Redis源码解析之跳跃表
Posted 北洛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis源码解析之跳跃表相关的知识,希望对你有一定的参考价值。
跳跃表(skiplist)
有序集合(sorted set)是Redis中较为重要的一种数据结构,从名字上来看,我们可以知道它相比一般的集合多了一个有序。Redis的有序集合会要求我们给定一个分值(score)和元素(element),有序集合将根据我们给定的分值对元素进行排序。Redis共有两种编码来实现有序集合,一种是压缩列表(ziplist),另一种是跳跃表(skiplist),也是本章的主角。下面,让笔者带领大家稍微了解下有序集合的使用。
假设某软件公司统计了公司内的程序员所掌握的编程语言,掌握Java的人数有90人、掌握C的人数有20人、掌握Python的人数有57人、掌握Go的人数有82人、掌握php的人数有61人、掌握Scala的人数有28人、掌握C++的人数有33人。我们用key为worker-language的有序集合来存储这一结果。
127.0.0.1:6379> ZADD worker-language 90 Java (integer) 1 127.0.0.1:6379> ZADD worker-language 20 C (integer) 1 127.0.0.1:6379> ZADD worker-language 57 Python (integer) 1 127.0.0.1:6379> ZADD worker-language 82 Go (integer) 1 127.0.0.1:6379> ZADD worker-language 61 PHP (integer) 1 127.0.0.1:6379> ZADD worker-language 28 Scala (integer) 1 127.0.0.1:6379> ZADD worker-language 33 C++ (integer) 1
将上面的统计结果形成一个有序集合后,我们可以对有序集合进行一些业务上的操作,比如用:ZCARD key返回集合的长度:
127.0.0.1:6379> ZCARD worker-language (integer) 7
可以把集合当成一个数组,使用ZRANGE key start stop [WITHSCORES]命令指定索引区间返回区间内的成员,比如我们指定start为0,stop为-1,则会返回从索引0到集合末尾所有的元素,即[0,6],如果有序集合里面有10个元素,则[0,-1]也代表[0,9],带上WITHSCORES选项,除了返回元素本身,也会返回元素的分值。对比我们之前向有序集合插入元素的顺序,以及下面返回元素的顺序可以发现,有序集合会对我们所插入的元素进行排序。
127.0.0.1:6379> ZRANGE worker-language 0 -1 WITHSCORES 1) "C" 2) "20" 3) "Scala" 4) "28" 5) "C++" 6) "33" 7) "Python" 8) "57" 9) "PHP" 10) "61" 11) "Go" 12) "82" 13) "Java" 14) "90"
获取索引[2,5]的数据:
127.0.0.1:6379> ZRANGE worker-language 2 5 WITHSCORES 1) "C++" 2) "33" 3) "Python" 4) "57" 5) "PHP" 6) "61" 7) "Go" 8) "82"
