Day18-Mysql基础
Posted 2月2日
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day18-Mysql基础相关的知识,希望对你有一定的参考价值。
mysql
什么是数据库
数据库 (DB ,DataBase)
概念:数据仓库,安装在操作系统之上的软件,可以存储大量的数据,超过500w时,需要做索引优 化
数据库分类
关系型数据库(SQL):采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理 解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。
- Oracle
- DB2
非关系型数据库(NoSQL):存储对象,通过对象属性决定
- NoSQL:Not Only SQL
DBMS(数据库管理系统):数据库的管理软件,科学有效地管理我们的数据
- Navicat
- SQLyog
- MySQL
DBMS常用操作
- 连接数据库
mysql -uroot -pcwt123456
- 修改密码
updata mysql.user set a authentiacation_string=password(\'123456\') where user = \'root\' and Host =\'localhost\';
- 数据库操作
show databases; //查看所有数据库
use xxx; //使用某个数据库
show tables; //查看数据库中所有的表
desc 表名 //显示表中的所有数据
ALTER TABLE 旧表名 RENAME AS 新表名 //修改表名
ALTER TABLE 表名 ADD 字段名 属性 //增加字段
ALTER TABLE 表名 MODIFY 字段名 新属性 //修改约束
ALTER TABLE 表名 CHANGR 新字段名 属性 //成绩排名给,重命名字段
ALTER TABLE 表名 DROP 字段名 //删除表的字段
DROP TABLE IF EXISTS 表名
- DDL 数据库定义语言
- DML 数据库操作语言
- DQL 数据库查询语言
- DCL 数据库控制语言
数据库列属性
Unsigned:无符号的整数,该列不能为负数
zerofill:不足的位数使用0来填充
自增:自动在上一条记录的基础上加一(默认),可以自定义设计主键的起始值和步长
特别的点:int(x)表示显示多少个字节,与存储大小无关
varchar(x),存储大小
INNODB和MYISAM的区别
- MYISAM 节约空间,速度较快
- INNODB 安全性高,支持事务处理,支持多表多用户操作
数据库外键
避免使用外键,一切外键概念必须在应用层解决
DML语言
添加
insert into 表名(字段1,字段2)values (值1,值2),(值1,值2)
修改
update 表名 set 字段名=’新属性‘ 条件
不指定条件下会修改所有字段名
删除
delete from 表名 条件
删除指定数据,如果不添加条件,将会清空整个数据库表
truncate 表名 清空一个数据库表
-
相同点:都能删除数据,都不删除表结构
-
不同点
-
truncate 重新设置 自增列 计数器归零(自增归零)
-
truncate 不会影响事务
-
8.0中都可以实现断电数据不丢失的效果
-
DQL查询数据
Data Query Language:数据查询语言
- 查询数据库数据 , 如SELECT语句
- 简单的单表查询或多表的复杂查询和嵌套查询
- 是数据库语言中最核心,最重要的语句
- 使用频率最高的语句
SELECT语法
SELECT [ALL | DISTINCT] //*号可以查询全部
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias] //as后面跟别名
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条
[ ] 括号代表可选的 , { }括号代表必选得
指定查询字段
-- 这里是为列取别名(当然as关键词可以省略)
SELECT studentno AS 学号,studentname AS 姓名 FROM student;
-- 使用as也可以为表取别名
SELECT studentno AS 学号,studentname AS 姓名 FROM student AS s;
-- 使用as,为查询结果取一个新名字
-- CONCAT()函数拼接字符串
SELECT CONCAT(\'姓名:\',studentname) AS 新姓名 FROM student;
去重
SELECT DISTINCT `classhour` AS \'课时\' FROM SUBJECT
列操作
- SELECT语句返回结果列中使用
- SELECT语句中的ORDER BY , HAVING等子句中使用
- DML语句中的 where 条件语句中使用表达式
-- selcet查询中可以使用表达式
SELECT @@auto_increment_increment; -- 查询自增步长
SELECT VERSION(); -- 查询版本号
SELECT 100*3-1 AS 计算结果; -- 表达式
-- 学员考试成绩集体提分一分查看
SELECT classhour+1 AS \'课时加1\' FROM SUBJECT;
where条件语句
用于检索数据表中符合条件的记录
搜索条件可由一个或者多个逻辑表达式组成
逻辑操作符号
| 操作符名称 | 作用 |
|---|---|
| AND 或 && | 全真为真,单假为假 |
| OR 或 || | 全假为假,单真为真 |
| NOT 或 ! |
测试
-- 满足条件的查询(where)
SELECT Studentno,StudentResult FROM result;
-- 查询考试成绩在95-100之间的
SELECT Studentno,StudentResult
FROM result
WHERE StudentResult>=95 AND StudentResult<=100;
-- AND也可以写成 &&
SELECT Studentno,StudentResult
FROM result
WHERE StudentResult>=95 && StudentResult<=100;
