Python高级应用课程设计作业
Posted 2003840129张丰毅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级应用课程设计作业相关的知识,希望对你有一定的参考价值。
一、选题的背景 为什么要选择此选题?要达到的数据分析的预期目标是什么?(10 分) 从社会、经济、技术、数据来源等方面进行描述(200 字以内)
通过爬取数据后数据分析能够直观的看到二手车市场中某一品牌的相对数据,能够了解到现在的二手车市场情况,通过分析数据看到二手车的走势,车商就可以利用这些数据进行定价,让想买二手车却不了解市场的人了解到大概的价格走势,到了店里不会被骗。
二、主题式网络爬虫设计方案(10 分)
1.主题式网络爬虫名称
基于BeautifulSoup的二手车信息爬取和分析
2.主题式网络爬虫爬取的内容与数据特征分析
利用requests和BeautifulSoup爬取瓜子二手车网信息,爬取内容包括二手车的型号、价格、车龄、里程,然后清洗数据后获得自己想要的数据信息。其数据特征表现为:经过数据清洗后获得的数据没有重复值和无效值,让数据更具有说服力。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:绕过反爬获取网页资源,使用etree解析网页,用xpath定位爬取内容标签后爬取资源并将数据保存到csv文件中。
技术难点:设置请求头,for循环实现重复爬取
三、主题页面的结构特征分析(10 分)
1.主题页面的结构与特征分析
链接如下:https://www.guazi.com/fz/audi/
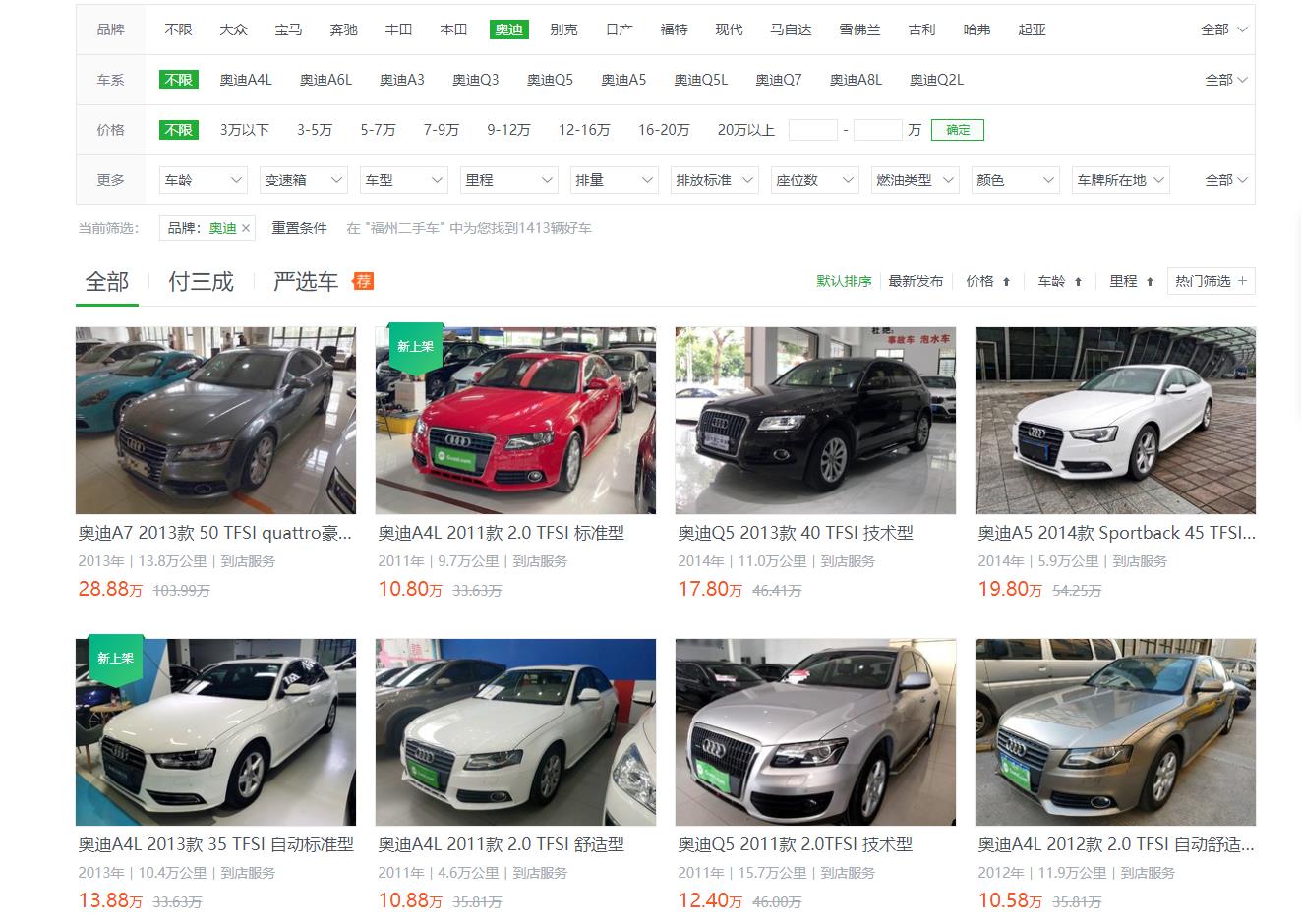
2.htmls 页面解析
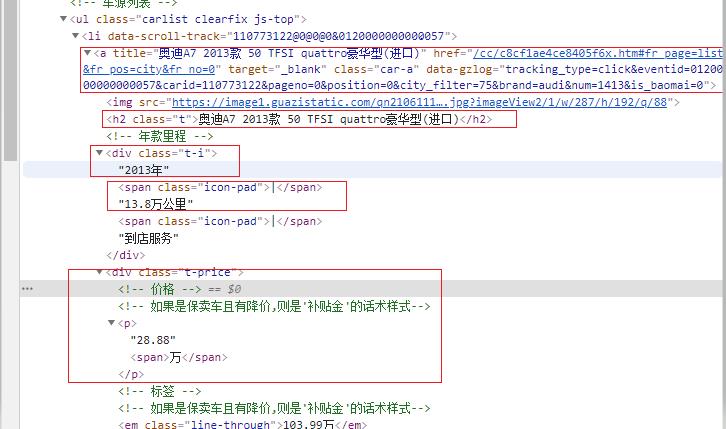
3.节点(标签)查找方法与遍历方法 (必要时画出节点树结构)
查找方法:find_all
遍历方法:for循环遍历
四、网络爬虫程序设计(60 分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后 面提供输出结果的截图。
- 数据爬取与采集
导入库
import requests
from lxml import etree
import time
import re
import pandas as pd
初始化空列表
carname_lis,carage_lis, price_lis, mileage_lis = [], [], [], []
for a in range(10):
#爬取网站的网址并且循环爬取前10页的内容
url = "https://www.guazi.com/fz/audi/{}/#bread".format(a*10)
#设置请求头防止反爬
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
#requests请求链接
resp = requests.get(url,headers=headers).text
#使用lxml模块中的etree方法讲字符串转化为html标签
html = etree.HTML(resp)
#用xpath定位标签位置