除了可以根据索引来查找元素,还可以通过ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]查找分值区间的元素,并决定返回元素的偏移和数量,min为起始分值,max为结束分值,LIMIT选项会要求传入两个参数,offset和count,分别是:偏移量和根据偏移量返回的最大条目。
127.0.0.1:6379> ZRANGEBYSCORE worker-language 25 85 WITHSCORES 1) "Scala" 2) "28" 3) "C++" 4) "33" 5) "Python" 6) "57" 7) "PHP" 8) "61" 9) "Go" 10) "82" #[25,85]区间的元素有[Scala,C++,Python,PHP,Go],加上LIMIT选项仅查询从偏移1开始(包含偏移1)往后的3个元素 127.0.0.1:6379> ZRANGEBYSCORE worker-language 25 85 WITHSCORES LIMIT 1 3 1) "C++" 2) "33" 3) "Python" 4) "57" 5) "PHP" 6) "61"
至此我们大致了解有序集合的使用,这里就不再对有序集合的API做过多介绍,有兴趣可以查阅官方文档。
下面我们说说有序集合的使用场景,得益于Redis的有序集合,使得很多高并发场景下的业务得以实现,例如:排行榜、聊天服务。像新浪微博的热搜,本质上就是一个排行榜,根据用户对话题的点击量或者讨论程度对话题进行排序;聊天服务某种程度上也可以看做一个排行榜,因为比较早的聊天内容都排在前面。如果用有序集合来实现热搜,我们可以用话题作为元素,用户点击讨论量作为分值;同理如果用有序集合来实现聊天服务,我们可以把用户id和用户聊天内容作为元素,而聊天时间戳作为分值。
从上面的业务场景,大家可以知道Redis的有序集合可以适配很多业务场景,那么下面笔者就带大家来了解下跳跃表的数据结构。
在Redis中如果一个有序集合的编码是skiplist,实质上用的是zset这个数据结构,根据下面的节选可以看到,zset本身又包含两种数据结构:dict和zskiplist。这两个数据结构一目了然,dict是字典、zskiplist即是跳跃表,为何zset除了zskiplist还需要dict?这个问题笔者会在后面解释,我们先来了解zskiplist和zskiplistNode 的数据结构。
server.h
typedef char *sds;
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
观察zskiplist和zskiplistNode ,我们可以从zskiplist的字段里面发现有一个头指针(header)和一个尾指针(tail),而zskiplistNode的字段里有一个backward指针,level数组里每个元素都有一个forward指针,我们可以猜测,跳跃表具有双端链表的特性。除了backward指针和level数组,zskiplistNode还有ele和score两个字段,ele是char类型的指针,score是double类型。因此,我们基本可以确定之前加入到跳跃表的元素和分值是存储在zskiplistNode这个数据结构中的。每个跳跃表节点(zskiplistNode )会有一个后继指针,指向自己身后的元素,并且level数组中每一层都可能存储一个前驱指针forward和一个跨度span,forward指针会指向往前一个、往前两个……往前N个的节点,当我们要查找一个节点,可以从高层横跨多个节点往前遍历,跳跃表由此得名。
