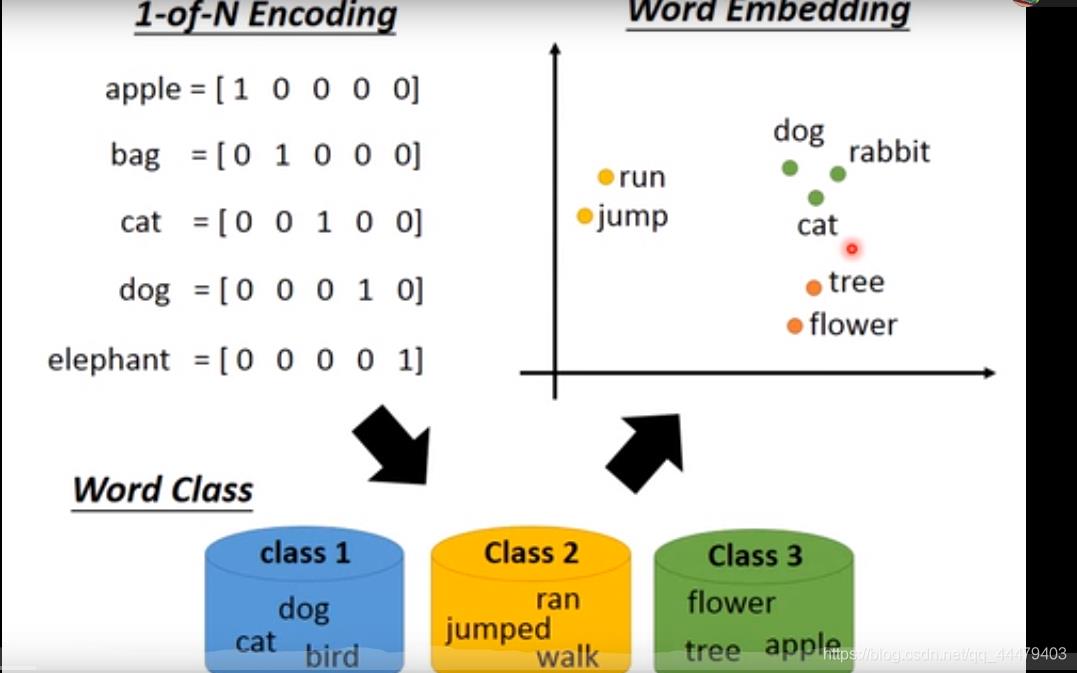
machine 在学习这俩个词语的时候,了解到都有520宣誓的字样,所以他认为他俩的vector应该相似。

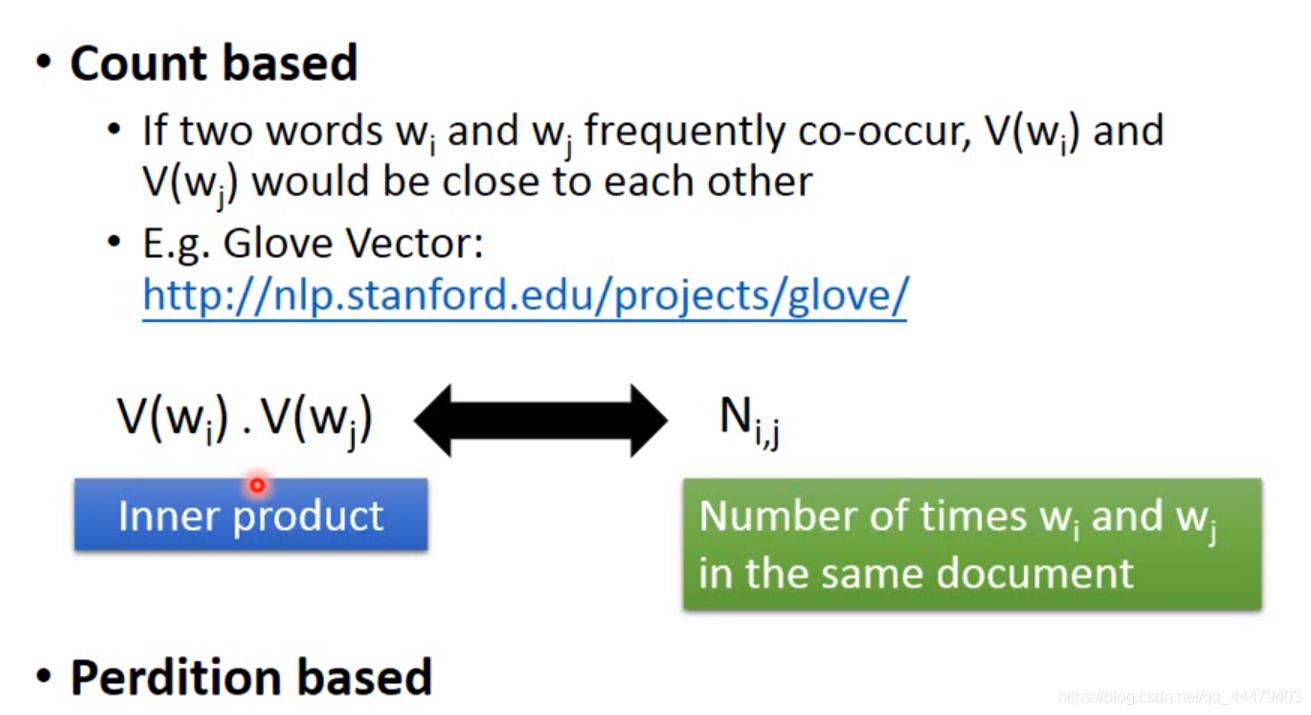
根据上下文来找到vector,有以下俩种方法。
Count 找到一组V(wi)V(wj)进行内积计算之后与他俩在文章里出现的次数Nij作比较最相近的。
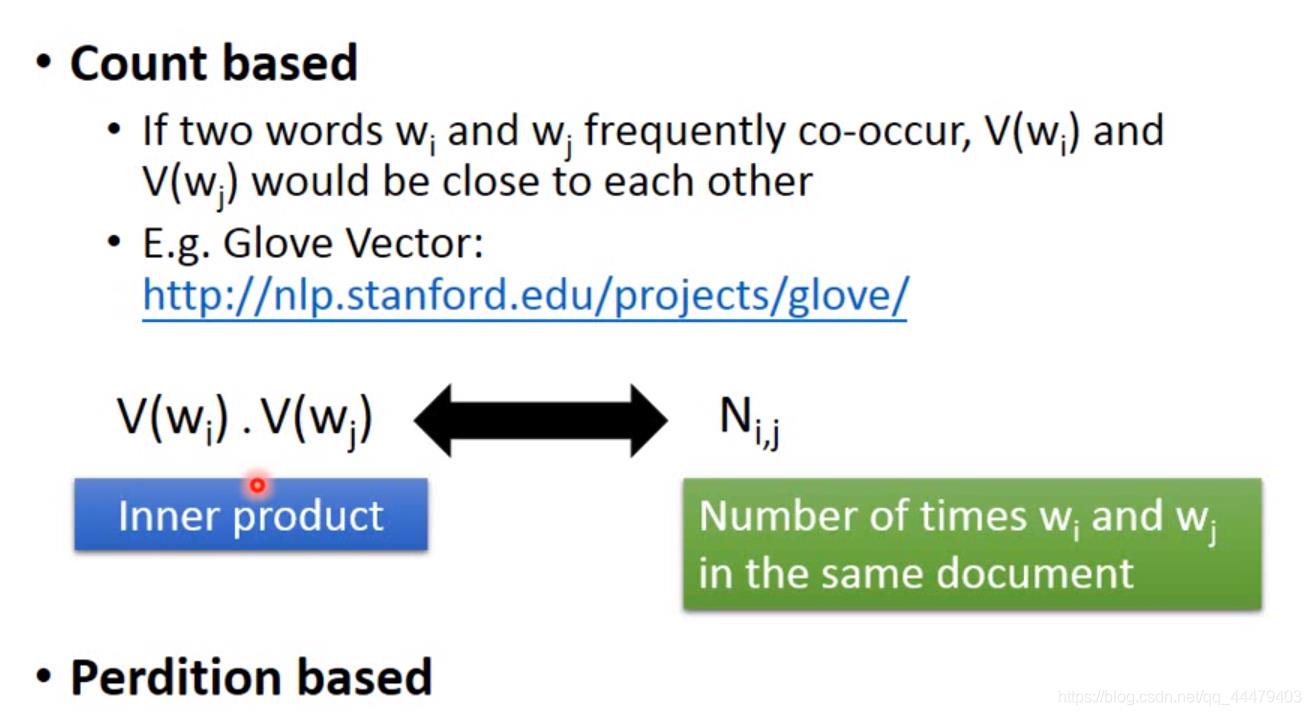
