Redis最佳实践
Posted 云最佳实践
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis最佳实践相关的知识,希望对你有一定的参考价值。
缓存数据库在现代系统架构中越来越成为标准配置之一,特别是随着微服务架构的流行,微服务无状态改造要求状态外置,外置的状态就需要存储到外部缓存服务中。Redis是当前主流的缓存数据库实现,本文介绍Redis基本概念与最佳实践。
架构与概念
Redis是一个使用ANSI C编写的开源、支持网络、基于内存、可选持久性的键值对存储数据库。从2015年6月开始,Redis的开发由Redis Labs赞助,而2013年5月至2015年6月期间,其开发由Pivotal赞助。在2013年5月之前,其开发由VMware赞助。根据月度排行网站DB-Engines.com的数据,Redis是最流行的键值对存储数据库。
单机/主备/集群模式
Redis是单线程模式,因为Redis设计理念是不消耗CPU,且单线程的结合异步IO处理效率也很高,当前Redis单实例可以达到10万QPS。一般的应用场景,使用单机或主备(高可用)即可满足要求。
但是如今应用程序越来越依赖Redis,对Redis的要求越来越高:访问低时延(<5ms)、高QPS(百万QPS)、高吞吐量(百MB/s),从而导致很多场景下,单CPU无法满足需求。因此多Redis进程组成的Redis集群是高性能缓存服务的一种解决方法。
在集群模式之下,由于应用程序特征,存在“热Key”现象,热Key会导致集群下面的Redis使用不均衡,热Key命中的实例很繁忙,其他实例空闲。解决热Key的通常做法有两个:一个是在Redis集群角度,提供读写分离特性,通过多个Redis实例分担负载,当然读写分离本身是一个复制集群,如何减少实例间数据复制时延以及复制时对主实例的消耗是读写分离模式设计的关键;另一个方法是在应用程序内部使用内存做一级缓存,使用Redis做二级缓存。
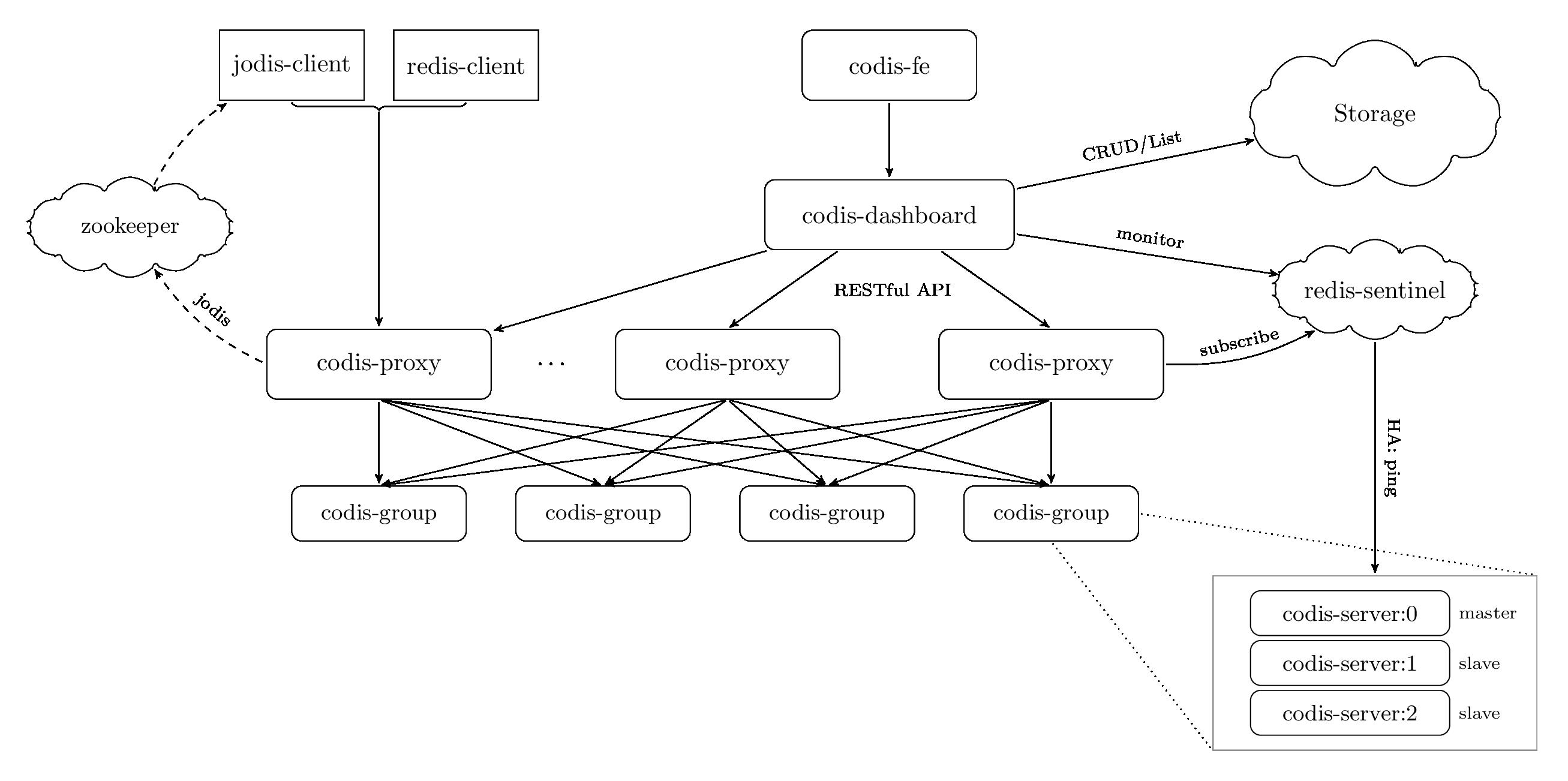
Codis集群
Redis官方版本3.0才支持集群模式,在此之前,有不少Redis集群方案,主要实现思路都是在Redis实例之上增加一个Proxy,由Proxy负责分区转发,同时Redis实例的状态由哨兵监控,哨兵将状态写入到分布式配置中心(ZK/ETCD),Proxy通过配置中心刷新Redis实例路由信息。
在开源领域认可度较高的Proxy集群实现是Codis,下图是Codis的架构。
Redis原生集群
Redis3.0版本支持集群模式,与上面的带Proxy集群方式不一样,Redis官方提供的集群实现,在Server端是没有Proxy的,Proxy路由的功能,由客户端SDK来实现。为了与Proxy集群区分,Redis官方的集群称为原生集群。
Redis集群节点之间通信机制为 Redis Cluster Bus,基于Gossip协议实现。
Redis客户端通过CLUSTER相关命令获取集群配置信息,客户端与节点之间通过MOVED/ASK来协调Key所属的槽位变更。
