软考-后篇
Posted 2月2日
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了软考-后篇相关的知识,希望对你有一定的参考价值。
数据库
三级模式-两级映射
概念级数据库:E-R图
物理级数据库:mysql数据库等
数据库设计过程
E-R模型
矩形 : 实体 如:学生 课程 老师
椭圆 : 属性 如:学号 姓名 年龄
菱形 : 联系 如:选课
E-R转关系模式
1-1: 可以转换成两个关系模式(联系归属到实体A或者B中),或者三个关系模式
1-n: 可以转换成两个关系模式(联系归属到实体B中),或者三个关系模式
m-n:转换成实体数+联系数个关系模式,如图中为4个
关系代数
对关系中的记录进行运算,一般以选择题的形式出现
- 并 : 两个关系中出现的所有记录
- 交 : 共同拥有的记录
- 差 : 被减数所独有的记录
- 笛卡尔积 : 关系1中的每条记录与关系2中的记录进行组合,一共得到关系1*关系2条记录
- 投影 : 选择列 ΠSname,Sdept 就是选择了这两列数据
- 选择 : 选择行 σNo0001 选择了这一行,也可以直接写数字选择对应行
- 连接 : 连接两个表
函数依赖
由X可以确定唯一的Y,这称之为X决定Y,或者Y函数依赖于X
在数据库中,学号决定姓名,姓名函数依赖于学号,因为学号是唯一的,而姓名可能重名
部份依赖
设置学号和课程号为主键,然后查找姓名,而通过学号已经可以查找到学生姓名,此时则称为部分依赖
传递依赖
此时B不能确定A,才能传递函数依赖
非规范化的错误
- 数据冗余 : 如表中有一个字段为专业编码,一个字段为专业名称,专业名称与专业编码意义相同
- 更新异常 : 更改一个字段中所有的信息系,如果漏到一两个没改,则会发生更新异常
键
唯一标识元组 : 超键 候选键
超键与候选键区别在于 : 候选键消除了多余属性
如(学号,姓名)->姓别,(学号,姓名)可以称为超键,学号可以称为候选键,因为有没有姓名都可以通过学号获取性别
主键 : 将一个表中的某个字段设置为主键,有且只有一个
外键 : 其他关系中的主键,便于关联查询
求候选键
入度即为箭头指向本身的数量
如果没有入度为0,则寻找中间结点,有入度也有出度的键
范式
主属性 : 候选键中的属性
三个都是候选键
第一范式 : 属性值都是不可分的原子值
高级职称人数还可细分成教授和副教授,此时去掉高级职称人数,即可达到第一范式
第二范式 : 不存在部分函数依赖
联合主键为(SNO,CNO),通过CNO(课程编码)可以查到CREDIT(学分),存在部分依赖,不满足第二范式
导致的问题 : 当没有学生选择这门课程时,因为学号为0,无法填入学分数据,当想删除部分毕业学生时,出现学分数据也被删除的情况,这是不必要的
修改方式 : 添加一个新的表字段为CNO,CREDIT,然后将CREDIT从原来的表中删去
第三范式 : 将外键取出到关系表,消除传递依赖
由DNO可以查到DNAME和LOCATION,存在传递依赖
修改方式 : 新建一个关系表 DNO DNAME和LOCATION,将原表的DNAME和LOCATION删去
BC范式
所有的函数依赖中,左边部分为候选键
模式分解
保留函数依赖分解
如R(A,B,C) A->B B->C 如果分解成R1(A,B) R2(B,C),保留了所有依赖
如果分解成R1(A,B) R3(A,C),则没有全部保留,反而多了R3这个冗余依赖
无损分解
判断依据 : 是否能还原