zskiplist还剩length和level两个字段,length代表这个跳跃表有多少个跳跃表节点,level代表跳跃表的最高层高。可能还有人对上面对跳跃表的描述存有疑惑,这里笔者画了一幅跳跃表的案例图,我们可以根据下图加固一下对跳跃表的理解。
如上图所示,跳跃表(zsl)会指向一个表头(header),这个表头的层高一般为32,表头不会存放元素(ele)和分值(score),也没有后继指针(backward),所以表头这三块内存置灰。表头有32层可用跳跃层(zskiplistLevel),这32层不一定会全部都用,具体看目前存储元素和分值的节点中最高层是多少。比如上图最高层为Python节点的6层,所以表头的已使用层高也为6。存储元素和分值的节点会有一个随机算法去生成层高,越往上的层高越难达到,从上图我们也可以看到,除了表头,每个节点的跳跃层(zskiplistLevel)高度都是不固定的。跳跃层有两个字段:forward和span,forward用于存储前驱节点的地址,span(跨度)有两个作用:(1)如果forward不为NULL,则用于记录当前节点到达前驱节点本身在内需要经历几个节点,比如:表头的L3层到达Python节点,需要经历4个节点;C节点的L2层到达C++节点,需要经历2个节点;Python节点的L1层到达Java节点,需要经历3个节点。(2)如果forward为NULL,则记录当前节点之后有多少个节点,比如上图的Python节点,从L3~L5的forward都为NULL,则span记录从Python节点之后还存在多少个节点,如果是跳跃表末尾的节点,那么forward为NULL,span为0。
得益于层高的不固定,跳跃表相比一般的链表多了一个跳跃的功能,比如我们想查[80,100]的元素,我们不需要像链表一样逐个递进判断分值是否落在我们的区间内,我们只要找到跳跃表中分值小于80但最靠近80的节点,这里我们可以从头结点的最高层(L5)开始遍历,直接到达Python结点,Python结点的分值为57,小于80,于是我们基于Python结点逐层判断该层是否包含前驱节点,Python.level[5].forward、Python.level[4].forward、Python.level[3].forward都为NULL,直到Python.level[2].forward(PHP)不为空,这里判断PHP.score依旧小于80,于是我们前进到PHP节点并基于该节点逐层往下判断,PHP.level[2].forward.score(Java.score)为90>80,这里我们不能再往前进,依旧基于PHP节点逐层下降,PHP.level[1].forward.score(Go.score)为82>80,依旧不能前进,要基于PHP节点下沉,一直到PHP.level[0].forward.score(Go.score)为82>80,我们就可以确定我们要基于PHP节点是最小于80但最靠近80的节点。于是,我们便基于PHP节点从L0开始逐个递进,查找分值介于[80,100]区间的节点,这里从L0层逐个递进是因为L0层相当于普通链表,不会出现跳跃的情况。
