推荐系统(11)—— 消除偏差
Posted 深度机器学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统(11)—— 消除偏差相关的知识,希望对你有一定的参考价值。
1、推荐系统偏差概述
1. Selection Bias
选择偏差主要来自用户的显式反馈,如对物品的评分。由于用户倾向于对自己感兴趣的物品打分,很少对自己很少对自己不感兴趣的物品打分,造成了数据非随机缺失(Missing Not At Random, MNAR)问题,观察到的评分并不是所有评分的代表性样本,于是产生了选择偏差。
解决:数据填充(Data Imputation);倾向分数等。
2. Conformity Bias
一致性偏差是说,用户对物品的评分受用户所在的群体影响,与群体里的其他用户的评分趋于一致,即使这个评分与自己的感受不相符。这导致用户的评分并不总是能反应该用户的真实偏好。
解决:对社会群体或流行度效应进行建模等。
3. Exposure Bias
曝光偏差主要来自用户的隐式反馈,如点击。用户只能看到一部分系统曝光的物品,并作出点击等反应。但是数据中不包含的交互并不一定代表用户不喜欢,还有可能是用户不知道该物品。
解决:启发性置信权重;采样(Sampling)等
4. Position Bias
位置偏差是指,用户倾向于与推荐列表顶部的物品产生交互(点击、购买等),尽管这些物品可能是不相关的或不是最符合偏好的。这导致交互的物品可能并没有很高的相关性。
解决:点击模型(Click models);倾向分数等
5. Popularity Bias
推荐系统数据存在长尾现象,少部分流行度高的物品占据了大多数的交互。推荐模型基于这些数据训练时,通常给流行度高的物品高分,给流行度低的物品低分,这就导致流行度高的物品更频繁地出现在数据中。流行度偏差会降低推荐系统的个性化水平,并导致推荐结果的不公平。
解决:正则化(Regularization);对抗学习(Adversarial learning);因果图(Causal graph)等
