容器实践线路图
Posted 云最佳实践
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了容器实践线路图相关的知识,希望对你有一定的参考价值。
随着容器技术越来越火热,各种大会上标杆企业分享容器化收益,带动其他还未实施容器的企业也在考虑实施容器化。不过真要在自己企业实践容器的时候,会认识到容器化不是一个简单工程,甚至会有一种茫然不知从何入手的感觉。
本文总结了通用的企业容器化实施线路图,主要针对企业有存量系统改造为容器,或者部分新开发的系统使用容器技术的场景。不包含企业系统从0开始全新构建的场景,这种场景相对简单。
容器实践路线图
企业着手实践容器的路线,建议从3个维度评估,然后根据评估结果落地实施。3个评估维度为:商业目标,技术选型,团队配合。
-
商业目标是重中之重,需要回答为何要容器化,这个也是牵引团队在容器实践路上不断前行的动力,是遇到问题是解决问题的方向指引,最重要的是让决策者认同商业目标,并能了解到支持商业目标的技术原理,上下目标对齐才好办事。
-
商业目标确定之后,需要确定容器相关的技术选型,容器是一种轻量化的虚拟化技术,与传统虚拟机比较有优点也有缺点,要找出这些差异点识别出对基础设施与应用的影响,提前识别风险并采取应对措施。
-
技术选型明确之后,在公司或部门内部推广与评审,让开发人员、架构师、测试人员、运维人员相关人员与团队理解与认同方案,听取他们意见,他们是直接使用容器的客户,不要让他们有抱怨。
-
最后是落地策略,一般是选取一些辅助业务先试点,在实践过程中不断总结经验。
商业目标
容器技术是以应用为中心的轻量级虚拟化技术,而传统的Xen与KVM是以资源为中心的虚拟化技术,这是两者的本质差异。以应用为中心是容器技术演进的指导原则,正是在这个原则指导下,容器技术相对于传统虚拟化有几个特点:打包既部署、镜像分层、应用资源调度。
- 打包即部署:打包即部署是指在容器镜像制作过程包含了传统软件包部署的过程(安装依赖的操作系统库或工具、创建用户、创建运行目录、解压、设置文件权限等等),这么做的好处是把应用及其依赖封装到了一个相对封闭的环境,减少了应用对外部环境的依赖,增强了应用在各种不同环境下的行为一致性,同时也减少了应用部署时间。
- 镜像分层:容器镜像包是分层结构,同一个主机上的镜像层是可以在多个容器之间共享的,这个机制可以极大减少镜像更新时候拉取镜像包的时间,通常应用程序更新升级都只是更新业务层(如Java程序的jar包),而镜像中的操作系统Lib层、运行时(如Jre)层等文件不会频繁更新。因此新版本镜像实质有变化的只有很小的一部分,在更新升级时候也只会从镜像仓库拉取很小的文件,所以速度很快。
- 应用资源调度:资源(计算/存储/网络)都是以应用为中心的,中心体现在资源分配是按照应用粒度分配资源、资源随应用迁移。
基于上述容器技术特点,可以推导出容器技术的3大使用场景:CI/CD、提升资源利用率、弹性伸缩。这3个使用场景自然推导出通用的商业层面收益:CI/CD提升研发效率、提升资源利用率降低成本、按需弹性伸缩在体验与成本之间达成平衡。
当然,除了商业目标之外,可能还有其他一些考虑因素,如基于容器技术实现计算任务调度平台、保持团队技术先进性等。
CI/CD提升研发效率
为什么容器技术适合CI/CD