除了可以用分值来查找元素,还可以将跳跃表当成一个数组,根据索引来查找元素,比如我们想查询索引5之后的所有元素,即[5,-1],我们可以获取这个跳跃表的长度推算末尾索引为7+(-1)=6,所以我们只要查找索引落在[5,6]区间的元素就行,换算成跨度(span),我们要寻找跨度落在[6,7]之间的元素。这里我们依旧是从头节点的最高层开始遍历,从头节点的L5层出发,我们前进4个节点到达Python节点本身,此时跨度为4,Python.level[3,5]没有前驱节点,于是基于Python节点下降到L2,Python.level[2]前进一个跨度到PHP节点,此时跨度为5,处于PHP节点的L2层的跨度为2,5+2>6,所以我们需要基于PHP节点下沉一个跳跃层到L1,PHP.level[1].span为1,表明只要我们前进到PHP.level[1].forward所指向的节点,就是我们的开始节点。只要找到开始节点,我们从开始节点的L0层逐个递进,最终就能找到跨度落在[6,7],即索引在[5,6]的元素。
至此,我们大约了解了跳跃表的结构以及它是如何根据分值和索引查找元素。那么接下来,我们要真正进入到跳跃表的源码来了解它的数据结构。
如下代码所示,在创建跳跃表时,会为跳跃表分配一块内存区域,并设置初始层高为1,元素个数为0,之后创建头结点,头结点的层高为32,头结点没有元素、分值和后继指针,创建好头结点后,初始化头结点每个跳跃层的前驱指针为NULL、跨度为0,再设置跳跃表的初始尾结点为NULL,如此,一个跳跃表就初始化完毕。
//server.h
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
/* t_zset.c
* Create a new skiplist.
创建并返回一个跳跃表
*/
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
//分配空间
zsl = zmalloc(sizeof(*zsl));
//设置起始层次
zsl->level = 1;
//初始元素个数为0
zsl->length = 0;
//初始化表头
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
//初始化层高
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
//设置表头后继指针为NULL
zsl->header->backward = NULL;
//初始表尾指针为NULL
zsl->tail = NULL;
return zsl;
}
//创建跳跃表元素
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
/**
* zskiplistNode最后一个字段为弹性数组,在计算内存占用时不占空间,需要
* 额外分配level*sizeof(struct zskiplistLevel)个字节空间用于存放层高
*/
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
我们模拟下如何向一个跳跃表插入一个节点,来看下面的跳跃表,假设下面的跳跃表是保存某一公司员工们的体重,我们先不管Amy、Lucy、John、Jack、Sam是如何插入到跳跃表中的,我们便基于现有的跳跃表结构,向跳跃表插入一个元素为Rose,分值为95.3的元素。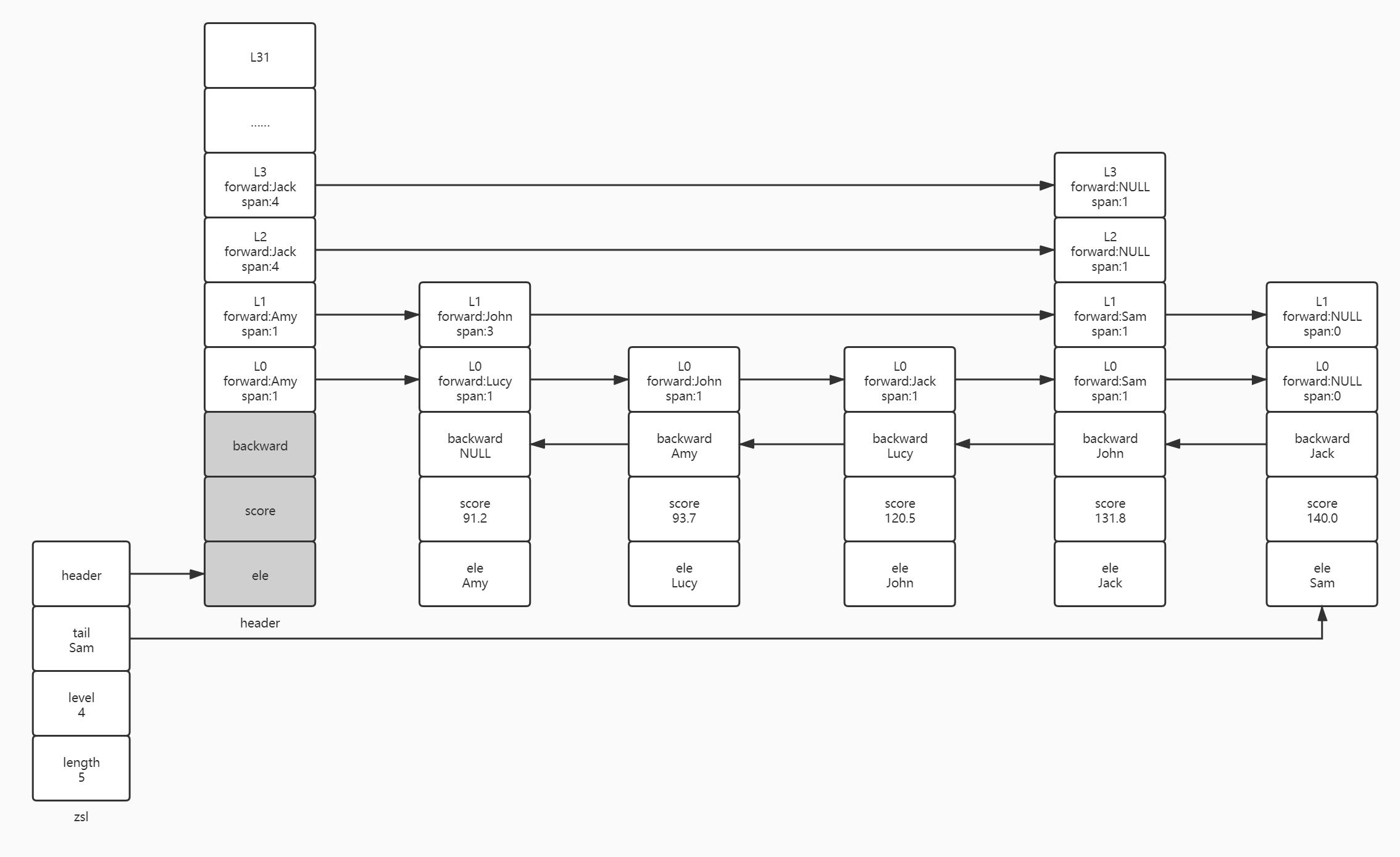
遍观整个跳跃表,我们可以一目了然的确定,Rose应该插在Lucy和John两个节点之间(93.7<95.3<120.5),但计算机没有我们的上帝视觉,所以我们还是要以计算机的角度来查找最适合插入John的位置。John既然要成为跳跃表中的节点,有一点是必不可少的,就是John一定是某些节点的前驱节点,也是某些节点的后继节点。