Prediction based 给机器input词汇,让机器训练一个网络能够输出下一个,output vector dimension由世界上可以出现的词汇数目决定。用Minmizing cross entropy 让output与target(指的就)接近,进行调参,找到最适合的neural network。
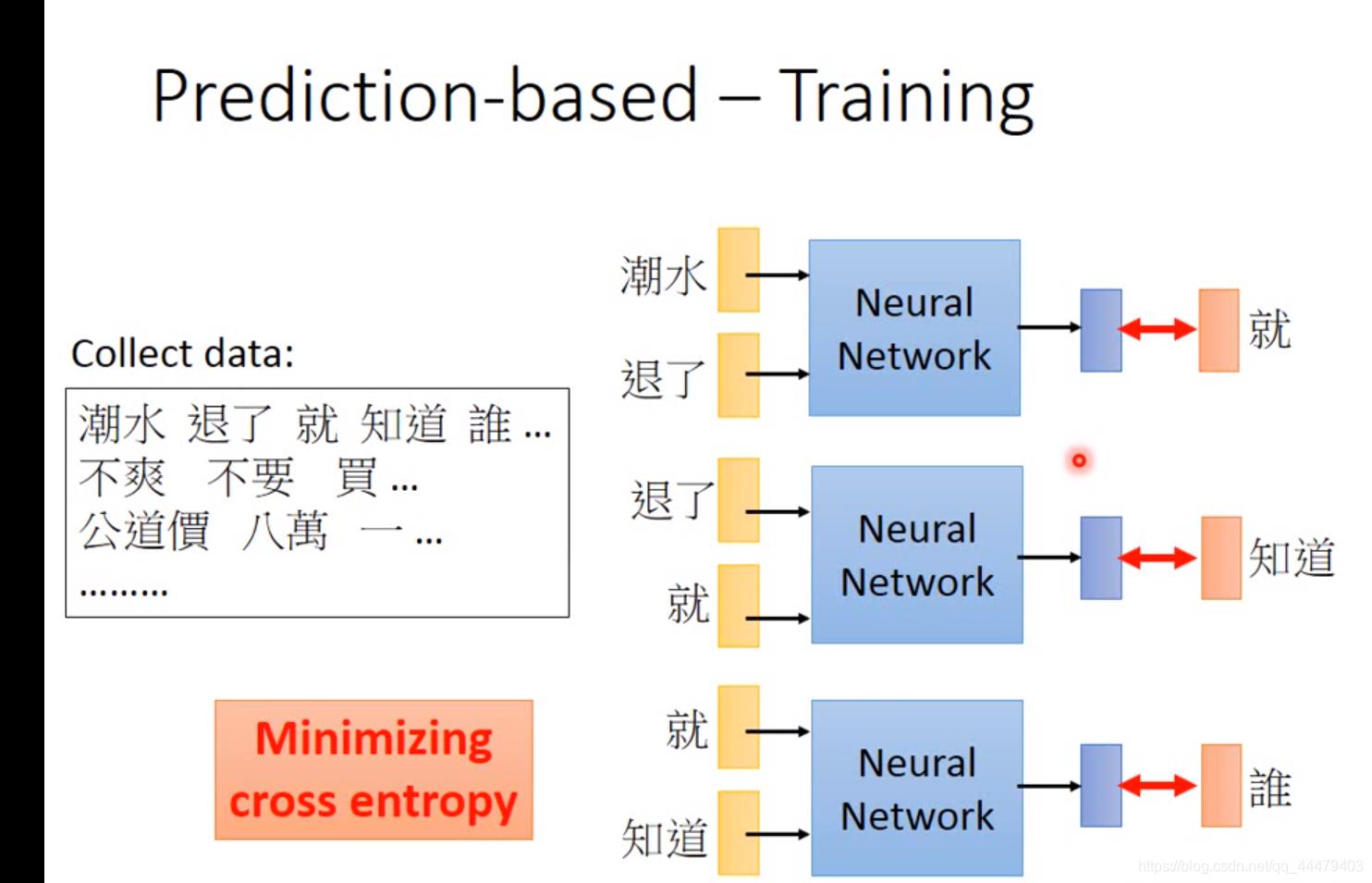
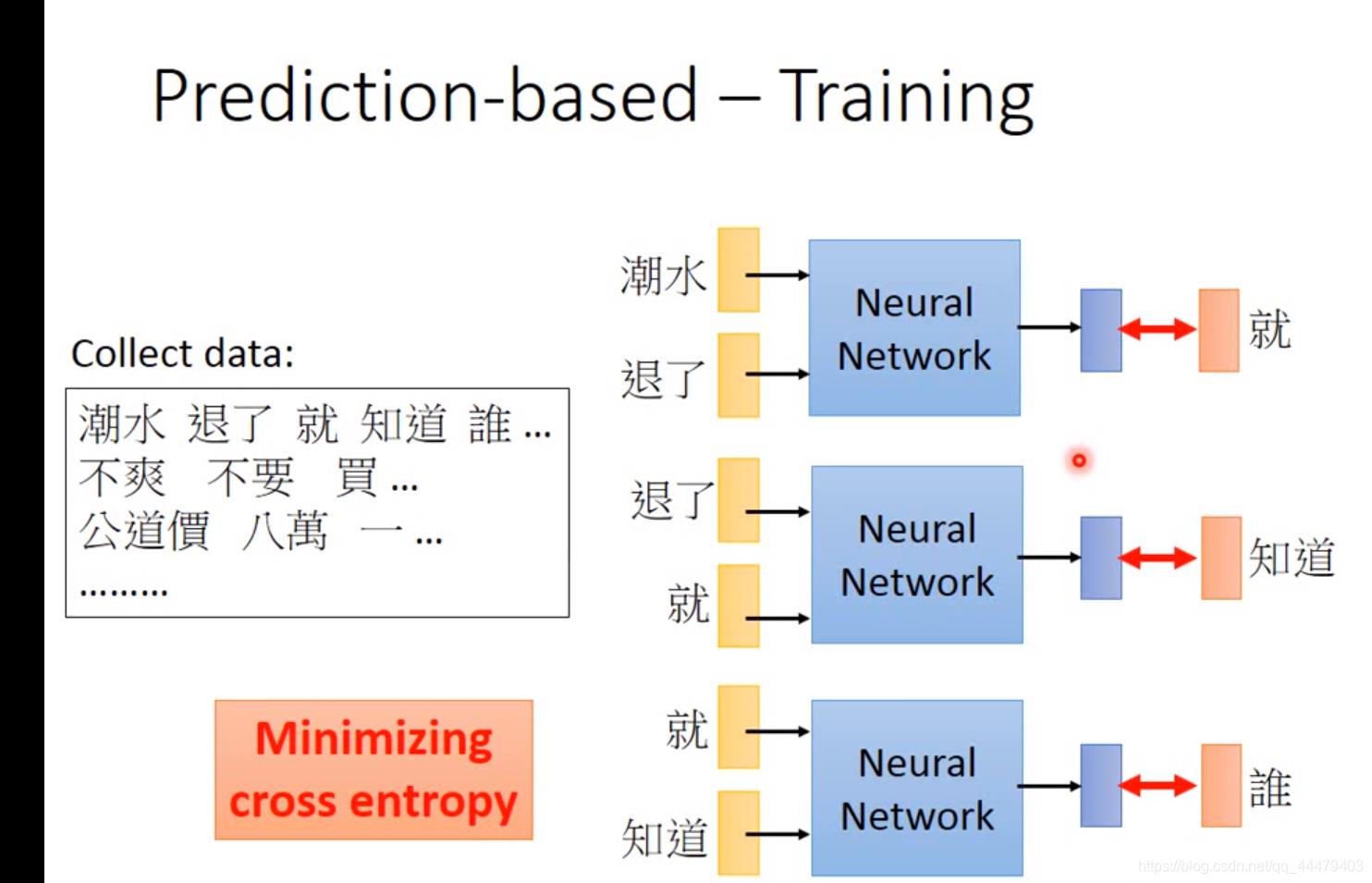