CI/CD是DevOps的关键组成部分,DevOps是一套软件工程的流程,用于持续提升软件开发效率与软件交付质量。DevOps流程来源于制造业的精益生产理念,在这个领域的领头羊是丰田公司,《丰田套路》这本书总结丰田公司如何通过PDCA(Plan-Do-Check-Act)方法实施持续改进。PDCA通常也称为PDCA循环,PDCA实施过程简要描述为:确定目标状态、分析当前状态、找出与目标状态的差距、制定实施计划、实施并总结、开始下一个PDCA过程。
DevOps基本也是这么一个PDCA流程循环,很容易认知到PDCA过程中效率是关键,同一时间段内,实施更多数量的PDCA过程,收益越高。在软件开发领域的DevOps流程中,各种等待(等待编译、等待打包、等待部署等)、各种中断(部署失败、机器故障)是影响DevOps流程效率的重要因素。
容器技术出来之后,将容器技术应用到DevOps场景下,可以从技术手段消除DevOps流程中的部分等待与中断,从而大幅度提升DevOps流程中CI/CD的效率。
容器的OCI标准定义了容器镜像规范,容器镜像包与传统的压缩包(zip/tgz等)相比有两个关键区别点:1)分层存储;2)打包即部署。
分层存储可以极大减少镜像更新时候拉取镜像包的时间,通常应用程序更新升级都只是更新业务层(如Java程序的jar包),而镜像中的操作系统Lib层、运行时(如Jre)层等文件不会频繁更新。因此新版本镜像实质有变化的只有很小的一部分,在更新升级时候也只会从镜像仓库拉取很小的文件,所以速度很快。
打包即部署是指在容器镜像制作过程包含了传统软件包部署的过程(安装依赖的操作系统库或工具、创建用户、创建运行目录、解压、设置文件权限等等),这么做的好处是把应用及其依赖封装到了一个相对封闭的环境,减少了应用对外部环境的依赖,增强了应用在各种不同环境下的行为一致性,同时也减少了应用部署时间。
基于容器镜像的这些优势,容器镜像用到CI/CD场景下,可以减少CI/CD过程中的等待时间,减少因环境差异而导致的部署中断,从而提升CI/CD的效率,提升整体研发效率。
CI/CD的关键诉求与挑战
- 快
开发人员本地开发调试完成后,提交代码,执行构建与部署,等待部署完成后验证功能。这个等待的过程尽可能短,否则开发人员工作容易被打断,造成后果就是效率降低。如果提交代码后几秒钟就能够完成部署,那么开发人员几乎不用等待,工作也不会被打断;如果需要好几分钟或十几分钟,那么可以想象,这十几分钟就是浪费了,这时候很容易做点别的事情,那么思路又被打断了。
所以构建CI/CD环境时候,快是第一个需要考虑的因素。要达到快,除了有足够的机器资源免除排队等待,引入并行编译技术也是常用做法,如Maven3支持多核并行构建。
- 自定义流程
不同行业存在不同的行业规范、监管要求,各个企业有一套内部质量规范,这些要求都对软件交付流程有定制需求,如要求使用商用的代码扫描工具做安全扫描,如构建结果与企业内部通信系统对接发送消息。
在团队协同方面,不同的公司,对DevOps流程在不同团队之间分工有差异,典型的有开发者负责代码编写构建出构建物(如jar包),而部署模板、配置由运维人员负责;有的企业开发人员负责构建并部署到测试环境;有的企业开发人员直接可以部署到生产环境。这些不同的场景,对CI/CD的流程、权限管控都有定制需求。
提升资源利用率
OCI标准包含容器镜像标准与容器运行时标准两部分,容器运行时标准聚焦在定义如何将镜像包从镜像仓库拉取到本地并更新、如何隔离运行时资源这些方面。得益于分层存储与打包即部署的特性,容器镜像从到镜像仓库拉取到本地运行速度非常快(通常小于30秒,依赖镜像本身大小等因素),基于此可以实现按需分配容器运行时资源(cpu与内存),并限定单个容器资源用量;然后根据容器进程资源使用率设定弹性伸缩规则,实现自动的弹性伸缩。