原生集群与Proxy集群相比较,没有Proxy层之后,水平扩展能力更好,官方宣传支持1000节点。当然没有了Proxy层,流量、路由管控会更麻烦一些。
原生集群的槽位Slot空间总共为16383个,因此理论上集群节点数量是不能超过16383个。
Redis规格评估要素
选择Redis规格时候,需要评估业务模型,避免选择的规格与实际业务模型不匹配。
内存容量
根据Key写入数量/频度,TTL时常,是否显示删除判断容量增长情况,避免容量满。
当Redis内存容量满时,再次写入则会触发淘汰Key操作。同时由于内存满,可能导致系统资源不足,淘汰Key的操作会很耗时,从而导致写入超时。
是否落盘
数据需要落盘的话,需要确认 appendfsync=everysec 如果开启,底下磁盘是否是SSD;否则在高QPS写的场景,如果不是SSD盘,可能会导致应用访问Redis时延增加,极端情况会访问超时。
数据是否可重生成
如果数据可以重生成,则不需要迁移数据。
如果数据不能重生成,那么意味着需要迁移数据。当前并没有Redis在线迁移的工具或服务(DRS服务对Redis支持还不完善),因此需要业务代码配合完成迁移,根据业务情况讨论迁移方案。
典型的方法有:
- 业务代码双写
- 如果重复Key值可以覆盖,则可以写一个工具从源库读,写到目的库,然后在某个时间点,短暂停业务切换库
- 简单粗暴的是停业务迁移
QPS
QPS是选择Redis规格的主要依据之一,有的场景是数据量很小,QPS很高,由于主备版本的最大QPS有限,如果需要的QPS超过了主备版本的QPS最大值,那么也得上集群版本。
内存很小,QPS很高的场景,也是小规格集群的主要场景之一。
读写QPS占比
QPS指标需要区分读/写,写QPS很高的话要注意 AOF REWRITE,在执行 AOF REWRITE 时再写入的话,时延会变高,极端情况下会导致访问超时。
参考连接
并发连接数
根据要求的并发连接数选定对应的规格。如果是短链接方式访问,要特别注意。
是否cpu消耗类型
一些场景下如MSET、MGET等消耗CPU的命令较多,评估时候一定要考虑CPU算力是否足够,有时候内存足够了但是CPU不足,导致Redis CPU繁忙。这种情况是小内存规格集群的典型使用场景。
是否有TTL设置过长会导致内存满
可能有一些Key的TTL设置的很长(如一个月),且没有主动删除机制,那么就可能会导致内存满,从而触发Key淘汰策略,这时候再写入可能会超时。
是否使用Pipeline
在QPS很高的场景下,使用Pipeline相比较单个Key操作,效率和性能都有很大提升。但是需要限定Pipeline中的命令数量,当前Codis Proxy默认的 session_max_pipeline=10000 ,建议不要超过此值。
同时还需要评估一次Pipeline返回的数据量。
是否使用多DB
有一些云厂商(如阿里云)支持Redis集群有多DB特性,不同DB中的Key值可以相同。Codis集群、Redis原生集群是不支持多DB的。