无算联接分解 : 通过自然联接和投影等可以还原
列表法
公式法
并发控制-添加封锁协议
完整性约束
- 实体完整性约束 : 主键不能为空
- 参照完整性约束 : 填入数据需要参照主键,会有错误提示,允许为空
- 用户自定义完整性 : 根据用户需求自定义完整约束
触发器
复杂的约束通过编写触发器来解决
数据库安全
数据备份
数据库故障
数据仓库与数据挖掘
数据仓库 : 从数据源(数据库,日志等等)中抽取出某个主题(如:每月流水),然后进行存储分析
数据集市 : 部门级的数据仓库
OLAP服务器 : 联机分析处理器
反规范化
大数据
对海量数据进行处理的技术
数据要求 : 数据量极大 速度快 多样性 具有价值
计算机网络
OSI/RM七层模型
注意点 : 广播只能在局域网中传递,而局域网一般是1.2层
网络技术标准与协议
TCP 三次握手
DHCP协议
动态分配IP地址
DNS协议
域名解析协议
答案选A ,根域名服务器在接受讯问后,直接返回结果,中介域名服务器被询问后去授权域名服务器中查询
计算机网络分类
按分布范围分 : 局域网 城域网 广域网 因特网
按拓扑结构分 : 总线型 星形 环形
办公室一般使用星形,中心节点为交换机
网络规划与设计
分层设计
子网划分
子网掩码 : 将ip地址转化成2进制,如果是B类地址,则前面两个字节(16位,2B)置为1,然后划分多少个子网则将对应位数置为1,如27个子网(32>27),所以将网络号后5位置为1,再转化成十进制,即为子网掩码
C类子网一共有24个网络号,现在将20位作为主机号,所以将4位拿出来划分,2的4次方为16
特殊含义的IP地址
网络接入技术
信息安全
信息系统安全属性
对称加密技术
加密解密密钥相同
如压缩包加密
非对称加密技术
公钥加密私钥解密 或者 私钥加密公钥解密
缺陷 : 加密速度慢
信息摘要
一段信息的特征信息
单向散列函数(单向hash函数),固定长度的散列值
信息可以得出摘要,摘要不能还原成信息
数字签名
如AB传递数据,此时A的数字签名应当用A的私钥加密,因为使用A的公钥可以解密,证明是A发出来的
数字签名没有保密职能,公钥谁都有
对摘要进行数字签名
数字信封与PGP
PGP
练习题
网络安全
防火墙
网络攻击
数据结构与算法
数组
数组偏移量计算
一维 : n-m
三维 : a mnk aijo 偏移量 iXnk+jXk+o
稀疏数组
第一行
m n k 代表行 列 个数
h i j a[h] [i]位置的数维 j
数据结构
线性表
顺序表
连续的存储空间
链表
指针与数据,指针存放存储空间地址,上图为循环列表
线性存储与链式存储的性能对比
队列(FIFO)
栈(FILO)
双端队列
数据可从两端输入,但只有一端输出
广义表
长度 : 元素的个数(子表当成元素计算)
深度 : 括号层数
head操作 : 第一个表元素
tail操作 : 除了第一个表元素以外的所有表元素
树
结点的度
结点所拥有的子结点数量
树的度
结点度数最高的数
叶子节点
没有子结点的结点
层次
树的层数
二叉树
完全二叉树 : 从左边开始计算,左子节点排满
二叉树遍历
前序遍历(根左右)
中序遍历(左根右)
后续遍历(左右根)
树与二叉树转换
查找二叉树
左结点都比根节点小,右结点都比根结点大
最优二叉树(哈夫曼树)
树的路径长度 : 连接结点的线段数
权 : 末尾结点的值
带权路径长度 : 权乘以路径长度
树的代价 : 所有带权路径之和
**构建哈夫曼树 **: 不断取权值最小的两个值进行构建子树
线索二叉树
