kafka 消息队列
Posted 祁佩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka 消息队列相关的知识,希望对你有一定的参考价值。
背景
- message bus项目中多处用到了kafka消息队列,对kafka仅知道消息系统这个浅显的认识;对于理解整个项目的实现不够深刻,进而无法从测试角度去评估测试风险;
- 通过调研,国内大厂使用kafka较多,对于这一基本技术应该有所了解;
目标
- 对kafka的基本概念,基本原理,常见应用有所了解。
- 了解messagebus在kafka中的应用
-
消息系统选型
-
测试角度分析kafka的常见问题
开始学习
初印象
Kafka 是由 LinkedIn 开发的一个分布式的消息系统,使用 Scala 编写,它以可水平扩展和高吞吐率而被广泛使用。
1.基本概念
- Producer
- 发布消息的对象称之为主题生产者(Kafka topic producer)
-
Consumer
- 订阅消息并处理发布的消息的对象称之为主题消费者(consumers)
-
Topic
- Kafka将消息分门别类,每一类的消息称之为一个主题(Topic)。
-
Broker
- 已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker)。 消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
-
Partition
- Parition是物理上的概念,每个Topic包含一个或多个Partition.
-
Consumer Group
- 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
以GDS举例:

配置位于:
sip-goservice/config/configold/conf_staging.yaml |
- Producer
- Core Server DB binlog 变化产生消息
-
Consumer
- 下游业务方消费消息
-
Topic
-
商品表:shopee_seller_db_item_staging
- 订单表: shopee_seller_db_order_staging
-
账号表: shopee_seller_db_account_staging
-
-
Broker
-
KAFKA_BROKERS:
"producer_config": {
"addresses": [
"kafka-app-nonlive-sw-01-sg1-live.shopeemobile.com:9092",
"kafka-app-nonlive-sw-02-sg1-live.shopeemobile.com:9092",
"kafka-app-nonlive-sw-03-sg1-live.shopeemobile.com:9092"
]
},
"consumer_config": {
"addresses": [
"gds-kafka-sw-01-sg1-nonlive.shopeemobile.com:9092",
"gds-kafka-sw-02-sg1-nonlive.shopeemobile.com:9092",
"gds-kafka-sw-03-sg1-nonlive.shopeemobile.com:9092"
],
-
-
Partition
