数据预处理与转存(Hive--Mysql)
Posted destiny-2015
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据预处理与转存(Hive--Mysql)相关的知识,希望对你有一定的参考价值。
一、数据预处理
1.1、在hdfs上新建目录
java程序启动前先在hdfs上建立相应文件夹,用于上传本地数据和处理后的数据
[root@hadoop102 ~]# hdfs dfs -mkdir -p /USAdatas/geodatas/inputs
[root@hadoop102 ~]# hdfs dfs -mkdir -p /USAdatas/geodatas/output
1.2、运行javaMapReduce代码
将结果上传到hdfs上新建目录/USAdatas/geodatas/inputs下
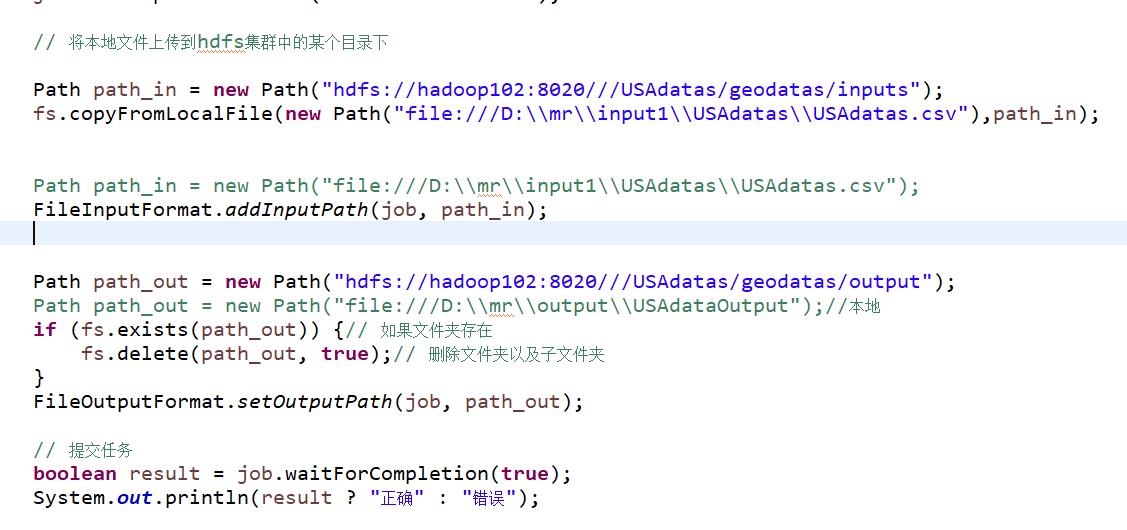
二、数据存储
2.1、创建Hive数据仓库
2.1.1、连接Hive
[root@hadoop102 hive-1.2]# bin/hive
2.1.2、新建数据库
hive> create database db_usa;
2.1.3、使用新建数据库db_usa
hive> use db_usa;
2.1.4、建表
create table t_usaCovid19(
state String,
tot_cases String,
new_case String,
tot_death String,
new_death String,
data String
)
row format delimited