lis = html.xpath("/html/body/div[6]/ul/li")
#获取要爬取内容的详情链接
for li in lis:
#爬取车名
carname = li.xpath("./a/h2/text()")[0]
#爬取车龄
carage = li.xpath("./a/div[1]/text()")[0]
#爬取里程
milrage = li.xpath("./a/div[1]/text()[2]")[0]
#爬取价格
price = li.xpath("./a/div[2]/p/text()")[0]
#输出
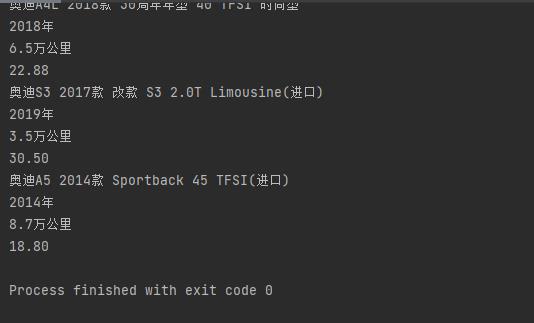
print(carname)
print(carage)
print(milrage)
print(price)
# 将字段存入初始化的列表中
carname_lis.append(carname)
carage_lis.append(carage)
mileage_lis.append(milrage)
price_lis.append(price)
pandas中的模块将数据存入
df = pd.DataFrame({
"型号" : carname_lis,
"车龄" : carage_lis,
"里程" : mileage_lis,
"价格" : price_lis,
})
储存为csv文件
df.to_csv("aodi.csv" , encoding=\'utf_8_sig\', index=False)
- 对数据进行清洗和处理
导入库
import pandas as pd
import numpy as mp
import sklearn
import seaborn as sns
import matplotlib.pyplot as plt
读取csv文件
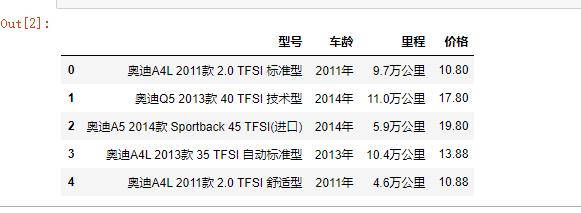
aodi = pd.DataFrame(pd.read_csv(\'aodi.csv\'))
aodi.head()
检查重复值
aodi.duplicated()
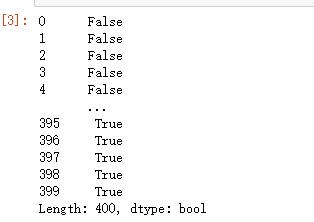
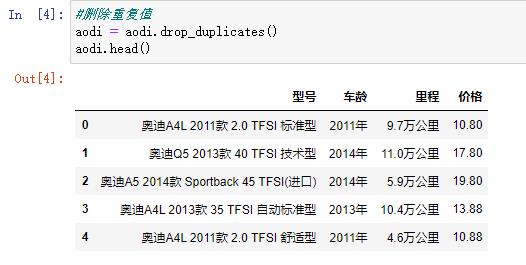
删除重复值
aodi = aodi.drop_duplicates()
aodi.head()
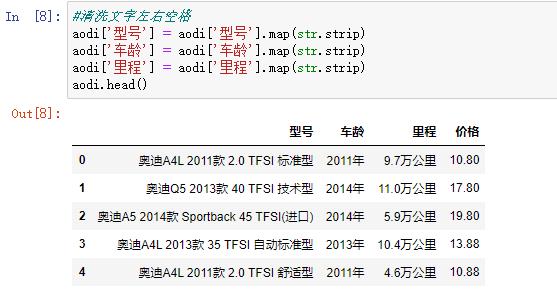
清洗文字左右空格
aodi[\'型号\'] = aodi[\'型号\'].map(str.strip)
aodi[\'车龄\'] = aodi[\'车龄\'].map(str.strip)
aodi[\'里程\'] = aodi[\'里程\'].map(str.strip)
aodi.head()
3.文本分析(可选):jieba 分词、wordcloud 的分词可视化
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
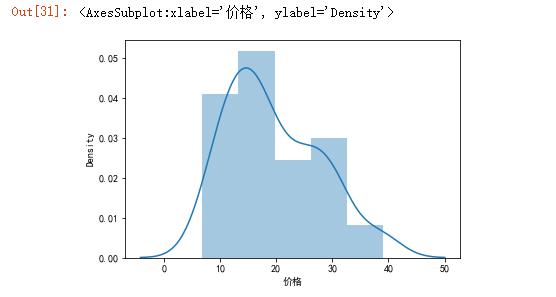
价格直方图
sns.distplot(aodi[\'价格\'])
