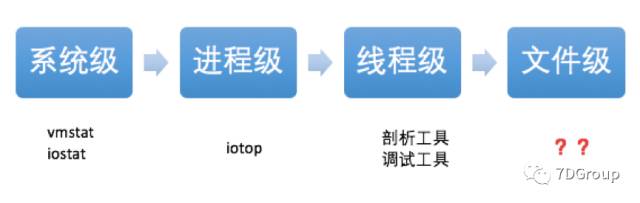
性能分析之IO分析-从IO高到具体文件
Posted Zee_7D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能分析之IO分析-从IO高到具体文件相关的知识,希望对你有一定的参考价值。
IO的性能分析一直是性能分析的重点之一,分析的思路是:

在代码的逻辑清晰的情况下,是完全可以知道哪些文件是频繁读写的。但是对性能分析人员来说,通常是面对一个不是自己编写的系统,有时还是多个团队合作产生的系统。这时就会出现很多的推诿和争执。如果可以迅速地把问题到一个段具体的代码,到一个具体的文件,那就可以提高沟通的效率。
通常情况在linux 环境下,通过 vmstat 或者 iostat 命令可以发现磁盘IO的异常,可以看到系统级的磁盘读写量及CPU占用率,但无法明确定位到是什么进程在作祟,安装iotop 后,可以定位到进程,但并不知道改进程在操作什么文件。
本文是考虑从系统级的工具来完成这个操作,比较具有通用性。在这之前需要先理解一下文件的一个重要的属性:inode。什么是inode呢?先来看一个示意图:
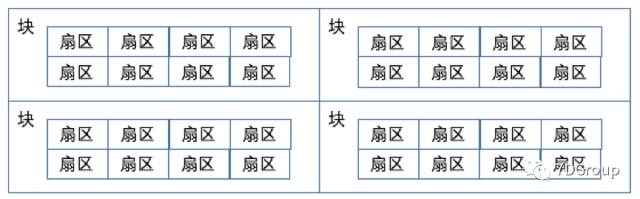
磁盘上最小的存储单元是扇区sector,每8个扇区组成一个块block(4096字节)。如下所示:
|
[root@7DGroup2 ~]# tune2fs -l /dev/vda1|grep Block Block count: 10485504 Block size: 4096 Blocks per group: 32768 [root@7DGroup2 ~]# |
文件的存储就是由这些 块组成的,当块多了之后就成了如下这样(其实磁盘上的块比这个图中多得多,这里只是示意图):
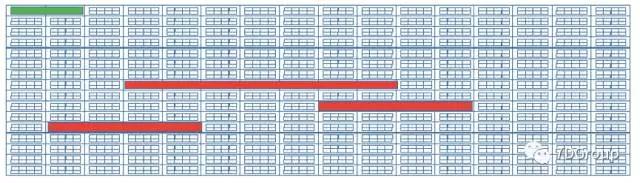
其中红色的这部分是存储的文件,我们通常在文件系统中直接ls或者用其他命令操作文件的时候是根据路径来操作的,那些是上层的命令。当我们执行了一个命令之后,操作系统会来找到这些文件做相应的操作,怎么找到这些文件呢,那就需要inode了。Inode用来存储这些文件的元信息,也就是索引节点,它包括的信息有:
· 字节数
· User ID
· Group ID
· 读、写、执行权限
· 时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间
· 链接数,有多少文件名指向这个inode
· 文件数据block的位置
通过这些信息,我们才能实现对文件的操作。这个inode其实也是存储在磁盘上的,也需要占用一些空间,如上图中的绿色部分所示。
当我们在系统级看到IO过高的时候,比如下图所示:
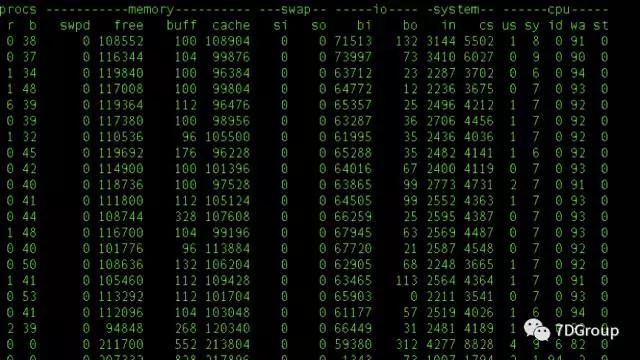
从上图可以看到,这系统几乎所有的CPU都在等IO。这时怎么办?就用我们前面提到的分析的思路,查看进程级和线程级的IO,进而找到具体的文件。下面我们来具体实现。