这种方式相对于传统的按峰值配置资源方式,可以提升资源利用率。
按需弹性伸缩在体验与成本之间达成平衡
联动弹性伸缩
应用运行到容器,按需分配资源之后,理想情况下,Kubernetes的池子里没有空闲的资源。这时候扩容应用实例数,新扩容的实例会因资源不足调度失败。这时候需要资源池能自动扩容,加入新的虚拟机,调度新扩容的应用。
由于应用对资源的配比与Flavor有要求,因此新加入的虚拟机,应当是与应用所需要的资源配比与Flavor一致的。缩容也是类似。
弹性伸缩还有一个诉求点是“平滑”,对业务做到不感知,也称为“优雅”扩容/缩容。
请求风暴
上面提到的弹性伸缩一般是有计划或缓慢增压的场景,存在另外一种无法预期的请求风暴场景,这种场景的特征是无法预测、突然请求量增大数倍或数十倍、持续时间短。典型的例子如行情交易系统,当行情突变的时候,用户访问量徒增,持续几十分钟或一个小时。
这种场景的弹性诉求,要求短时间内能将资源池扩大数倍,关键是速度要快(秒级),否则会来不及扩容,系统已经被冲垮(如果无限流的话)。
目前基于 Virtual Kubelet 与云厂家的 Serverless 容器,理论上可以提供应对请求风暴的方案。不过在具体实施时候,需要考虑传统托管式Kubernetes容器管理平台与Serverless容器之间互通的问题,需要基于具体厂家提供的能力来评估。
基于容器技术实现计算调度平台
计算(大数据/AI训练等)场景的特征是短时间内需要大量算力,算完即释放。容器的环境一致性以及调度便利性适合这种场景。
技术选型
容器技术是属于基础设施范围,但是与传统虚拟化技术(Xen/KVM)比较,容器技术是应用虚拟化,不是纯粹的资源虚拟化,与传统虚拟化存在差异。在容器技术选型时候,需要结合当前团队在应用管理与资源管理的现状,对照容器技术与虚拟化技术的差异,选择最合适的容器技术栈。
什么是容器技术
(1)容器是一种轻量化的应用虚拟化技术。
在讨论具体的容器技术栈的时候,先介绍目前几种常用的应用虚拟化技术,当前有3种主流的应用虚拟化技术: LXC,MicroVM,UniKernel(LibOS)。
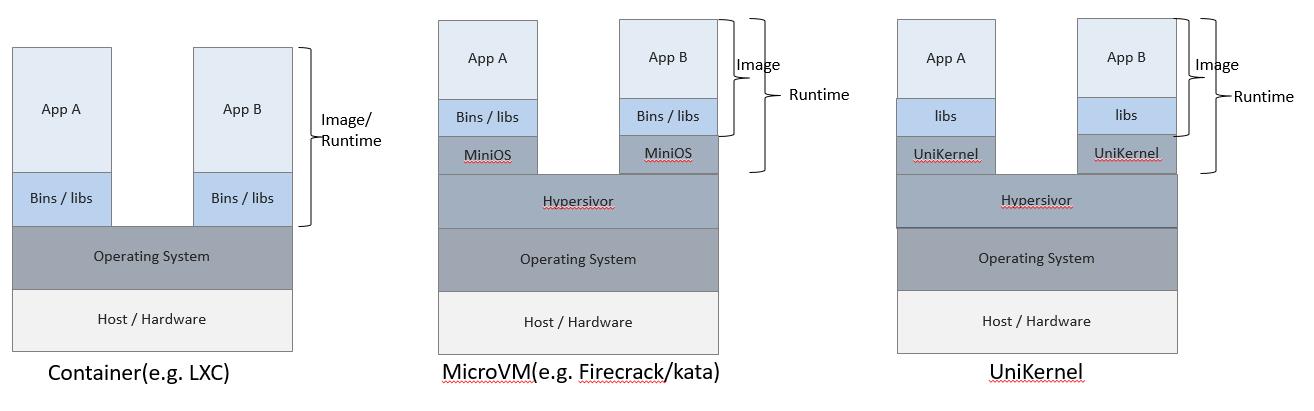
- LXC: Linux Container,通过 Linux的 namespace/cgroups/chroot 等技术隔离进程资源,目前应用最广的docker就是基于LXC实现应用虚拟化的。
- MicroVM: MicroVM 介于 传统的VM 与 LXC之间,隔离性比LXC好,但是比传统的VM要轻量,轻量体现在体积小(几M到几十M)、启动快(小于1s)。 AWS Firecracker 就是一种MicroVM的实现,用于AWS的Serverless计算领域,Serverless要求启动快,租户之间隔离性好。
- UniKernel: 是一种专用的(特定编程语言技术栈专用)、单地址空间、使用 library OS 构建出来的镜像。UniKernel要解决的问题是减少应用软件的技术栈层次,现代软件层次太多导致越来越臃肿:硬件+HostOS+虚拟化模拟+GuestOS+APP。UniKernel目标是:硬件+HostOS+虚拟化模拟+APP-with-libos。
三种技术对比表:
| 开销 | 体积 | 启动速度 | 隔离/安全 | 生态 | |