将叶子结点的左节点指向前驱结点,右结点指向后继结点
平衡二叉树
任何结点的左右子树深度为0,1,-1 左结点减右结点(有值为1,为0)
图
无向图 有向图
完全图
图的存储-邻接矩阵
图的存储-邻接表
拓扑排序
最小生成树
普里姆算法 : 选取一个初始结点,设为红点集,找到距离最短的蓝点集的结点,将其纳入红点集
克鲁斯凯尔算法 : 按顺序依次选择最小的线段(可选择多段),不形成环路即可
算法
时间复杂度
散列表
HASH
排序
直接插入排序
在已经排好序的数组中,插入新的数,速度较慢
希尔排序
原理 : 当直接插入排序的数较少时,速度较快
直接选择排序
堆排序
冒泡排序
快速排序
选择一个基准,将比基准小的值放在前面,比基准大的值放在后面,再对分类号的两部分值进行快速排序,重复此步骤可以获得排序好的数组
基数排序
根据个位十位百位千位的依次进行多次排序 ,如123,146 中123的个位为3,所以放在新数组的第三个,146放在第6个,全部排好后,进行收集(去掉空格)
编译原理
表达式
构建树,然后根据遍历方式不同,获得不同的表达式
函数调用
程序语言的计算
法律法规
标准分类
多媒体基础
媒体种类
计算问题
数据压缩
软件工程
瀑布模型(SDLG)
适用场景 :需求明确,二次开发,结构化模型代表
螺旋模型
特征:由多个模型组合而成
适用场景:风险驱动模型
V模型
特征:提前编写文档,提前写验收测试文档,测试贯穿始终
使用场景:
喷泉模型
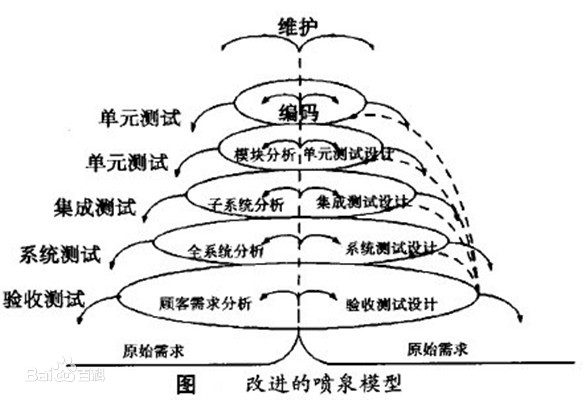
特点:第一个面向对象的模型
RAD
特点:快速构建系统
构建组装模型
特点:将软件开发过程中的各个功能,做成构件,存在构件库
优点:提高复用性,可靠性增加
敏捷开发方法
信息系统开发方法
结构化方法使用越来越少,因为流程固定且不灵活
结构化设计
内聚耦合
高内聚,低耦合
软件测试
设计测试用例
黑盒测试
不需要清楚程序模块内部结构,仅对接口进行测试
- 边界值:略小于区间,略大于区间,左右端点,如0-150,边界值为-1,0,150,151
- 等价类划分:每个可能性取一个值进行测试
- 错误推测:根据经验对可能发生错误的地方进行测试
- 因果图:
白盒测试
通过程序内部结构来设计测试用例
- 语句覆盖:设计测试用例将所有语句执行一次(但会出现部分路径未测试到)
- 判定覆盖:所有的判定(真假分支)进行覆盖测试
- 条件覆盖:对每个条件的分支进行测试
- 路径覆盖:最高级别测试,覆盖所有路径
测试阶段
MaCabe复杂度
V(G)= m - n + 2
m:有向弧
n:节点数
系统的运行与维护
可维护性
- 易(可)分析性:代码理解比较容易 代码维护
- 易(可)改变性:代码修改难度应该较低
- 稳定性
- 易(可)测试性:修改后应该容易测试
维护类型
- 改正性维护:修改bug
- 适应性维护:如操作系统升级,然后软件运行出现问题,进行修改,或者适应数据
- 完善性维护:在系统运行过程中,想要扩充功能和,改善性能
- 预防性维护:现在不进行维护,可能将来会出现问题
软件过程改进-CMMI
CMM:软件成熟度模型
CMMI:从CMM继承改进而来
等级划分
一级:所有没有通过CMMI的软件
系统开发基础
项目管理
时间管理
Gantt
不能清晰地描述任务间的依赖关系
- 最短工期:最长的路径
风险管理
损失和伤害的可能性
- 风险曝光率 : 风险出现可能性概率*损失
面向对象(OOA)
设计原则
UML