首先,我们要先查找有哪些节点有可能成为Rose的后继节点,以及记录后继节点在跳跃表中的索引(注:这里的索引也包含头节点),方便在插入新节点时,同时更新跨度。查找后继节点索引从最高层开始,初始索引值为0,如果我们所处的层高允许我们从当前节点进入到下一个节点,则把当前节点的跨度加到索引值上。下一层的后继节点索引值基于上一层统计的索引值,再判断当前层所处的节点是否允许前进到下一个节点,允许的话就把当前层的跨度加到索引值上。
我们从头节点(header)的最高层出发,头节点初始索引为0,header.level[3].forward.score(Jack.score)为131.8,由于Jack.score>Rose.score(131.8>95.3),所以我们不能基于Jack节点前进,并且记录header为L3层的后继备选节点,记录L3层的后继节点索引为0;同理header也为L2层的后继备选节点,L2层的后继节点索引也为0。到达L1层时我们判断header.level[1].forward.score(Amy.score,96.2)<120.3,于是我们从头节点前进到Amy节点,当尝试前进到Amy.level[1].forward节点时,判断Amy.level[1].forward.score(Jack.score)>120.3不能前进,所以我们记录Amy节点为L1层的后继备选节点,L1层的后继节点索引为1。之后,我们要计算L0的后继节点及索引,这里我们不再从header节点的L0层逐个递进,而是基于Amy节点下沉至L0逐个递进,在向Amy.level[0]层递进前,我们先把L1层统计的后继节点索引值作为L0层的初始索引值,因为我们在L0层是基于Amy节点开始递进,而不是基于header节点递进,要弥补在L0层从header递进到Amy节点损失的索引值。我们基于Amy.level[0]一路前进到Lucy节点,将Lucy节点作为L0层的后继备选节点,而Lucy不能再前进到John,所以L0层的初始索引值+Lucy.level[0].span=1+1=2。至此,我们完成了最高层L3到L0的后继节点及其索引的统计,我们用两个数组update和rank分别记录Rose的后继备选节点update[Lucy,Amy,header,header]以及不同层后继节点的索引rank[2,1,0,0]。
记录Rose的后继备选节点update很好理解,我们可以在不同层将原先后继节点指向的前驱节点赋值给Rose的前驱节点,再将后继节点的前驱节点指向Rose,这样就相当于把Rose节点插入到跳跃表。那么我们又如何根据不同层的后继节点索引来更新跨度呢?我们用rank[0]-rank[i](i<zsl->level)得到的结果为新插入节点到每一层后继节点中间的节点个数,比如rank[0]-rank[1]=1,Rose节点和Amy节点中间隔了一个Lucy节点,rank[0]-rank[2]=2,Rose节点和header节点中间隔了Amy和Lucy节点。所以,新插入节点到前驱节点的跨度为原先后继节点的跨度-(rank[0]-rank[i]),后继节点到新插入节点的跨度为rank[0]-rank[i]+1。
现在,让我们为Rose生成一个随机层高,并根据层高、分值和元素创建一个新的节点。这里我们分3种情况来讨论John节点的插入:
- Rose的层高小于当前跳跃表最高层高。
- Rose的层高等于当前跳跃表最高层高。
- Rose的层高高于当前跳跃表最高更高。
首先,我们来讨论Rose的层高小于最高层的情况,假设随机算法为Rose生成了L1的层高,我们从L0层开始更新跳跃表的引用,从上面的分析结果我们可以知道,Rose的L0后继节点为Lucy,我们将Lucy的前驱节点赋值给Rose的前驱节点:Rose.level[0].forward=Lucy.level[0].forward(John),接着我们更新Lucy的前驱节点为Rose:Lucy.level[0].forward=Rose,之后我们要更新L0层Lucy和Rose节点的跨度,由于是在L0层,相当于普通链表,所以Lucy在L0层指向Rose的跨度和Rose在L0层指向John的跨度都为1。