|---|---|---|---|---|---|
| LXC | 低(几乎为0) | 小 | 快(等同进程启动) | 差(内核共享) | 好 |
| MicroVM | 高 | 大 | 慢(小于1s) | 好 | 中(Kata项目) |
| UniKernel | 中 | 中 | 中 | 好 | 差 |
根据上述对比来看,LXC是应用虚拟化首选的技术,如果LXC无法满足隔离性要,则可以考虑MicroVM这种技术。当前社区已经在着手融合LXC与MicroVM这两种技术,从应用打包/发布调度/运行层面统一规范,Kubernetes集成Kata支持混合应用调度特性可以了解一下。
UniKernel 在应用生态方面相对比较落后,目前在追赶中,目前通过 linuxkit 工具可以在UniKernel应用镜像中使用docker镜像。这种方式笔者还未验证过,另外docker镜像运行起来之后,如何监控目前还未知。
从上述三种应用虚拟化技术对比,可以得出结论: (2)容器技术与传统虚拟化技术不断融合中。
再从规范视角来看容器技术,可以将容器技术定义为: (3)容器=OCI+CRI+辅助工具。
OCI规范包含两部分,镜像规范与运行时规范。简要的说,要实现一个OCI的规范,需要能够下载镜像并解压镜像到文件系统上组成成一个文件目录结构,运行时工具能够理解这个目录结构并基于此目录结构管理(创建/启动/停止/删除)进程。
容器(container)的技术构成就是实现OCI规范的技术集合。
对于不同的操作系统(Linux/Windows),OCI规范的实现技术不同,当前docker的实现,支持Windows与Linux与MacOS操作系统。当前使用最广的是Linux系统,OCI的实现,在Linux上组成容器的主要技术:
- chroot: 通过分层文件系统堆叠出容器进程的rootfs,然后通过
chroot设置容器进程的根文件系统为堆叠出的rootfs。 - cgroups: 通过cgroups技术隔离容器进程的cpu/内存资源。
- namesapce: 通过
pid,uts,mount,network,usernamesapce 分别隔离容器进程的进程ID,时间,文件系统挂载,网络,用户资源。 - 网络虚拟化: 容器进程被放置到独立的网络命名空间,通过Linux网络虚拟化
veth,macvlan,bridge等技术连接主机网络与容器虚拟网络。 - 存储驱动: 本地文件系统,使用容器镜像分层文件堆叠的各种实现驱动,当前推荐的是
overlay2。
广义的容器还包含容器编排,即当下很火热的Kubernetes。Kubernetes为了把控容器调度的生态,发布了CRI规范,通过CRI规范解耦Kubelet与容器,只要实现了CRI接口,都可以与Kubelet交互,从而被Kubernetes调度。OCI规范的容器实现与CRI标准接口对接的实现是CRI-O。
辅助工具用户构建镜像,验证镜像签名,管理存储卷等。
容器定义
- 容器是一种轻量化的应用虚拟化技术。
- 容器=OCI+CRI+辅助工具。
- 容器技术与传统虚拟化技术不断融合中。
什么是容器编排与调度
选择了应用虚拟化技术之后,还需要应用调度编排,当前Kubernetes是容器领域内编排的事实标准,不管使用何种应用虚拟化技术,都已经纳入到了Kubernetes治理框架中。
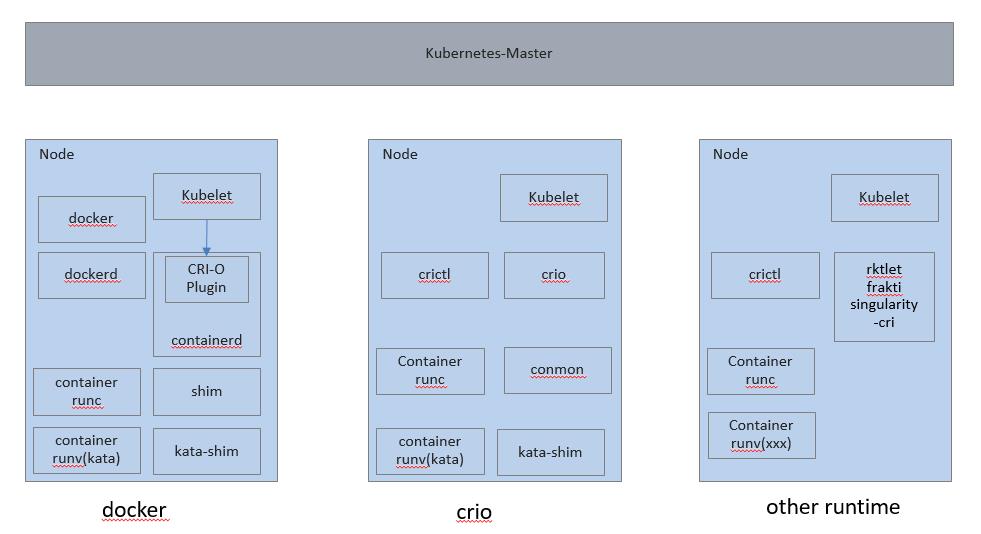