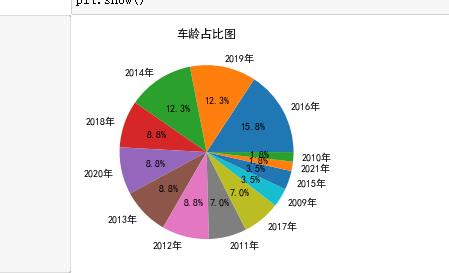
车龄占比饼图
plt.rcParams[\'font.sans-serif\'] = [\'SimHei\']#解决乱码问题
df_score = aodi[\'车龄\'].value_counts() #统计评分情况
plt.title("车龄占比图") #设置饼图标题
plt.pie(df_score.values,labels = df_score.index,autopct=\'%1.1f%%\') #绘图
autopct表示圆里面的文本格式,在python里%操作符可用于格式化字符串操作
plt.show()
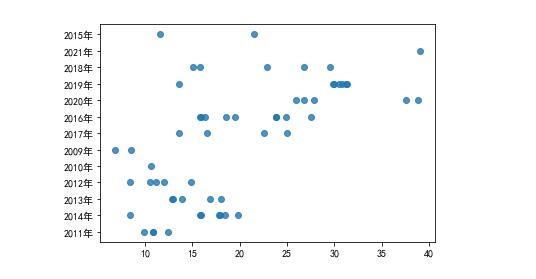
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变 量之间的回归方程(一元或多元)。
绘制散点图查看关系
sns.regplot(x = \'价格\',y = \'车龄\',data=aodi)
6.数据持久化
储存为csv
df.to_csv("aodi.csv" , encoding=\'utf_8_sig\', index=False)
7.将以上各部分的代码汇总,附上完整程序代码
导入库
import requests
from lxml import etree
import time
import re
import pandas as pd
初始化空列表
carname_lis,carage_lis, price_lis, mileage_lis = [], [], [], []
for a in range(10):
#爬取网站的网址并且循环爬取前10页的内容
url = "https://www.guazi.com/fz/audi/{}/#bread".format(a*10)
#设置请求头防止反爬
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
#requests请求链接
resp = requests.get(url,headers=headers).text
#使用lxml模块中的etree方法讲字符串转化为html标签
html = etree.HTML(resp)
#用xpath定位标签位置
lis = html.xpath("/html/body/div[6]/ul/li")
#获取要爬取内容的详情链接
for li in lis:
#爬取车名
carname = li.xpath("./a/h2/text()")[0]
#爬取车龄
carage = li.xpath("./a/div[1]/text()")[0]
#爬取里程
milrage = li.xpath("./a/div[1]/text()[2]")[0]
#爬取价格
price = li.xpath("./a/div[2]/p/text()")[0]
#输出
print(carname)
print(carage)
print(milrage)
print(price)
# 将字段存入初始化的列表中
carname_lis.append(carname)
carage_lis.append(carage)