然后,我们在更新L1层的引用和跨度,Rose在L1层的后继节点为Amy,这里我们依旧把Amy在L1指向的前驱赋值给Rose在L1的前驱:Rose.level[1].forward=Amy.level[1].forward(Jack),再把Amy在L1的前驱指向Rose:Amy.level[1].forward=Rose。接着我们更新Amy和Rose的跨度,这里先更新Rose指向Jack的跨度,再更新Rose:Amy指向Rose的跨度,因为在更新Rose指向Jack的跨度需要用到原先Amy在L1层指向Jack的跨度:Rose.level[1].span=Amy.level[1].span-(rank[0]-rank[1])=2,接着更新Amy指向Rose的跨度:Amy.level[1].span=(rank[0]-rank[1])+1=2。
L2和L3层的后继节点都是header,由于Rose节点没有足够的层高让其指向,所以这里我们简单地对L2和L3的后继节点的跨度+1即可。
再来,我们考虑第二种情况,如果给Rose生成的层高刚好等于跳跃表当前的层高的,即Roese的层高为L3。这里我们依旧延续之前的思路,先更新新插入节点的前驱节点跨度,再更新后继节点指向新节点的跨度。Rose节点L0、L1如何更新看上一个步骤,这里不再赘述。我们从L2开始更新,这里笔者重新贴以上Rose节点未插入前的后继备选节点update:[Lucy,Amy,header,header]及不同层后继节点的索引rank:[2,1,0,0]。首先将L2的后继节点指向的前驱赋值给Rose节点L2的前驱:Rose.level[2].forward=header.level[2].forward(Jack),再将L2后继节点的前驱指向Rose节点:header.level[2].forward=Rose。接着我们更新跨度,Rose.level[2].span=header.level[2].span-(rank[0]-rank[2])=4-2=2,header.level[2].span=(rank[0]-rank[2])+1=3。L3同L2也是一样的逻辑,这里就不再演示。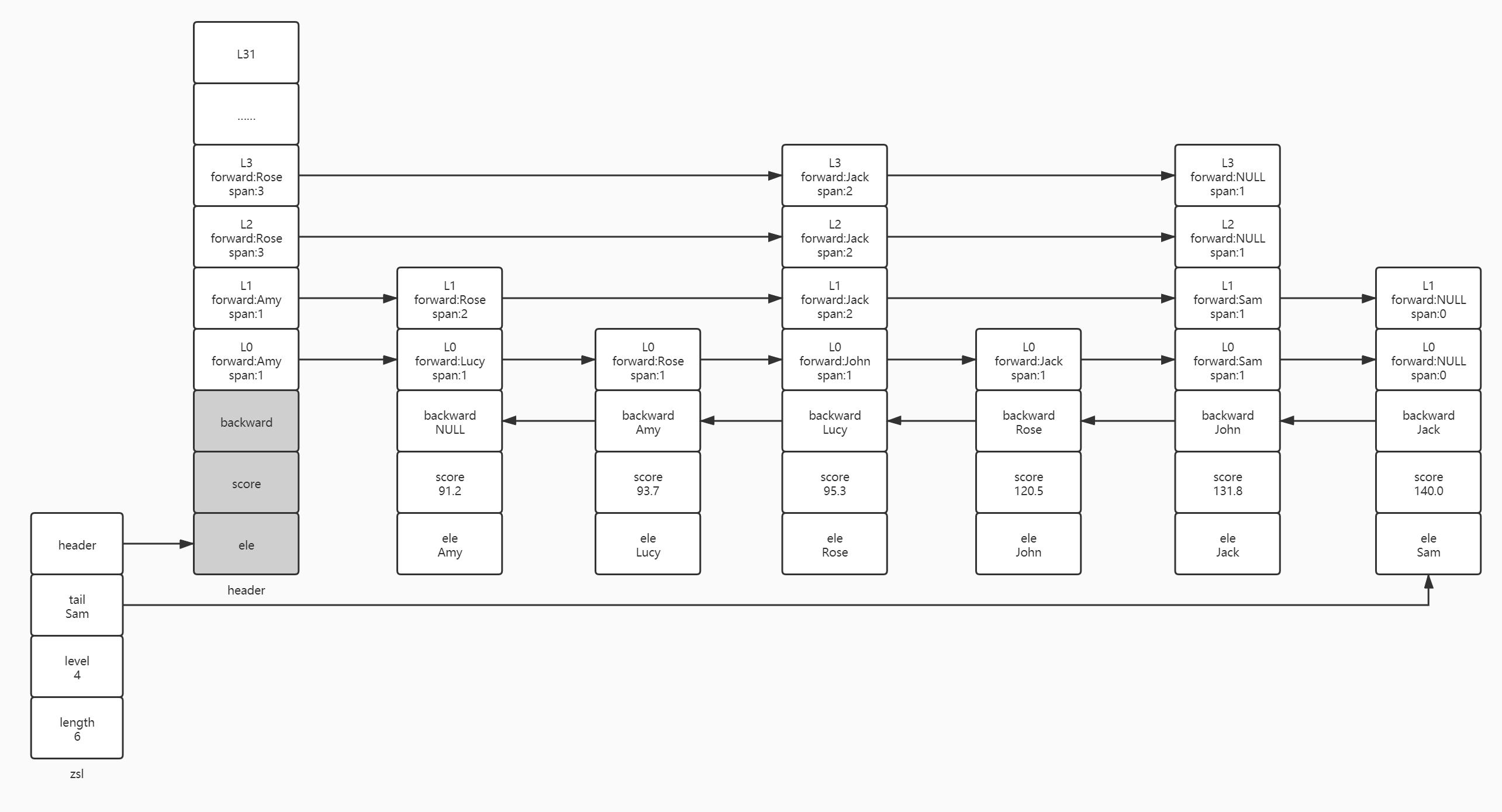
最后,我们考虑Rose节点大于跳跃表最高层。首先我们思考下,假设随机算法为Rose生成的层高为L4、L5……L6甚至L31,目前跳跃表最高层高为L3,那么大于L3之后的层高的后继节点是什么呢?也就只有头节点了,那么大于跳跃表更高层的后继节点索引也就呼之欲出了,头节点的索引只能是0。因此,我们的update和rank数组需要更新为[Lucy,Amy,header,header,header……header]和[2,1,0,0,0……,0],那么新层高的跨度又要怎么计算呢?首先头节点到新节点的跨度依旧是(rank[0]-rank[n])+1,其次新节点>L3的层高的前驱节点为NULL,层高中的跨度要更新为当前节点之后节点的个数,需要用跳跃表中元素的个数减去新插入节点到后继节点(头节点)之间节点的个数,即zsl-length-(rank[0]-rank[n])=5-2=3(n>3)。所以只要Rose节点的层高大于L3,L3之上的forward为NULL,跨度为Rose之后节点的个数(John、Jack、Sam),而header.level[n]到Rose的跨度为(rank[0]-rank[n])+1=2+1=3(n>3)。