Kubernetes 通过 CRI 接口规范,将应用编排与应用虚拟化实现解耦:不管使用何种应用虚拟化技术(LXC, MicroVM, LibOS),都能够通过Kubernetes统一编排。
当前使用最多的是docker,其次是cri-o。docker与crio结合kata-runtime都能够支持多种应用虚拟化技术混合编排的场景,如LXC与MicroVM混合编排。
-
docker(now): Moby 公司贡献的 docker 相关部件,当前主流使用的模式。
- docker(daemon) 提供对外访问的API与CLI(docker client)
- containerd 提供与 kubelet 对接的 CRI 接口实现
- shim负责将Pod桥接到Host namespace。
-
cri-o: 由 RedHat/Intel/SUSE/IBM/Hyper 公司贡献的实现了CRI接口的符合OCI规范的运行时,当前包括
runc与kata-runtime,也就是说使用cir-o可以同时运行LXC容器与MicroVM容器,具体在Kata介绍中有详细说明。- CRI-O: 实现了CRI接口的进程,与 kubelet 交互
- crictl: 类似 docker 的命令行工具
- conmon: Pod监控进程
-
other cri runtimes: 其他的一些cri实现,目前没有大规模应用到生产环境。
容器与传统虚拟化差异
容器(container)的技术构成
前面主要讲到的是容器与编排,包括CRI接口的各种实现,我们把容器领域的规范归纳为南向与北向两部分,CRI属于北向接口规范,对接编排系统,OCI就属于南向接口规范,实现应用虚拟化。
简单来讲,可以这么定义容器:
容器(container) ~= 应用打包(build) + 应用分发(ship) + 应用运行/资源隔离(run)。
build-ship-run 的内容都被定义到了OCI规范中,因此也可以这么定义容器:
容器(container) == OCI规范
OCI规范包含两部分,镜像规范与运行时规范。简要的说,要实现一个OCI的规范,需要能够下载镜像并解压镜像到文件系统上组成成一个文件目录结构,运行时工具能够理解这个目录结构并基于此目录结构管理(创建/启动/停止/删除)进程。
容器(container)的技术构成就是实现OCI规范的技术集合。
对于不同的操作系统(Linux/Windows),OCI规范的实现技术不同,当前docker的实现,支持Windows与Linux与MacOS操作系统。当前使用最广的是Linux系统,OCI的实现,在Linux上组成容器的主要技术:
- chroot: 通过分层文件系统堆叠出容器进程的rootfs,然后通过
chroot设置容器进程的根文件系统为堆叠出的rootfs。 - cgroups: 通过cgroups技术隔离容器进程的cpu/内存资源。
- namesapce: 通过
pid,uts,mount,network,usernamesapce 分别隔离容器进程的进程ID,时间,文件系统挂载,网络,用户资源。 - 网络虚拟化: 容器进程被放置到独立的网络命名空间,通过Linux网络虚拟化
veth,macvlan,bridge等技术连接主机网络与容器虚拟网络。 - 存储驱动: 本地文件系统,使用容器镜像分层文件堆叠的各种实现驱动,当前推荐的是
overlay2。