推文接话就是用的prediction方法。


prediction 句子出现的概率,Neural network是推文接龙网络,直接拿来进行预测。output 出现下一个target单词的概率,之后一起进行相乘。(这种技术用于speech recognition和机器翻译)。

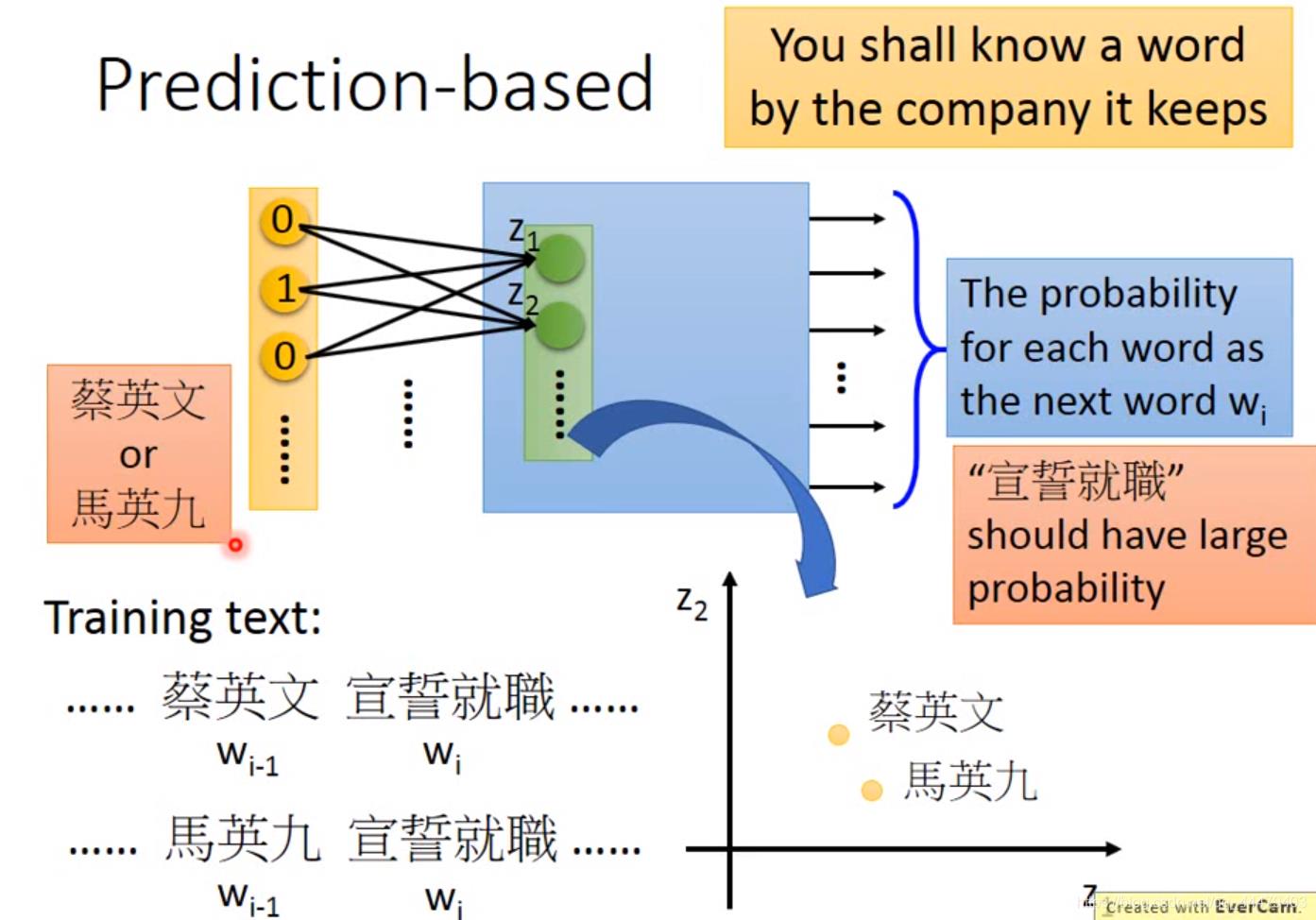
每一个word vector 乘以 matrix(相当于进行降维或者linear transformation
操作)得到由z1,z2等等组成的vector输入神经网络hidden layer中,几个隐藏层不等,最后输出下一个word的概率也是vector。 下边坐标图将每一个word vector的z1,z2…提取到坐标中,然后就可以看出同样的word有相近的特性。 这已经是learning好的network。

下边解释为什么learning好的network输出vector。只有一个hidden layer的,并且是linear activate fuction。
为什么用shall netwrok呢?