按照之前笔者模拟的新节点插入到跳跃表的思路,我们来看下Redis又是如何实现的:
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string \'ele\'.
* 将一个新节点插入到跳跃表。
* */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
/*
* update数组会记录每一层最靠近新插入节点的后继节点,rank数组
* 最靠近新插入节点的后继节点索引。
*/
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;//<1>
//从头节点最高层出发,查找每一层最靠近新节点的后继节点
for (i = zsl->level - 1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position
* rank数组记录每一层最靠近新节点的后继节点索引,从最高层开始查找时初始索引为0,
* 即初始rank[zsl->level-1]=0,如果能从当前节点前进到下一个节点,则把当前节点的跨度
* 加到索引值上。当处于i层前进到最靠近新节点的后继节点不能再前进时,则下沉一层,
* 基于当前前进到的后继节点继续尝试往i-1层前进,而i-1层的初始索引值为i层最后统计的
* 索引值,因为i-1层不会从header节点逐个递进,而是基于上一层前进到的节点递进,所以
* 要弥补i-1层的索引要弥补header前进到当前节点的索引值。
*/
rank[i] = i == (zsl->level - 1) ? 0 : rank[i + 1];
/*
* x初始值为header(见<1>处),如果x在i层的前驱节点不为NULL,则x有可能前进到前驱节点,
* 即x在i层指向的前驱节点有可能成为新节点的后继节点,但x能否前进要进一步判断,这里有
* 两个条件决定前进:
* 1.如果x前驱节点的分值小于新节点的分值,则可以前进(x->level[i].forward->score < score)
* 2.前驱节点的分值与新节点分值相同,且前驱节点的字符串小于新节点的字符串,则允许前进。注意:
* 这里比较字符串并非比较字符串长度,sdscmp(x->level[i].forward->ele,ele)会进一步调用
* 函数memcmp(s1,s2,n),比较两个字符串的s1和s2的前n个字节。
* (x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)
*/
while (x->level[i].forward &&
(x->level[i].forward->score < score || //
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele, ele) < 0))) //
{
/*
* 如果判定x节点可以前进到前一个节点,则把当前节点的跨度加到索引值上,
* 并将x指向的内存区域更新为下一个节点。
*/
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
//x一直前进到不能再前进,即代表x所指向的节点为i层最靠近新节点的后继节点,记录后继节点
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not.