fields terminated by \',\'
;
2.1.5、加载数据
从hdfs上/USAdatas/geodatas/output目录下将处理好的数据加载到新建表t_usaCovid19中
hive> load data inpath \'/USAdatas/geodatas/output/part-r-00000\' into table t_usaCovid19;
查询表,验证数据是否加载成功
hive> select * from t_usaCovid19;
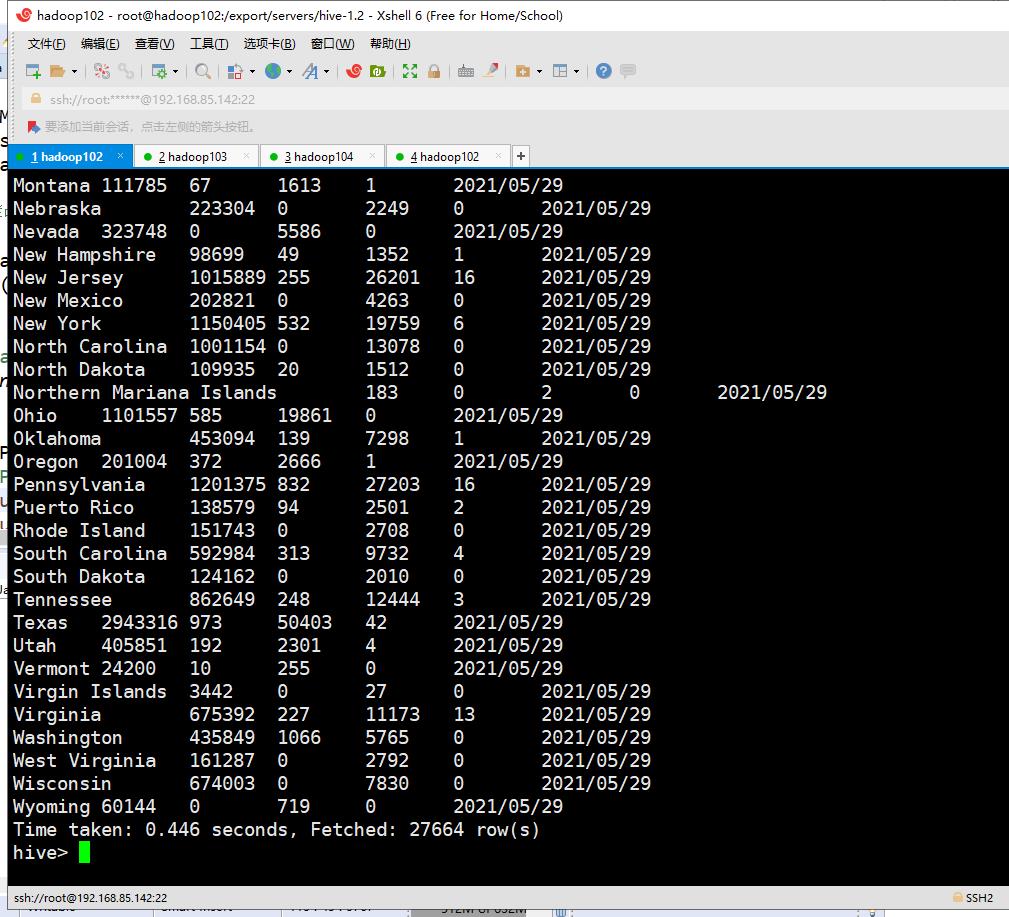
2.2、导出到mysql数据库
2.2.1、在mysql中新建相同结构数据库和表
2.2.2通过sqoop导出hive表
./sqoop export \\
--connect "jdbc:mysql://hadoop104:3306/db_usa?useUnicode=true&characterEncoding=UTF-8" \\
--username root \\
--password 123456 \\
--table t_usaCovid19 \\
--export-dir /user/hive/warehouse/db_usa.db/t_usacovid19 \\
--input-fields-terminated-by \',\' \\
--num-mappers 1
导出成功如下:
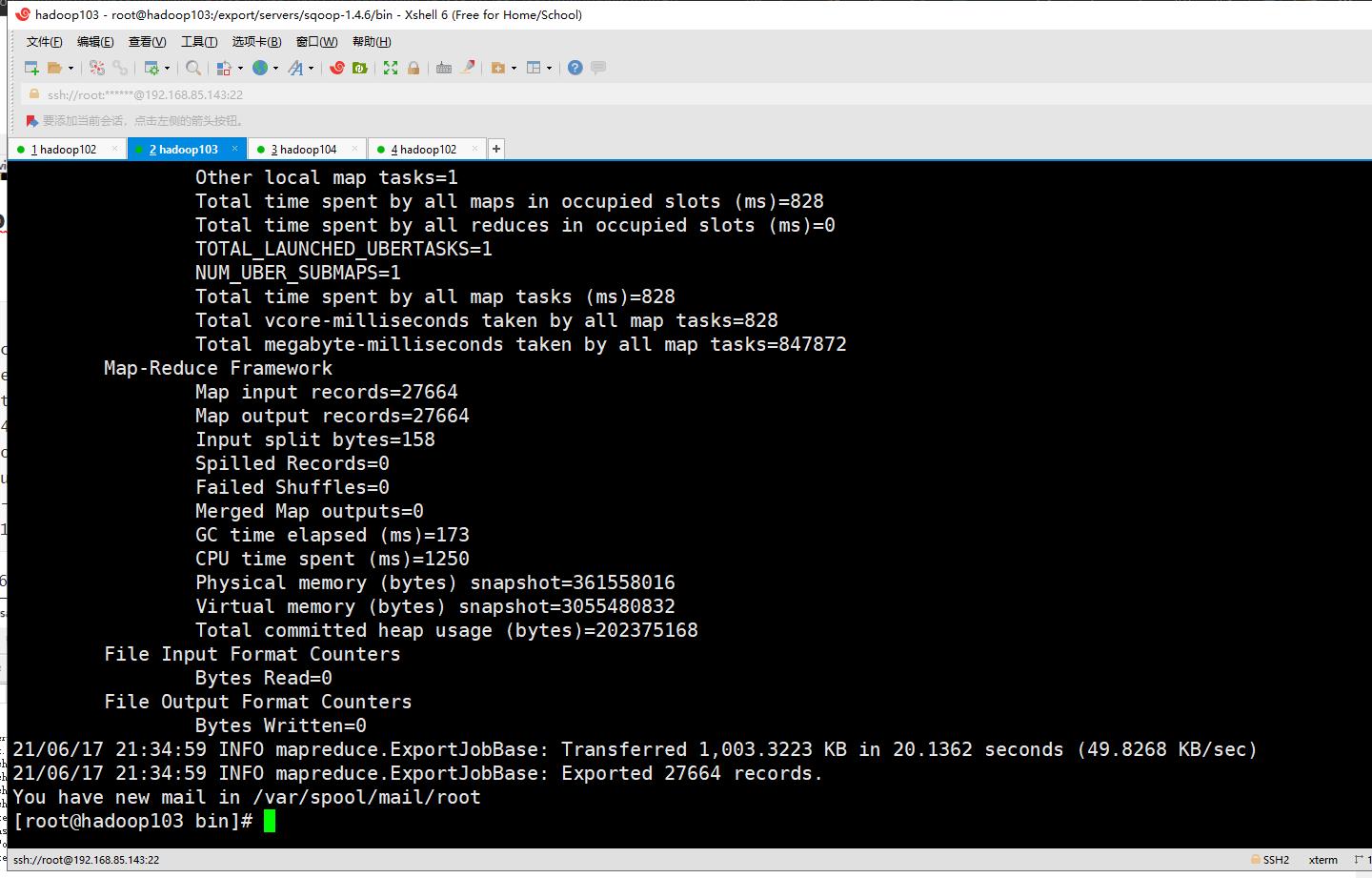
以上是关于数据预处理与转存(Hive--Mysql)的主要内容,如果未能解决你的问题,请参考以下文章