-- 模糊查询(对应的词:精确查询)
SELECT Studentno,StudentResult
FROM result
WHERE StudentResult BETWEEN 95 AND 100;
-- 除了1000号同学,要其他同学的成绩
SELECT studentno,studentresult
FROM result
WHERE studentno!=1000;
-- 使用NOT
SELECT studentno,studentresult
FROM result
WHERE NOT studentno=1000;
模糊查询
| 操作符名称 | 语法 | 作用 |
|---|---|---|
| IS NULL | a IS NULL | 返回满足的结果 |
| IS NOT NULL | a IS NOT NULL | 同上 |
| BETWEEN | a BETWEEN b AND | 同上 |
| LIKE | a LIKE b | 同上 |
| IN | a IN (a1,a2,a3) | a等于a1,a2,a3中的一个时,结果为真 |
-- 模糊查询 between and \\ like \\ in \\ null-- =============================================-- LIKE-- =============================================-- 查询姓刘的同学的学号及姓名-- like结合使用的通配符 : % (代表0到任意个字符) _ (一个字符)SELECT studentno,studentname FROM studentWHERE studentname LIKE \'刘%\';-- 查询姓刘的同学,后面只有一个字的SELECT studentno,studentname FROM studentWHERE studentname LIKE \'刘_\';-- 查询姓刘的同学,后面只有两个字的SELECT studentno,studentname FROM studentWHERE studentname LIKE \'刘__\';-- 查询姓名中含有 嘉 字的SELECT studentno,studentname FROM studentWHERE studentname LIKE \'%嘉%\';-- 查询姓名中含有特殊字符的需要使用转义符号 \'\\\'-- 自定义转义符关键字: ESCAPE \':\'-- =============================================-- IN-- =============================================-- 查询学号为1000,1001,1002的学生姓名SELECT studentno,studentname FROM studentWHERE studentno IN (1000,1001,1002);-- 查询地址在北京,南京,河南洛阳的学生SELECT studentno,studentname,address FROM studentWHERE address IN (\'北京\',\'南京\',\'河南洛阳\');-- =============================================-- NULL 空-- =============================================-- 查询出生日期没有填写的同学-- 不能直接写=NULL , 这是代表错误的 , 用 is nullSELECT studentname FROM studentWHERE BornDate IS NULL;-- 查询出生日期填写的同学SELECT studentname FROM studentWHERE BornDate IS NOT NULL;-- 查询没有写家庭住址的同学(空字符串不等于null)SELECT studentname FROM studentWHERE Address=\'\' OR Address IS NULL;
重点
-
%为0-n个字符
-
—为1个字符
例子
- 刘%,则为搜索数据库中刘开头的数据
- —中—,查询符合x中x的数据
连接查询
JOIN对比
| JOIN操作方式 | 用途 |
|---|---|
| INNER JOIN | 返回满足条件语句的数据(参考交集) |
| LEFT JOIN | 返回左表中满足条件的数据 |
| RIGHT JOIN | 返回右表中满足条件的数据 |
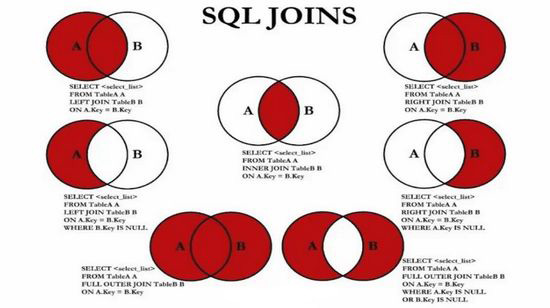
on与where
join (连接的表) on (判断的条件):连接查询
where:等值查询
/*连接查询 如需要多张数据表的数据进行查询,则可通过连接运算符实现多个查询内连接 inner join 查询两个表中的结果集中的交集外连接 outer join 左外连接 left join (以左表作为基准,右边表来一一匹配,匹配不上的,返回左表的记录,右表以NULL填充) 右外连接 right join (以右表作为基准,左边表来一一匹配,匹配不上的,返回右表的记录,左表以NULL填充) 等值连接和非等值连接自连接*/-- 查询参加了考试的同学信息(学号,学生姓名,科目编号,分数)SELECT * FROM student;SELECT * FROM result;/*思路:(1):分析需求,确定查询的列来源于两个类,student result,连接查询(2):确定使用哪种连接查询?