第一:因为有大量word vector的时候shall network train的快,并且效果和DNN是一样的。
第二:提取的线性变换之后的word vector(就是坐标轴中的vector)来当做NLP(自然语言处理)的input。
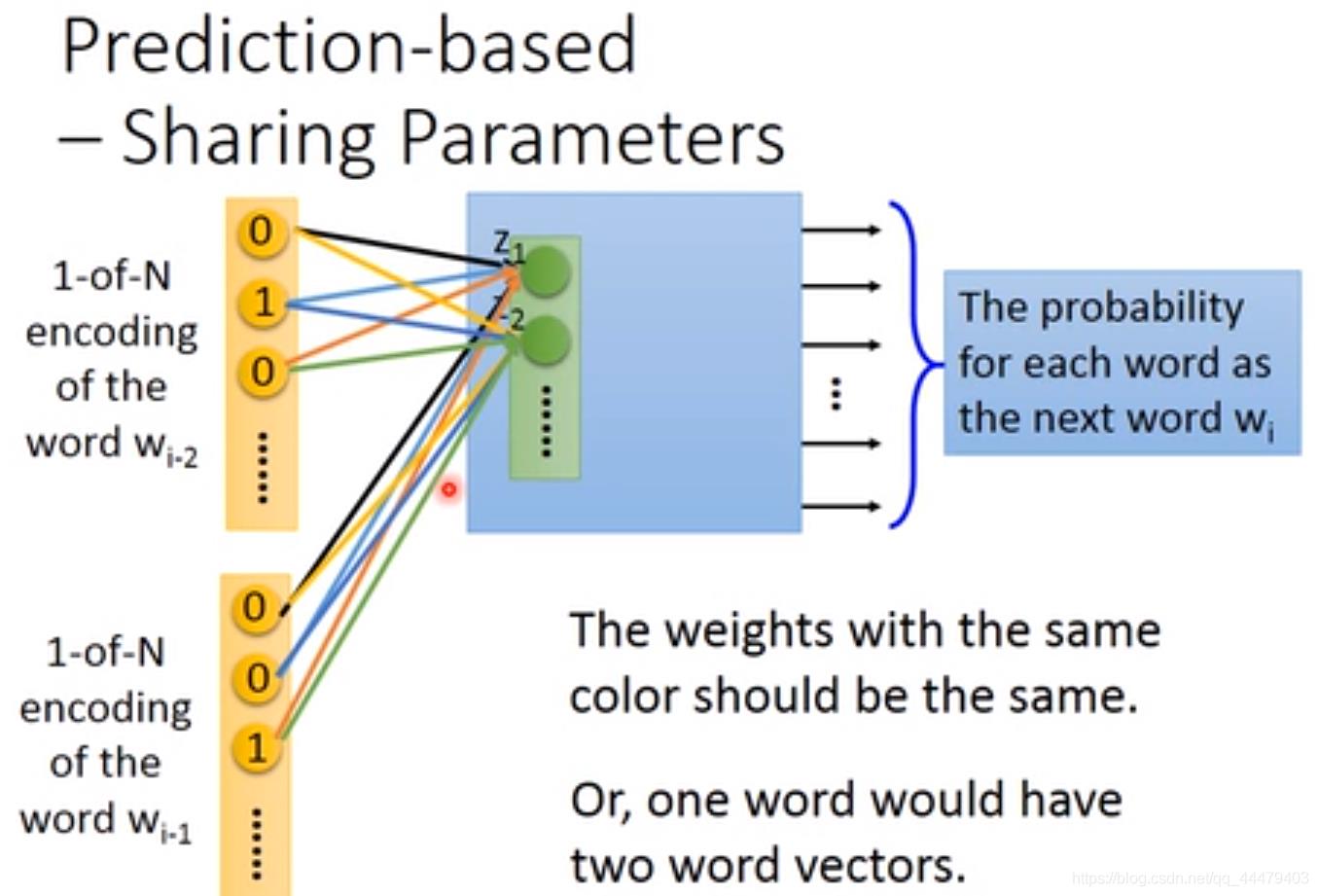
tie一起就是权值共享,不管你输入的word vector多长,w都不变的,参数不增加,可以一次输入十个或者二十个vector,计算z公式如下,之后再让之后的layer来寻找下一个预测的wi。