- Parition是物理上的概念,每个Topic包含一个或多个Partition.
-
Consumer Group
-
自定义
-
2.基本原理
单节点kafka:
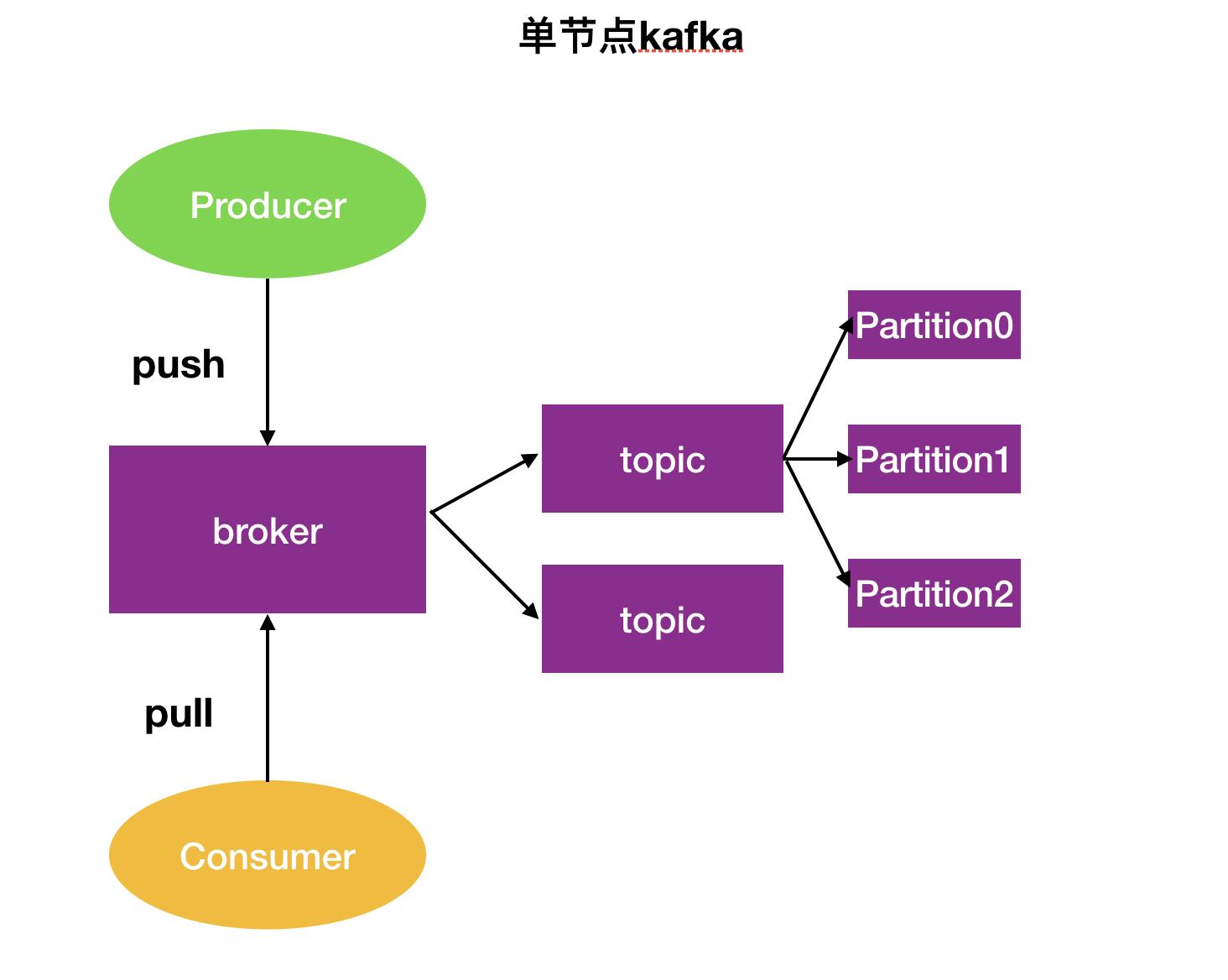
broker → topic → partition
broker 和 topic可以是多对多的关系,其他是一对多。
Topic是发布的消息的类别名,一个topic可以有零个,一个或多个消费者订阅该主题的消息。
对于每个topic,Kafka集群都会维护一个分区log,就像下图中所示:
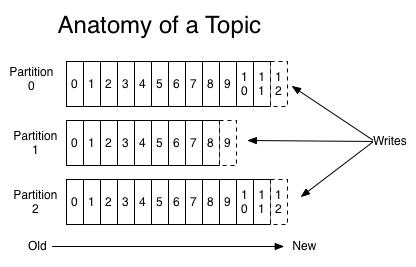
Topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的
Kafka集群保持所有的消息,直到它们过期(无论消息是否被消费)。实际上消费者所持有的仅有的元数据就是这个offset(偏移量),也就是说offset由消费者来控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更早的位置,重新读取消息。可以看到这种设计对消费者来说操作自如,一个消费者的操作不会影响其它消费者对此log的处理。
集群kafka:
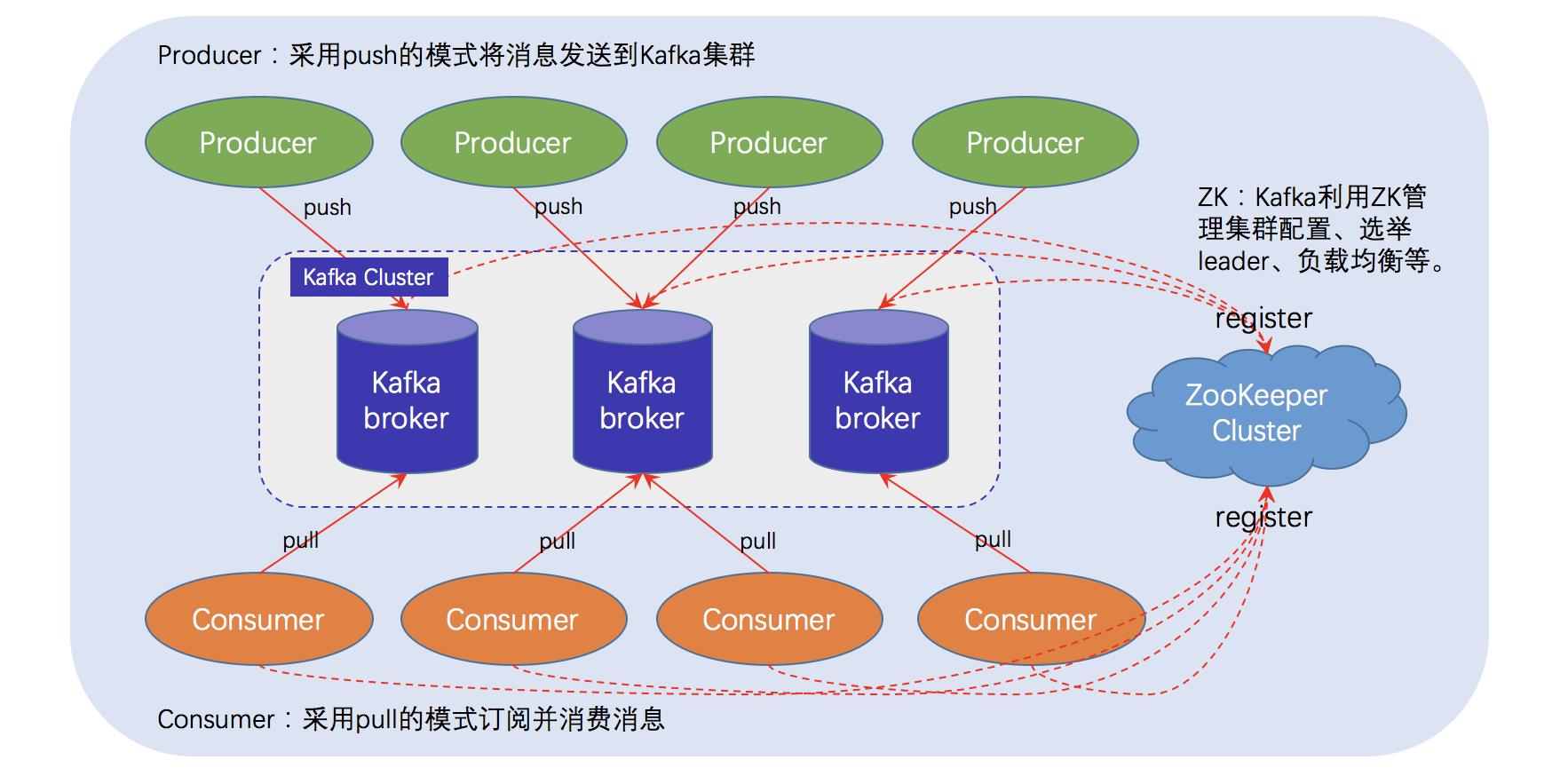
副本同步以及选举:
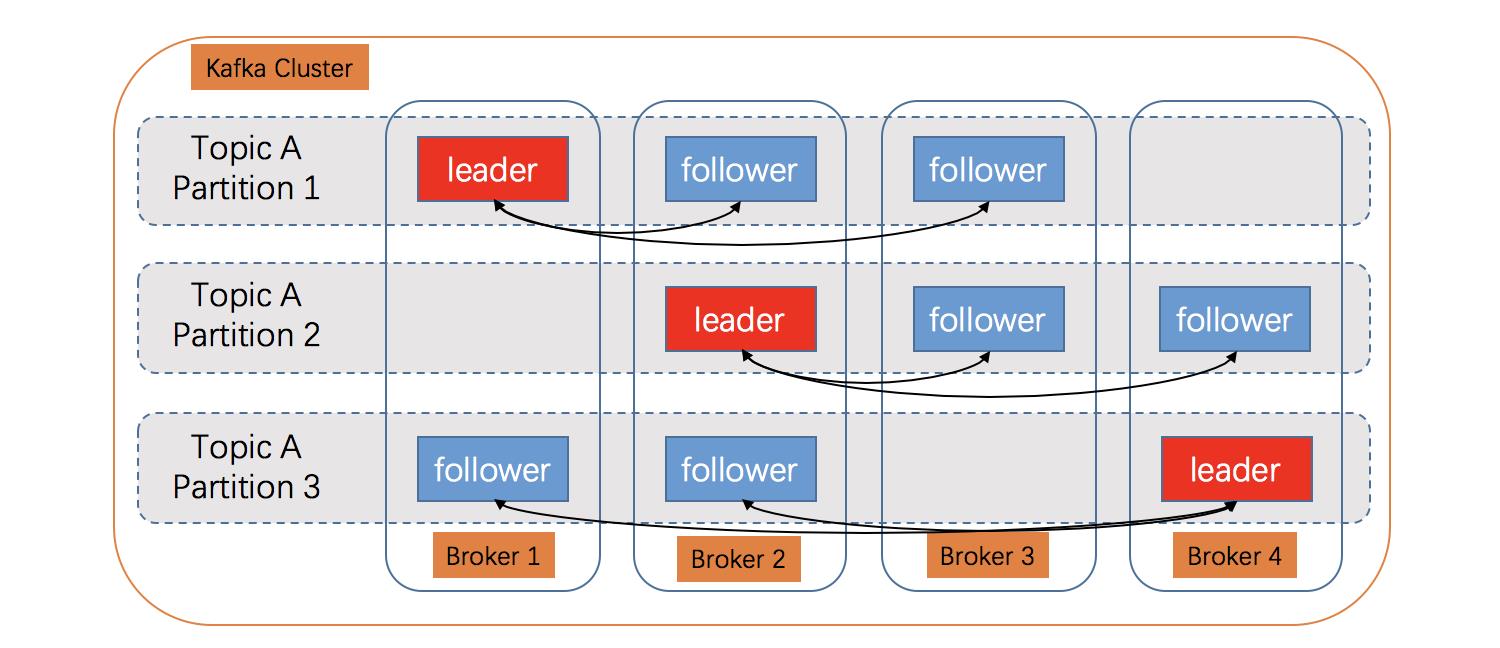
3.常见应用
1.异步处理
消息队列的主要特点是异步处理,主要目的是减少请求响应时间,实现非核心流程异步化,提高系统响应性能。
所以典型的使用场景就是将比较耗时而且不需要即时(同步)返回结果的操作,作为消息放入消息队列。