这里我们用的是systemtap,这个工具7Dgroup之前的文章中提到的,但没有展开说。后面如果有可能我们再多写些类似的工具原理和使用方法。
Systemtap的逻辑图如下:
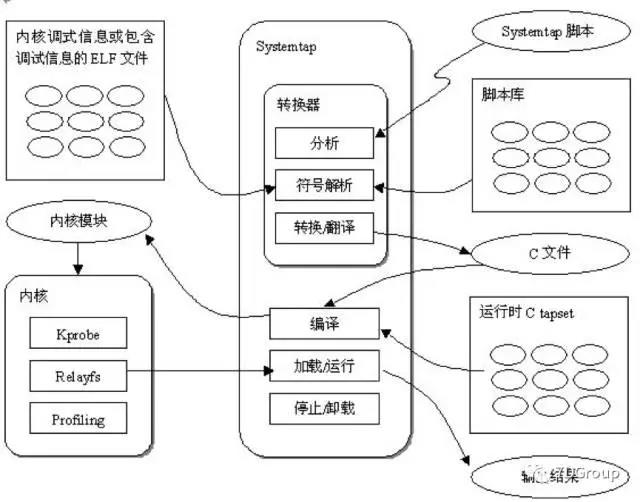
从逻辑图上看,它工作在内核层面,不是shell的层面。
SystemTap为我们开启了一扇通往系统内核的大门,SystemTap 自带的examples中提供一些磁盘IO相关的监控例子。
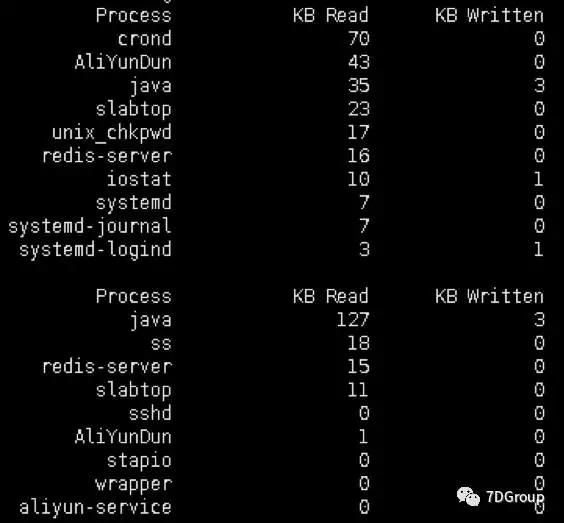
该脚本有两个问题:
-
按照进程名字统计,存在统计误差,进程名一致,但PID不一样的进程,都统计到一起;
-
我们依然不能知道进程操作了什么文件。
通过对probe点的分析(sudo stap -L\'vfs.{write,read}\'),我们可以知道,vfs.read,vfs.write有局部变量 ino 可以利用,ino 是文件的inode,这样我们就可以明确的探测到读写量最多的进程及文件。
我们来做个实验,执行dd命令来做一个高磁盘读写操作。
dd bs=64k count=4k if=/dev/zero of=test oflag=dsync
这条命令执行的效果是:dd在执行时每次都会进行同步写入操作,每次从/dev/zero 读取64k数据,然后写入当前目录下的test文件,一共重复4K次。在linux系统中, /dev/zero 是一个特殊的文件,当你读它的时候,它会提供无限的空字符(NULL, ASCII NUL, 0x00)。
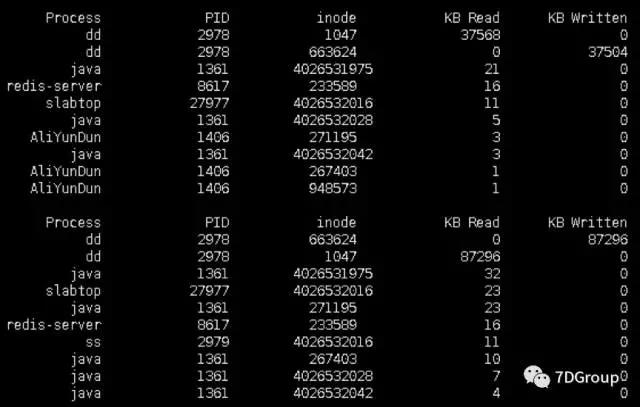
通过监控,我们知道了,PID 为 2978 的 dd 进程 读取 inode 为1047的文件,写入inode为 663624的文件,这两个是读写最多的操作。
通常情况下,我们并不知道inode对应文件的位置,可以通过 find / -inum 1047 找到对应的文件。
|
$ stat /dev/zero 文件:"/dev/zero" 大小:0 块:0 IO 块:4096 字符特殊文件 设备:5h/5d Inode:1047 硬链接:1 设备类型:1,5 权限:(0666/crw-rw-rw-) Uid:( 0/ root) Gid:( 0/ root) 环境:system_u:object_r:zero_device_t:s0 最近访问:2017-05-02 10:50:03.242425632 +0800 最近更改:2017-05-02 10:50:03.242425632 +0800 最近改动:2017-05-02 10:50:03.242425632 +0800 创建时间:- |
这个分析思路在任何一个系统中都可以说是能用的,只是不同的系统用的工具不同。这次用的环境是CentOS,那在其他的系统中,只能找到相对应的其他工具了。
再次强调,了解原理、理清思路是性能分析的重点。工具的使用是为了验证思路的正确性。千万不要舍本逐末。
以上是关于性能分析之IO分析-从IO高到具体文件的主要内容,如果未能解决你的问题,请参考以下文章