*
* */
/*
* 这里会用随机算法生成一个层高,越往上的层高越难生成,
* 并且保证层高一定<=ZSKIPLIST_MAXLEVEL,下面会附上
* 生成层高的代码。
*/
level = zslRandomLevel();
/*
* 如果当前生成的层高大于跳跃表最高层高,还需要更新大于等于zsl->level
* 层的后继节点和节点索引。大于等于zsl->level层的后继节点只能是头节点,
* 因此后继节点索引都为0,同时更新这些后继节点的跨度为跳跃表节点数,便于
* 后续更新跨度。
*/
if (level > zsl->level) {//<2>
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
//更新跳跃表层高为目前生成的层高
zsl->level = level;
}
//根据层高、分支和元素创建一个跳跃表节点
x = zslCreateNode(level, score, ele);
//将新节点插入到跳跃表中,并更新跨度
for (i = 0; i < level; i++) {
/*
* update[i]为新节点在i层的后继节点,将新节点在i层指向的前驱更新
* 为后继节点指向的前驱。再将后继节点在i层的前驱更新为新节点。如此,
* 新节点便插入到跳跃表中。
*/
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here
* (rank[0] - rank[i])为新节点和第i层后继节点中间隔了多少个节点,
* 在i层x到前驱节点的跨度(x->level[i].span)为原先后继节点的跨度减去
* 新节点和第i层后继节点中间的节点个数:
* (update[i]->level[i].span - (rank[0] - rank[i]))
* 后继节点在新节点的跨度为:(rank[0] - rank[i]) + 1
* 如果程序之前曾进入到分支<2>,即执行level = zslRandomLevel()生成的层高
* 高大于原先跳跃表的层高,比如原先zsl->level为3,但level生成为10,则新节点L3~L9
* 的后继节点为头节点,后继节点索引值为0,新节点L3~L9的前驱为NULL,跨度为新节点之后
* 的节点个数,而zsl->length - (rank[0] - rank[i])为新节点之后的节点个数。
*/
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels
* 如果level = zslRandomLevel()生成的层高大于原先zsl->level的
* 层高,则不会进入此循环。只有当生成的层高小于原先zsl->level的层高,
* 才需要对level<=i<zsl->level的后继节点中的跨度+1,因为新插入一个节点。
*/
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
/*
* L0层相当于普通链表,如果新插入节点在L0层的后继节点为header,则新节点的backward指向NULL,
* 否则指向跳跃表中最靠近新节点的后继节点。
*/
x->backward = (update[0] == zsl->header) ? NULL : update[0];
/*
* 如果新节点不是末尾节点,则将新节点的前驱指点的backward指针指向新节点,
* 否则将跳跃表的末尾指针指向新节点。
*/
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
//插入新节点后,对跳跃表的元素个数+1
zsl->length++;
return x;
}
生成层高zslRandomLevel(void):
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned.
*
* Skiplist P = 1/4
* while 循环中
* 循环为真的概率为 P(1/4)
* 循环为假的概率为 (1 - P)
*
* 层高为1 的概率为 (1 -P)
* 层高为2 的概率为 P *(1 -P)
* 层高为3 的概率为 P^2 *(1 -P)
* 层高为4 的概率为 P^3 *(1 -P)
* 层高为n 的概率为 P^(n-1) *(1 -P)
*
* 因此平均层高为
* E = 1*( 1-P) + 2*P( 1-P) + 3*(P^2) ( 1-P) + ...
* = (1-P) ∑ +∞ iP^(i-1)
* i=1
*
* =1/(1-P)
*
* */
int zslRandomLevel(void) {
int level = 1;
while ((random() & 0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level < ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
以上是关于Redis源码解析之跳跃表的主要内容,如果未能解决你的问题,请参考以下文章