2.应用解耦

使用了消息队列后,只要保证消息格式不变,消息的发送方和接收方并不需要彼此联系,也不需要受对方的影响,即解耦。
每个成员不必受其他成员影响,可以更独立自主,只通过消息队列MQ来联系。
举一个例子:用户下订单流程,下订单后会发生扣库存这个动作,上游系统订单和下游系统扣库存,就可以通过上图的消息队列MQ来联系,扣库存异步化,从而实现订单系统与库存系统的应用解耦。
3.流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
4.日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。
5.消息通讯
消息队列一般都内置了高效的通信机制,因此也可以用于单纯的消息通讯,比如实现点对点消息队列或者聊天室等。
messagebus 项目在Kafka应用
1.设计文档
2.设计背景简介
- 目前的业务表中 ,一个kafka topic对应了多张物理数据表; 不同的业务方需要各自监控gds binlog ,并且对拿到的message做处理 从而获得自己需要的message ,存在重复作业,冗余度高,不便于管控
- 物理表的变化,如水平拆分,垂直拆分对业务部署影响较大,需要重新部署kafka服务
所以需要提供统一的服务 ,屏蔽基础物理数据库的复杂性以及消息格式的复杂性:
系统设计总览: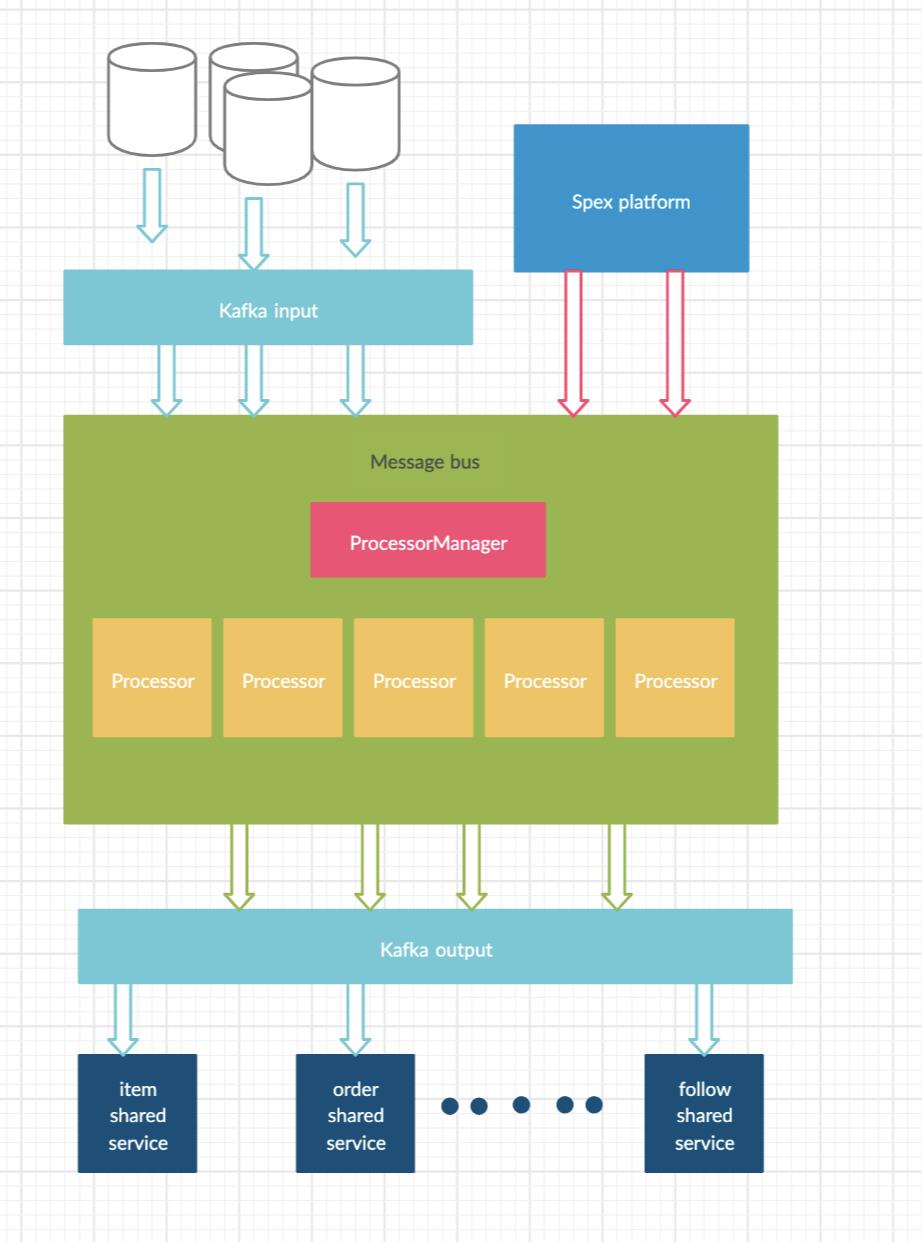
核心模块总览: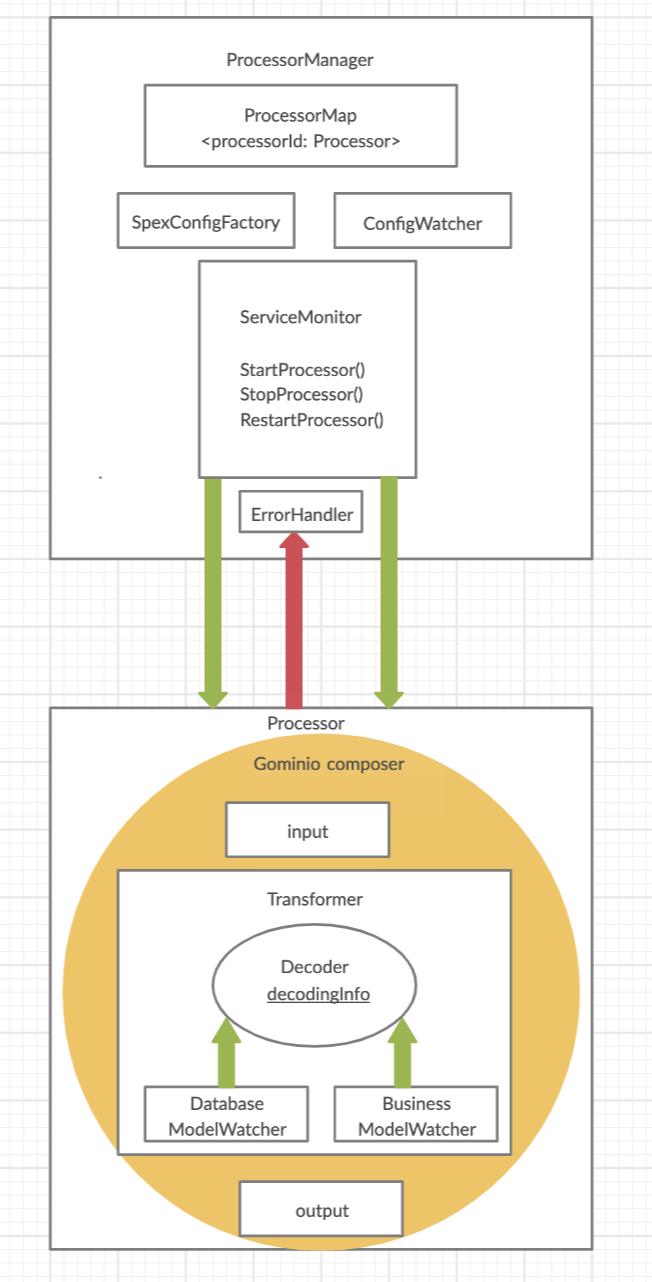
GDS kafka 消费举例:
- 什么是GDS kafka?
- gds 消息是怎么产生的?