mileage_lis.append(milrage)
price_lis.append(price)
pandas中的模块将数据存入
df = pd.DataFrame({
"型号" : carname_lis,
"车龄" : carage_lis,
"里程" : mileage_lis,
"价格" : price_lis,
})
储存为csv文件
df.to_csv("aodi.csv" , encoding=\'utf_8_sig\', index=False)
导入库
import pandas as pd
import numpy as mp
import sklearn
import seaborn as sns
import matplotlib.pyplot as plt
读取csv文件
aodi = pd.DataFrame(pd.read_csv(\'aodi.csv\'))
aodi.head()
检查重复值
aodi.duplicated()
删除重复值
aodi = aodi.drop_duplicates()
aodi.head()
清洗文字左右空格
aodi[\'型号\'] = aodi[\'型号\'].map(str.strip)
aodi[\'车龄\'] = aodi[\'车龄\'].map(str.strip)
aodi[\'里程\'] = aodi[\'里程\'].map(str.strip)
aodi.head()
价格直方图
sns.distplot(aodi[\'价格\'])
车龄占比饼图
plt.rcParams[\'font.sans-serif\'] = [\'SimHei\']#解决乱码问题
df_score = aodi[\'车龄\'].value_counts() #统计评分情况
plt.title("车龄占比图") #设置饼图标题
plt.pie(df_score.values,labels = df_score.index,autopct=\'%1.1f%%\') #绘图
autopct表示圆里面的文本格式,在python里%操作符可用于格式化字符串操作
plt.show()
绘制散点图查看关系
sns.regplot(x = \'价格\',y = \'车龄\',data=aodi)
储存为csv文件
df.to_csv("aodi.csv" , encoding=\'utf_8_sig\', index=False)
五、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
(1)14、19、16这三个年份的二手车比较多,老车反而比较少
(2)价格较高的车都是19、20、21这三个年份的
(3)可视化的数据相当直观,一眼就能找到需要的
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
在这次的设计过程中,很多东西都是自己一步一步摸索的,因为有些代码就算一样复制过来也用不了,虽然这次没有完全实现,也还存在一些问题,在解决一个又一个问题之后,我自己也对python这门语言有了更深的理解,也越发觉得有趣。希望自己下次在绘图上可以做的更好。
以上是关于Python高级应用课程设计作业的主要内容,如果未能解决你的问题,请参考以下文章