广义的容器还包含容器编排,即当下很火热的Kubernetes。Kubernetes为了把控容器调度的生态,发布了CRI规范,通过CRI规范解耦Kubelet与容器,只要实现了CRI接口,都可以与Kubelet交互,从而被Kubernetes调度。OCI规范的容器实现与CRI标准接口对接的实现是CRI-O。
容器与虚拟机差异对比
容器与虚拟机的差异可以总结为2点:应用打包与分发的差异,应用资源隔离的差异。当然,导致这两点差异的根基是容器是以应用为中心来设计的,而虚拟化是以资源为中心来设计的,本文对比容器与虚拟机的差异,更多的是站在应用视角来对比。
从3个方面对比差异:资源隔离,应用打包与分发,延伸的日志/监控/DFX差异。
1.资源隔离
- 隔离机制差异
| 容器 | 虚拟化 | |
|---|---|---|
| mem/cpu | cgroup, 使用时候设定 require 与 limit 值 |
QEMU, KVM |
| network | Linux网络虚拟化技术(veth,tap,bridge,macvlan,ipvlan), 跨虚拟机或出公网访问:SNAT/DNAT, service转发:iptables/ipvs, SR-IOV | Linux网络虚拟化技术(veth,tap,bridge,macvlan,ipvlan), QEMU, SR-IOV |
| storage | 本地存储: 容器存储驱动 | 本地存储:virtio-blk |
- 差异引入问题与实践建议
- 应用程序未适配
cgroup的内存隔离导致问题: 典型的是JVM虚拟机,在JVM启动时候会根据系统内存自动设置MaxHeapSize值,通常是系统内存的1/4,但是JVM并未考虑cgroup场景,读系统内存时候任然读取主机的内存来设置MaxHeapSize,这样会导致内存超过cgroup限制从而导致进程被kill。问题详细阐述与解决建议参考Java inside docker: What you must know to not FAIL。 - 多次网络虚拟化问题: 如果在虚拟机内使用容器,会多一层网络虚拟化,并加入了SNAT/DNAT技术, iptables/ipvs技术,对网络吞吐量与时延都有影响(具体依赖容器网络方案),对问题定位复杂度变高,同时还需要注意网络内核参数调优。
典型的网络调优参数有:
转发表大小 ```/proc/sys/net/netfilter/nf_conntrack_max```
使用iptables 作为service转发实现的时候,在转发规则较多的时候,iptables更新由于需要全量更新导致非常耗时,建议使用ipvs。详细参考[华为云在 K8S 大规模场景下的 Service 性能优化实践](https://zhuanlan.zhihu.com/p/37230013)。
-
容器IP地址频繁变化不固定,周边系统需要协调适配,包括基于IP地址的白名单或防火墙控制策略需要调整,CMDB记录的应用IP地址需要适配动态IP或者使用服务名替代IP地址。
-
存储驱动带来的性能损耗: 容器本地文件系统是通过联合文件系统方式堆叠出来的,当前主推与默认提供的是
overlay2驱动,这种模式应用写本地文件系统文件或修改已有文件,使用Copy-On-Write方式,也就是会先拷贝源文件到可写层然后修改,如果这种操作非常频繁,建议使用volume方式。
2.应用打包与分发
- 应用打包/分发/调度差异
| 容器 | 虚拟化 | |
|---|---|---|
| 打包 | 打包既部署 | 一般不会把应用程序与虚拟机打包在一起,通过部署系统部署应用 |