(内连接)*/SELECT s.studentno,studentname,subjectno,StudentResultFROM student sINNER JOIN result rON r.studentno = s.studentno-- 右连接(也可实现)SELECT s.studentno,studentname,subjectno,StudentResultFROM student sRIGHT JOIN result rON r.studentno = s.studentno-- 等值连接SELECT s.studentno,studentname,subjectno,StudentResultFROM student s , result rWHERE r.studentno = s.studentno-- 左连接 (查询了所有同学,不考试的也会查出来)SELECT s.studentno,studentname,subjectno,StudentResultFROM student sLEFT JOIN result rON r.studentno = s.studentno-- 查一下缺考的同学(左连接应用场景)SELECT s.studentno,studentname,subjectno,StudentResultFROM student sLEFT JOIN result rON r.studentno = s.studentnoWHERE StudentResult IS NULL-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)SELECT s.studentno,studentname,subjectname,StudentResultFROM student sINNER JOIN result rON r.studentno = s.studentnoINNER JOIN `subject` subON sub.subjectno = r.subjectno
自连接
将一张表拆分成两张完全相同的表(一般是为了减少表的数量,将部分数据合并在一张表中),参考树型结构
CREATE TABLE `city` ( `pid` INT NOT NULL COMMENT \'父编码\', `cid` INT NOT NULL COMMENT \'子编码\', `cname` VARCHAR(50) NOT NULL COMMENT \'省份名称\') ENGINE=MYISAM DEFAULT CHARSET=utf8INSERT city (`pid`,`cid`,`cname`) VALUES(1,20,\'广东\'),(1,21,\'上海\'),(20,12,\'深圳\'),(21,19,\'黄埔\')SELECT R.cname AS \'省份\',S.cname AS\'城市\'FROM city R,city SWHERE R.cid=S.pid
分页和排序
排序
升序ASC,降序DESC
语法:ORDER BY 字段名 ASC(DESC)
根据字段来进行升序降序排列
SELECT * FROM SUBJECTORDER BY `gradeid` DESC
分页
作用:缓解数据库压力,美观,良好的用户体验
语法:LIMIT (n-1)*pageSize,pageSize
n:页码,pageSize:页面显示数据量
总页数:数据总数/pageSize
子查询和嵌套查询
- 在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句
- 嵌套查询可由多个子查询组成,求解的方式是由里及外;
- 子查询返回的结果一般都是集合,故而建议使用IN关键字;
MySQL函数
常用函数
- ABS(),求绝对值
- Ceiling(9.4),--10-- 向上取整
- FLOOR(9.4),--9-- 向下取整
- RAND,返回一个0-1的随机数
- sign(10),判断数的符号
字符串函数
-
CHAR_LENGTH(str),返回字符串长度
-
CONCAT(str1,str2,str3),拼接字符串
-
INSERT(str,插入位置,替换的字符数)
-
LOWER(str)转换为小写
-
UPPER(str)转换为大写
-
INSTR(str,s),返回s在str中第一次出现的索引,从1开始
-
REPLACE(str,str1,str2),将str中的str1替换成str2
-
SUBSTR(str,开始位置,结束位置),截取字符串
-
REVERSE(str),反转字符串
SELECT REPLACE(classhour,\'1\',\'90\') FROM SUBJECTWHERE classhour = 110
时间和日期函数
- current—date(),获取当前日期
- curdate(),获取当前日期
- now(),获取当前时间
- localtime(),本地时间
- sysdate(),系统时间
- year(now()),当前年份
系统
- system—user()
聚合函数(常用)
- count(列名) 计算列的行数,当该列为主键时,速度最快
- count(1),1w内count(1)快,超过1w与下面的没差别
- count(*)
- AVG(字段名) 计算平均值
- sum(字段名)计算总数
加密
使用MD5摘要算法进行数据加密
CREATE TABLE `testmd5` ( `id` INT(4) NOT NULL, `name` VARCHAR(20) NOT NULL, `pwd` VARCHAR(50) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=INNODB DEFAULT CHARSET=utf8
插入数据
INSERT INTO testmd5 VALUES(1,\'chenchenchen\',\'123456\'),(2,\'hahahha\',\'456789\')
加密密码列
update testmd5 set pwd = md5(pwd)
插入时加密
insert into testmd5 values(3,\'chenchen\',md5(\'123456\'))
事务
ACID原则
- 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 - 一致性(Consistency)
事务前后数据的完整性必须保持一致。 - 隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 - 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
事务的隔离级别
- 脏读:一个事务读取了另一个事务的未提交的数据
- 不可重复读:重复读取数据表中的某一行数据,多次读取结果不同
- 幻读:在一个事务内读取到别的事务插入的数据
测试用例
手动处理事务