长连接or短连接
短连接需要特别关注连接数这个指标。如果是短链接,需要关注内存参数本地端口、最大句柄数等值是否调优。
主流云厂家缓存服务对比
Redis作为主流缓存服务,各个云厂家都提供了托管式的Redis缓存服务,不过各个厂家实现上并不完全一致,在此列出各个厂家主要实现原理以供选型参考。
AWS
AWS提供Redis集群托管服务。用户指定flavor机器(计算、存储、网络),AWS帮助客户讲Redis集群部署到服务器上。
同时用户创建实例时候可以指定节点数量、副本数量、槽位与节点分配方式。
- 计算/存储/网络:可指定flavor。
- LB:不涉及。
- Proxy:不涉及。
- 多DB:不支持。
- 副本数:可指定副本数。
- 读写分离:不支持。
- 扩缩容:在线扩缩容。
- 跨集群复制:不支持。
- 性能规格:
- 使用限制:使用限制
- Redis版本兼容:可选择,范围:3.2.4, 3.2.6, 3.2.10, 4.0.10, 5.0.0, 5.0.3, 5.0.4
阿里云
阿里云提供Proxy模式的集群,Proxy自研。
- 计算/存储/网络:与Redis规格绑定,不可指定flavor。
- LB:使用SLB,QPS峰值为200万。
- Proxy:Proxy数量与集群规格有一定配比关系,可支持用户自定义Proxy数量,应对cpu消耗场景。
- 多DB:集群支持多DB。
- 副本数:单副本、双副本
- 读写分离:支持。slave同步数据存在一定延迟。
- 扩缩容:在线扩缩容。
- 跨集群复制:支持。提供全球多活特性。
- 性能规格:性能规格
- 使用限制:使用限制
- Redis版本兼容:2.8, 4.0
腾讯云
腾讯里云提供Proxy模式的集群,Proxy自研。同时腾讯云提供两种Redis引擎:开源Redis,自研CKV。
- 计算/存储/网络:与Redis规格绑定,不可指定flavor。
- LB:单节点10万QPS,QPS上限未知。
- Proxy:数量不可指定。
- 多DB:集群不支持多DB。
- 副本数:可选择:1,2,3,4,5
- 读写分离:不支持。
- 扩缩容:在线扩缩容。
- 跨集群复制:不支持。
- 性能规格:性能规格)
- 使用限制:使用限制)
- Redis版本兼容:单机/主从版2.8,集群版4.0
华为云
华为云提供两种Proxy模式的集群:Codis与Redis原生集群。原生集群不带LB与Proxy。
- 计算/存储/网络:与Redis规格绑定,不可指定flavor。
- LB:100万QPS。
- Proxy:数量不可指定。
- 多DB:集群不支持多DB。
- 副本数:2
- 读写分离:不支持。
- 扩缩容:在线扩容。
- 跨集群复制:不支持。
- 性能规格:性能规格))
- 使用限制:使用限制)
- Redis版本兼容:2.8, 3.x, 4.0, 5.0
更多云最佳实践 https://best.practices.cloud/
以上是关于Redis最佳实践的主要内容,如果未能解决你的问题,请参考以下文章