- mysql 的 binlog产生;
消息系统选型
Kafka、RabbitMQ、RocketMQ
|
消息中间件
|
基本介绍
|
主要特征
|
备注
|
|---|---|---|---|
| Kafka | 开源,Apache |
优点:高吞吐量; 缺点:不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。 |
|
| RabbitMQ | 开源 |
优点:数据一致性、稳定性和可靠性要求很高的场景 缺点:性能和吞吐量较低; |
|
| RocketMQ | 开源,阿里;RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。 | 优点:高吞吐量、高可用性、适合大规模分布式系统应用 | |
性能吞吐量:Kafka > RocketMQ > RabbitMQ
可靠性:Kafka < RocketMQ < RabbitMQ
总结:根据需要,选择当前业务最适合的。
测试问题分析
- Case 1: kafka的过期时间,超过过期时间,丢弃消息,所以注意应用场景
- Case 2: 2次确认,处理完消息,给kafka再发送一条消息,防止消息丢失。
- Case3:消费者拿到消息之后,服务崩溃/服务超时,消息丢失
可能问题分析
- Case1: 怎么样避免重复消费
- 有的业务不能重复消费,eg:银行算账系统之类的
- Case2:消息先后顺序
- 有的业务强顺序,eg:aiitem price,
- 2种实现方式:直接用kafka的数据
- 读db
- Case3:
- kafka server是不记录消息是否消费?client消不消费消息都在那里,是由client的offset记录消费到了哪里?
- 问题:client经常会重启服务?重启之后offset的值没有了?
-
- kafka记录每个consumer group消费的位置。
-
- kafka server的每个partition维护2个offset,一个是消费的offset, 一个是commit的offset。如果有client重启,新的consumer会从commit的offset开始消费。
- Case4:
- 集群的配置,consumer group 的配置参数如果不对,会导致性能缺陷
- 性能调优问题:
参考文档
kafka 文档:
https://www.orchome.com/5
mac如何本地搭建kafka
https://colobu.com/2019/09/27/install-Kafka-on-Mac/
kafka basic分享&如何写一个consumer程序
https://drive.google.com/file/d/1oQiT0Erx3iMIJxsKTAzJ12x0q6GSPhic/view?usp=sharing
官方文档:
https://kafka.apache.org/quickstart
CDC
https://farer.org/2018/07/27/change-data-capture/
alibaba
https://github.com/alibaba/canal
rabbitmq
rocketmq
源码:https://github.com/apache/rocketmq
专题:https://www.jianshu.com/c/8cfe32491344
以上是关于kafka 消息队列的主要内容,如果未能解决你的问题,请参考以下文章