-- 使用set语句来改变自动提交模式SET autocommit = 0; /*关闭*/SET autocommit = 1; /*开启*/-- 注意:--- 1.MySQL中默认是自动提交--- 2.使用事务时应先关闭自动提交-- 开始一个事务,标记事务的起始点SET autocommit = 0START TRANSACTION -- 提交一个事务给数据库COMMIT-- 将事务回滚,数据回到本次事务的初始状态ROLLBACK-- 还原MySQL数据库的自动提交SET autocommit =1;-- 保存点SAVEPOINT 保存点名称 -- 设置一个事务保存点ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点RELEASE SAVEPOINT 保存点名称 -- 删除保存点
隔离级别
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
索引
帮助mysql高效获取数据的数据结构
分类
-
主键索引(promary key)
- 唯一且不可重复
-
唯一索引(unique key)
- 避免重复的列出现,可重复
-
常规索引(key)
- 默认索引
-
全文索引(fulltext)
-
快速定位索引
-
搜索很长一篇文章的时候,效果最好
-
show index form 表名 -- 显示表中的所有索引create index 索引名 on 表名(\'字段\')alter table 表名.列命 add 索引类型 索引名(‘列名’) -- 添加索引-- explain 分析sql的执行情况explain select * form student where match(student) against(\'刘\')
批量插入数据
DROP FUNCTION IF EXISTS mock_data;DELIMITER $$CREATE FUNCTION mock_data()RETURNS INTBEGINDECLARE num INT DEFAULT 1000000;DECLARE i INT DEFAULT 0;WHILE i < num DO INSERT INTO app_user(`name`, `email`, `phone`, `gender`, `password`, `age`) VALUES(CONCAT(\'用户\', i), \'24736743@qq.com\', CONCAT(\'18\', FLOOR(RAND()*(999999999-100000000)+100000000)),FLOOR(RAND()*2),UUID(), FLOOR(RAND()*100)); SET i = i + 1;END WHILE;RETURN i;END;SELECT mock_data();
索引速度对比
SELECT * FROM app_user WHERE name = \'用户9999\'; -- 查看耗时(1.8s)-- 创建索引CREATE INDEX idx_app_user_name ON app_user(name);EXPLAIN SELECT * FROM app_user WHERE NAME = \'用户9999\';(0.004s)
重点
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表建议不要加索引
- 索引一般应加在查找条件的字段
数据结构
Btree:innodb默认为此类型
参考博客:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
权限管理和备份
创建用户
create user 用户名 identified by \'密码\'
修改密码
set password = password(\'123456\')set password for 用户名 = password(\'新密码\')
重命名
rename user 旧名字 To 新名字
MySQL备份
数据库备份必要性
- 保证重要数据不丢失
- 数据转移
MySQL数据库备份方法
- mysqldump备份工具
- 数据库管理工具,如SQLyog
- 直接拷贝数据库文件和相关配置文件
mysqldump客户端
作用 :
- 转储数据库
- 搜集数据库进行备份
- 将数据转移到另一个SQL服务器,不一定是MySQL服务器
-- 导出1. 导出一张表 -- mysqldump -uroot -p123456 school student >D:/a.sql mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql)2. 导出多张表 -- mysqldump -uroot -p123456 school student result >D:/a.sql mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql)3. 导出所有表 -- mysqldump -uroot -p123456 school >D:/a.sql mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql)4. 导出一个库 -- mysqldump -uroot -p123456 -B school >D:/a.sql mysqldump -u用户名 -p密码 -B 库名 > 文件名(D:/a.sql)可以-w携带备份条件-- 导入1. 在登录mysql的情况下:-- source D:/a.sql source 备份文件2. 在不登录的情况下 mysql -u用户名 -p密码 库名 < 备份文件
数据库的设计
良好的数据库作用:节省内存空间,保证数据完整性,方便系统开发
设计数据库的步骤(个人博客)
- 收集信息,分析需求
- 用户表(用户的登录注销,用户个人信息,写博客,创建分类)
- 分类表(文章类型)
- 文章表(文章信息)
- 链接表(其他链接信息)
- 评论表
- 标识实体(将需求中的表实现,具体到每个字段)
- 标识实体间的关系
三大范式
第一范式
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式
第二范式
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中
第三范式
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关
以上是关于Day18-Mysql基础的主要内容,如果未能解决你的问题,请参考以下文章
[vscode]--HTML代码片段(基础版,reactvuejquery)