部署图:软件部署在硬件的哪个结点关系
用例图:小人操作
设计模式
分类
创建型模式
- 抽象工厂模式:提供一个接口,可以创建一系列相关或者相互依赖的对象,无需指定对应的类
- 构建器模式:如构建一个复杂的类,需要多个不同对象,可以将对象封装起来,再根据不同对象的需求创建对应的实例
- 工厂方法模式:定义一个创建对象的接口,可以在运行的时候再由子类选择想要实例化的对象,延迟了子类实例化的过程
- 原型模式:克隆模型,通过拷贝原型创建新的对象,可以提高效率,节约资源
- 单例模式:保证一个类只有一个实例,如浏览器打开多个网页,但主窗口只有一个
结构型模式
-
适配器模式:将一个类的接口转换成用户希望得到的接口,使不相容的接口可以协同工作 转换接口
-
桥接模式:有时候一个功能的实现其继承树深度非常高,这个时候可以将其抽象与实现分离开,形成两个继承树,提高效率
-
组合模式:将对象组合成树型结构,以此表示“部分-整体”的层次结构,特点为“树型目录结构”
-
装饰模式:动态地为一个对象添加一些额外的职责,如咖啡中加糖加奶加冰等,一层层叠加
-
外观模式:定义一个高层接口,将子系统中的一系列接口进行一个统一的处理操作,让操作变简单
-
享元模式:提供大量的对象共享的方法
-
代理模式:为其他对象提供一种代理以控制对象的访问
行为型模式
- 职责链模式:单个请求者,多个处理者,将接收者串联成一条链,以此判断是否能处理,能处理就返回给发送者消息,如财务管理中,500元部门经理可以批准,不必传到ceo
- 命令模式:将请求封装成对象,记录请求日志,支持撤销操作
- 解释器模式:定义一种语言的文法表示,从而定义一个解释器,依靠解释器来解释语言中的句子
- 迭代器模式:提供一种方法顺序访问一个聚合对象中的各个元素,不需要暴露内部结构,类似集合
- 中介者模式:用一个中间对象来封装对象间的交互,降低耦合
- 备忘录模式:捕获对象中的内部状态并保存,从而可以在后续进行恢复
- 观察者模式:定义对象中的以一种一对多关系,当一个对象的状态发生改变时,所有依赖与它的对象得到通知并自动更新,类似前端开发中改变数据,视图发生改变
- 状态模式:允许一个对象内部状态改变时改变其行为,如将不同等级的会员折扣写成不同的类,用户改变等级时,折扣力度发生变化,特点:状态变成类
- 策略模式:将算法封装起来,可以根据需求进行替换,活动方案替换改变灵活
- 模板方法模式:定义算法骨架,使得子类可以根据需求改变某些步骤
- 访问者模式:作用于对象中各个元素的操作,在不改变元素的前提下定义对于这些元素的一些新操作
数据流图(DFD)
基本概念
数据字典
数据流图平衡原则
父图与子图的平衡
顶层数据流图中的每个数据流都应该在子图中出现
子图内平衡
只有输入或者输出是不正确的
绘制错误
黑洞
奇迹
父子图不平衡
数据库设计
数据库设计过程
实体间的联系
1:1
1:n
m:n
E-R图向关系模型的转换
UML图
用例图
include:包含关系
extend:扩展关系
类图与对象图
顺序图
特点:按时间顺序执行
活动图
状态图
通信图
顺序图的另一种表达,但是时间没有强调得那么准确
数据结构问题
分治法
分治法常见用法:递归查找,二分查找
回溯法
贪心法
动态规划法
特点:查表
以上是关于软考-后篇的主要内容,如果未能解决你的问题,请参考以下文章
系统架构设计师软考简介 ( 软考好处 | 职称晋升 | 工作居住证 | 积分落户 | 系统架构设计师与系统分析师备考及难度 | 软考报名考试注意事项 )