| 分发 | 使用镜像仓库存储与分发 | 使用文件存储 |
| 调度运行 | 使用K8S亲和/反亲和调度策略 | 使用部署系统的调度能力 |
- 差异引入问题与实践建议
- 部署提前到构建阶段,应用需要支持动态配置与静态程序分离;如果在传统部署脚本中依赖外部动态配置,这部分需要做一些调整。
- 打包格式发生变化,制作容器镜像需要注意安全/效率因素,可参考Dockerfile最佳实践
- 容器镜像存储与分发是按layer来组织的,镜像在传输过程中放篡改的方式是传统软件包有差异。
3.监控/日志/DFX
- 差异
| 容器 | 虚拟化 | |
|---|---|---|
| 监控 | cpu/mem的资源上限是cgroup定义的;containerd/shim/docker-daemon等进程的监控 | 传统进程监控 |
| 日志采集 | stdout/stderr日志采集方式变化;日志持久化需要挂载到volume;进程会被随机调度到其他节点导致日志需要实时采集否则分散很难定位 | 传统日志采集 |
| 问题定位 | 进程down之后自动拉起会导致问题定位现场丢失;无法停止进程来定位问题因为停止即删除实例 | 传统问题定位手段 |
- 差异引入问题实践与建议
- 使用成熟的监控工具,运行在docker中的应用使用cadvisor+prometheus实现采集与警报,cadvisor中预置了常用的监控指标项
- 对于docker管理进程(containerd/shim/docker-daemon)也需要一并监控
- 使用成熟的日志采集工具,如果已有日志采集Agent,则可以考虑将日志文件挂载到volume后由Agent采集;需要注意的是stderr/stdout输出也要一并采集
- 如果希望容器内应用进程退出后保留现场定位问题,则可以将
Pod的restartPolicy设置为never,进程退出后进程文件都还保留着(/var/lib/docker/containers)。但是这么做的话需要进程没有及时恢复,会影响业务,需要自己实现进程重拉起。
团队配合
与周边的开发团队、架构团队、测试团队、运维团队评审并交流方案,与周边团队达成一致。
落地策略与注意事项
逐步演进过程中网络互通
根据当前已经存在的基础实施情况,选择容器化落地策略。通常使用逐步演进的方式,由于容器化引入了独立的网络namespace导致容器与传统虚拟机进程网络隔离,逐步演进过程中如何打通隔离的网络是最大的挑战。
分两种场景讨论:
- 不同服务集群之间使用VIP模式互通: 这种模式相对简单,基于VIP做灰度发布。
- 不同服务集群之间使用微服务点对点模式互通(SpringCloud/ServiceComb/Dubbo都是这一类): 这种模式相对复杂,在逐步容器化过程中,要求容器网络与传统虚拟机网络能够互通(难点是在虚拟机进程内能够直接访问到容器网络的IP地址),当前解决这个问题有几种方法。
- 自建Kubernetes场景,可使用开源的kube-router,kube-router 使用BGP协议实现容器网络与传统虚拟机网络之间互通,要求网络交换机支持BGP协议。
- 使用云厂商托管Kubernetes场景,选择云厂商提供的VPC-Router互通的网络插件,如阿里云的Terway网络插件, 华为云的Underlay网络模式。
选择物理机还是虚拟机
选择物理机运行容器还是虚拟机运行容器,需要结合基础设施与业务隔离性要求综合考虑。分两种场景:自建IDC、租用公有云。