相同颜色的共用一个weight,减少了参数,并且不同位置的相同的word vector经过线性变换能够得到相同的word embedding。每一组词汇有固定的word embedding。
各种各样的prediction如下:
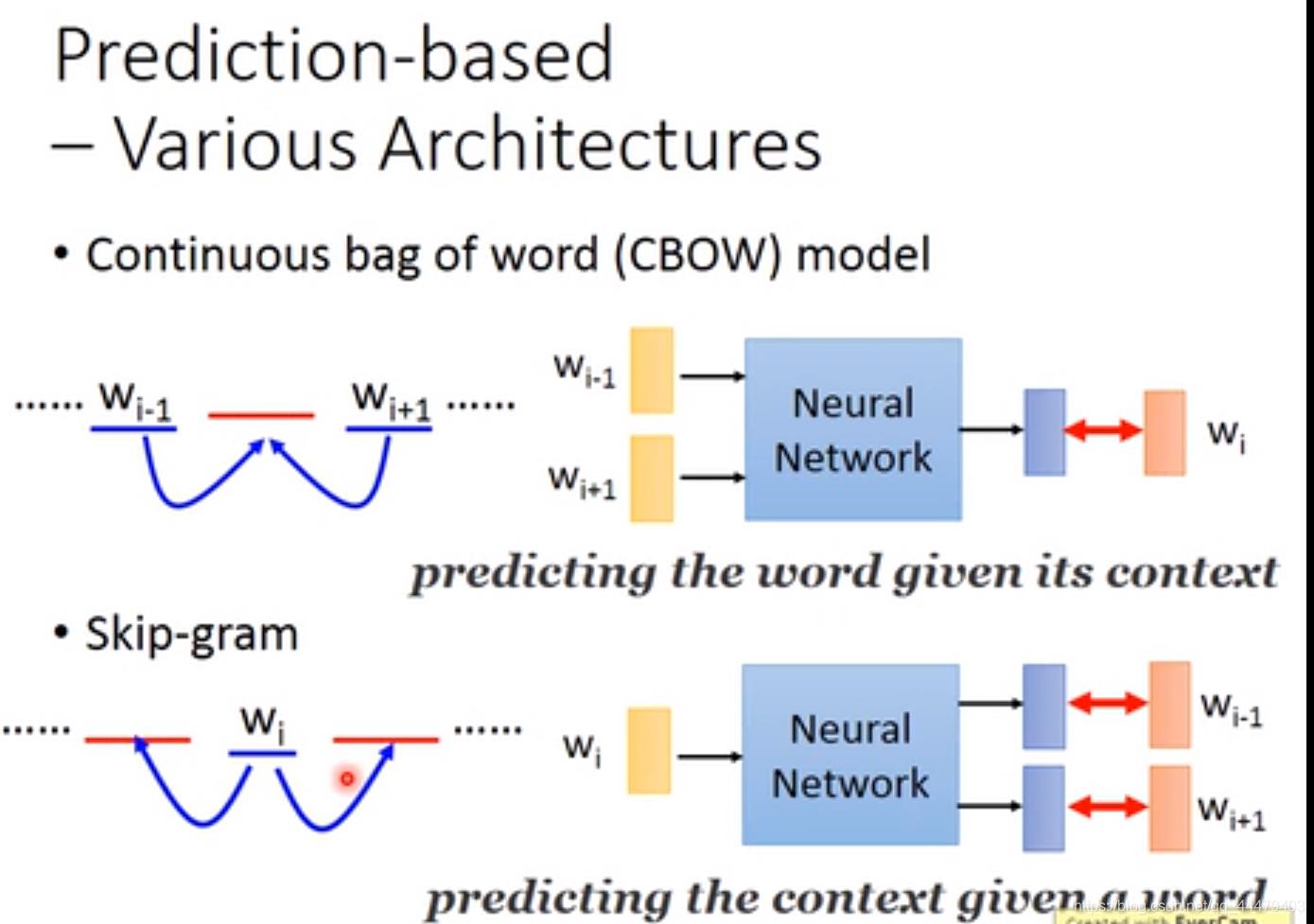
其他的例子关系
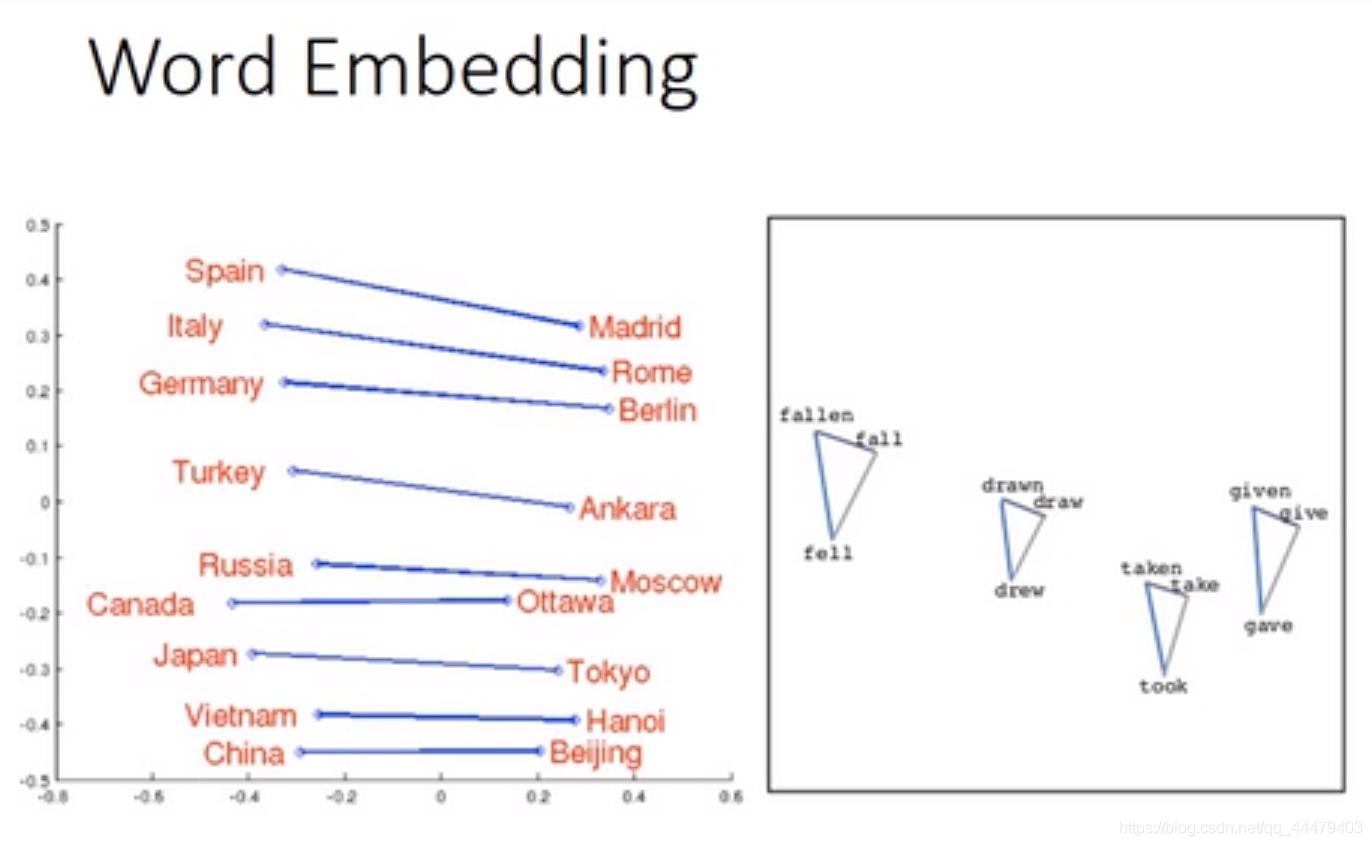
推论问题的例子:
机器进行如下计算并且推论出word w。

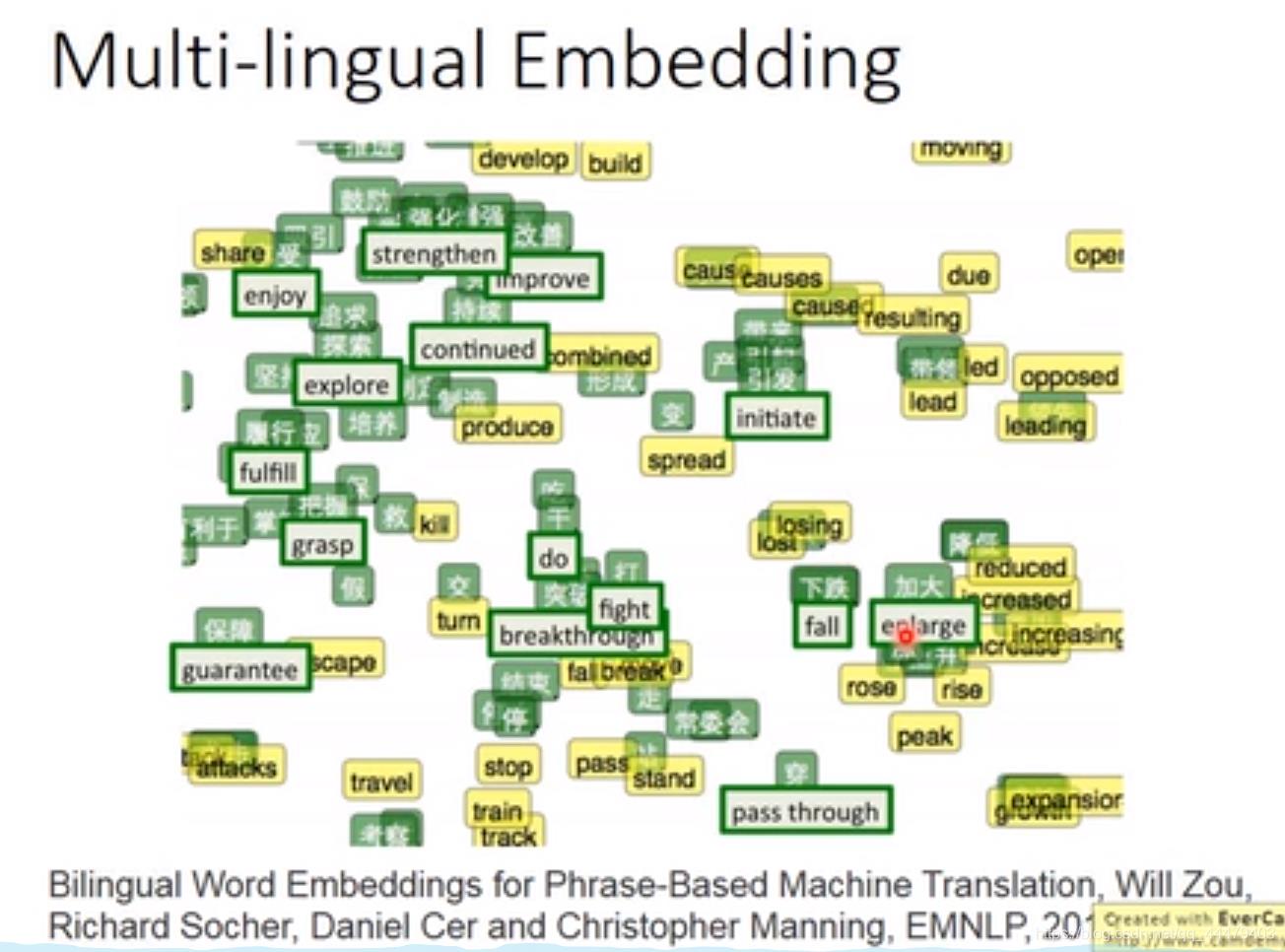
用绿色的英文与中文learning transform,之后将黄色的英文丢到learning好的transform中。就会在相应的最接近的中文旁边。

用Bag-word描绘那篇文,每一dimension代表某词汇出现的次数。丢到network中输出word embedding。
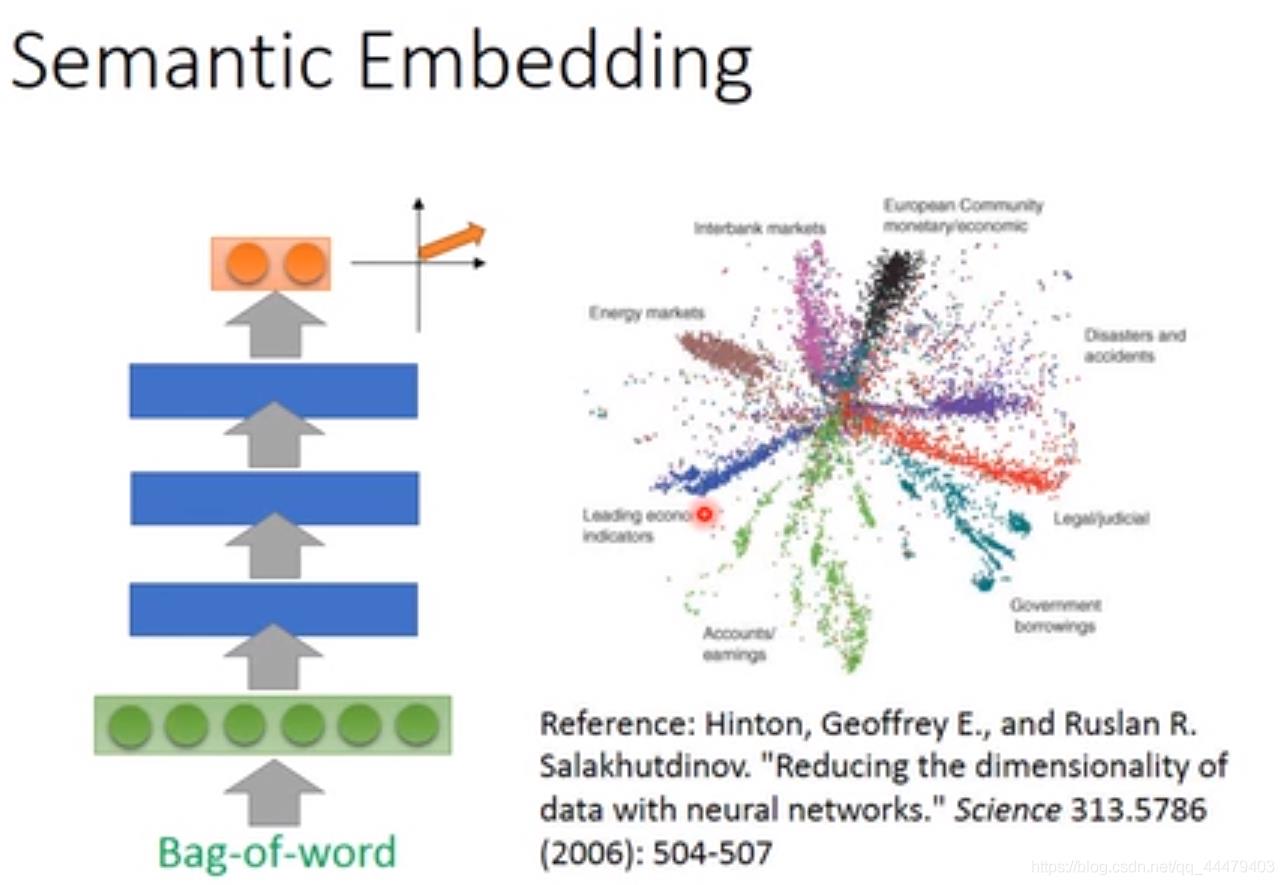
词的数目bag-word一样但是顺序不一样,表达的语义不一样。

获取以上文本PPT请点击这里
————————————————
版权声明:本文为CSDN博主「一双单眼皮」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_44479403/article/details/103466928
以上是关于详细讲解word embedding的主要内容,如果未能解决你的问题,请参考以下文章