- 自建IDC: 理想情况是使用物理机组成一个大集群,根据业务诉求,对资源保障与安全性要求高的应用,使用MicorVM方式隔离;普通应用使用LXC方式隔离。所有物理机在一个大集群内,方便削峰填谷提升资源利用率。
- 租用公有云:当前公有云厂家提供的裸金属服务价格较贵且只能包周期,使用裸金属性价比并不高,使用虚拟机更合适。
集群规模与划分
选择集群时候,是多个应用共用一个大集群,还是按应用分组分成多个小集群呢?我们把节点规模数量>=1000的定义为大集群,节点数<1000的定义为小集群。
-
大集群的优点是资源池共享容器,方便资源调度(削峰填谷);缺点是随着节点数量与负载数量的增多,会引入管理性能问题(需要量化):
- DNS 解析表变大,增加/删除 Service 或 增加/删除 Endpoint 导致DNS表刷新慢
- K8S Service 转发表变大,导致工作负载增加/删除刷新iptables/ipvs记录变慢
- etcd 存储空间变大,如果加上ConfigMap,可能导致 etcd 访问时延增加
-
小集群的优点是不会有管理性能问题,缺点是会导致资源碎片化,不容易共享。共享分两种情况:
- 应用之间削峰填谷:目前无法实现
- 计算任务与应用之间削峰填谷:由于计算任务是短时任务,可以通过上层的任务调度软件,在多个集群之间分发计算任务,从而达到集群之间资源共享的目的。
选择集群规模的时候,可以参考上述分析,结合实际情况选择适合的集群划分。
Helm?
Helm是为了解决K8S管理对象散碎的问题,在K8S中并没有"应用"的概念,只有一个个散的对象(Deployment, ConfigMap, Service, etc),而一个"应用"是多个对象组合起来的,且这些对象之间还可能存在一定的版本配套关系。
Helm 通过将K8S多个对象打包为一个包并标注版本号形成一个"应用",通过 Helm 管理进程部署/升级这个"应用"。这种方式解决了一些问题(应用分发更方便)同时也引入了一些问题(引入Helm增加应用发布/管理复杂度、在K8S修改了对象后如何同步到Helm)。对于是否需要使用Helm,建议如下:
- 在自运维模式下不使用Helm: 自运维模式下,很多场景是开发团队交付一个运行包,运维团队负责部署与配置下发,内部通过兼容性或软件包与配置版本配套清单、管理软件包与配置的配套关系。
- 在交付软件包模式下使用Helm: 交付软件包模式下,Helm 这种把散碎组件组装为一个应用的模式比较适合,使用Helm实现软件包分发/部署/升级场比较简单。
Reference
DOCKER vs LXC vs VIRTUAL MACHINES
Introducing Container Runtime Interface (CRI) in Kubernetes
Java inside docker: What you must know to not FAIL
KVM 介绍(4):I/O 设备直接分配和 SR-IOV [KVM PCI/PCIe Pass-Through SR-IOV]
The Rise and Fall of the Operating System
The Design and Implementation of the Anykernel and Rump Kernels
更多云最佳实践 https://best.practices.cloud/
以上是关于容器实践线路图的主要内容,如果未能解决你的问题,请参考以下文章