6. Unfairness
不公平是指系统不公平地对待某些个人或群体,而偏袒其他用户。如在有些岗位推荐系统中,相比于男性而言,女性可能会更少地被推荐高薪或职业指导服务等广告,造成了性别不公平。
解决:再平衡(Rebalancing);正则化;对抗学习;因果建模(Causal modeling)等
7. Feedback Loop Amplifies Biases
真实的推荐系统通常会形成一个恶性循环,从而扩大各种偏差。以流行度偏差为例,推荐系统的反馈回路会导致流行度高的物品更加流行,而流行度低的物品变得更不受欢迎,这种效应会降低推荐结果的多样性,导致用户的同质化。
解决:通过收集随机数据或强化学习等方式打破循环。
8. Inductive Bias
并不是所有的偏差都是有害的。归纳偏差指通过作出一系列假设,使得模型能更好地学习目标函数进而完成推荐任务。很多假设对推荐模型效果提升都是有帮助的,如MF算法将用户和物品的交互估算成二者向量的内积。
解决方案:推荐系统去偏进展概述
2、位置偏差解决思路
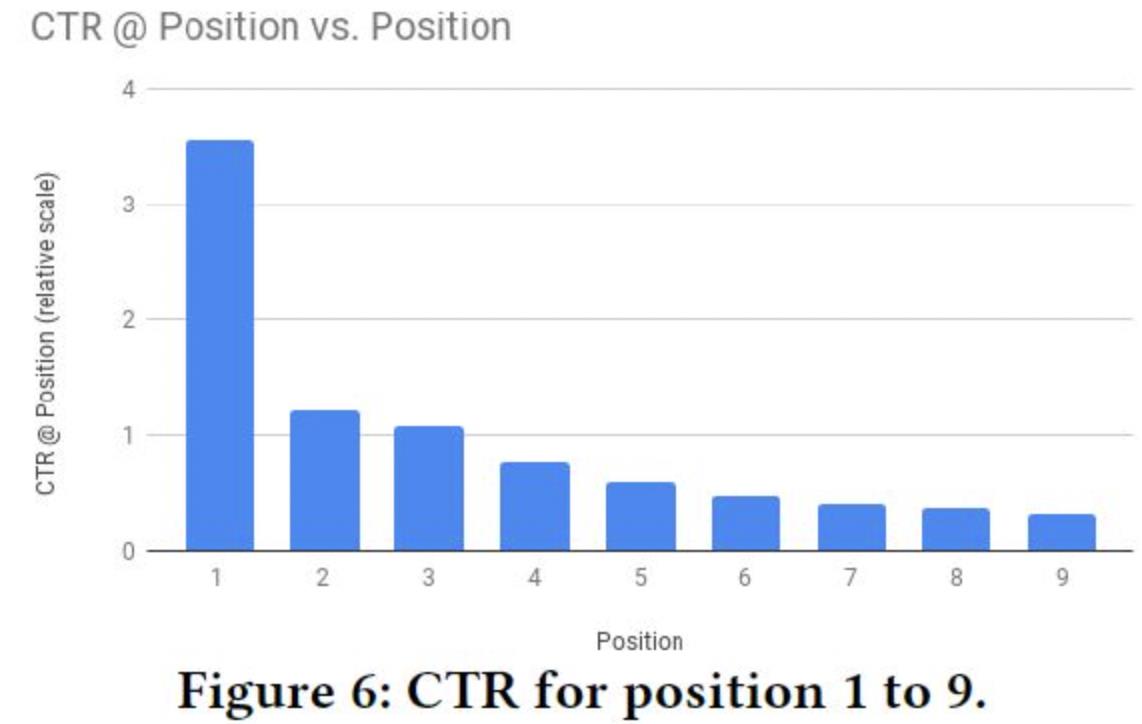
推荐系统中存在各种选择偏差,包括已知的和未知的。位置偏差就是其中一种,用户往往倾向于点击排在前面的item,但这不一定是用户当时最想看的。下图是统计位置1到9的ctr相对分布,位置越靠前,ctr越高,位置越靠后,ctr越低。这是由用户的偏好和位置偏差共同造成的。如果能够消除位置偏差,将用户偏好和偏差独立开来,将有助于提升模型的推荐质量。
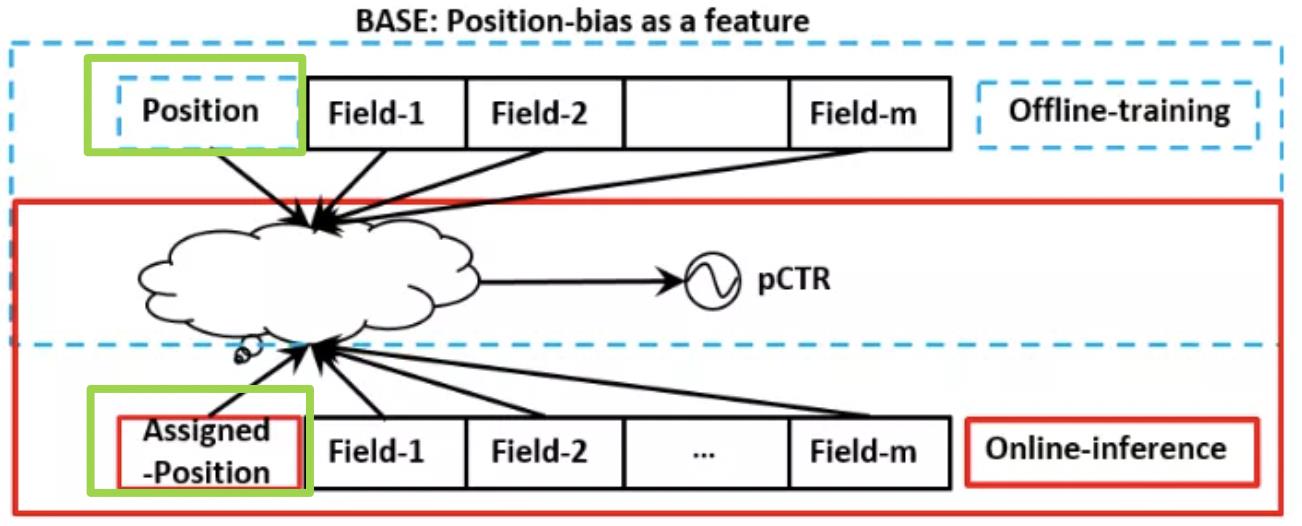
解决方法:
(1)训练时把位置作为输入特征,预测时,或者将位置特征设置为常量,或者设置缺失。
过往也有一些工作来解决位置偏置的问题。最常见的做法是将位置特征作为一个模型训练的一个特征,而在线上预测时,所有候选广告使用相同的位置特征输入。这种方案实现较为简单,但是线上预测时,选择不同的位置,得到的推荐结果会存在差异,结果往往是次优的。
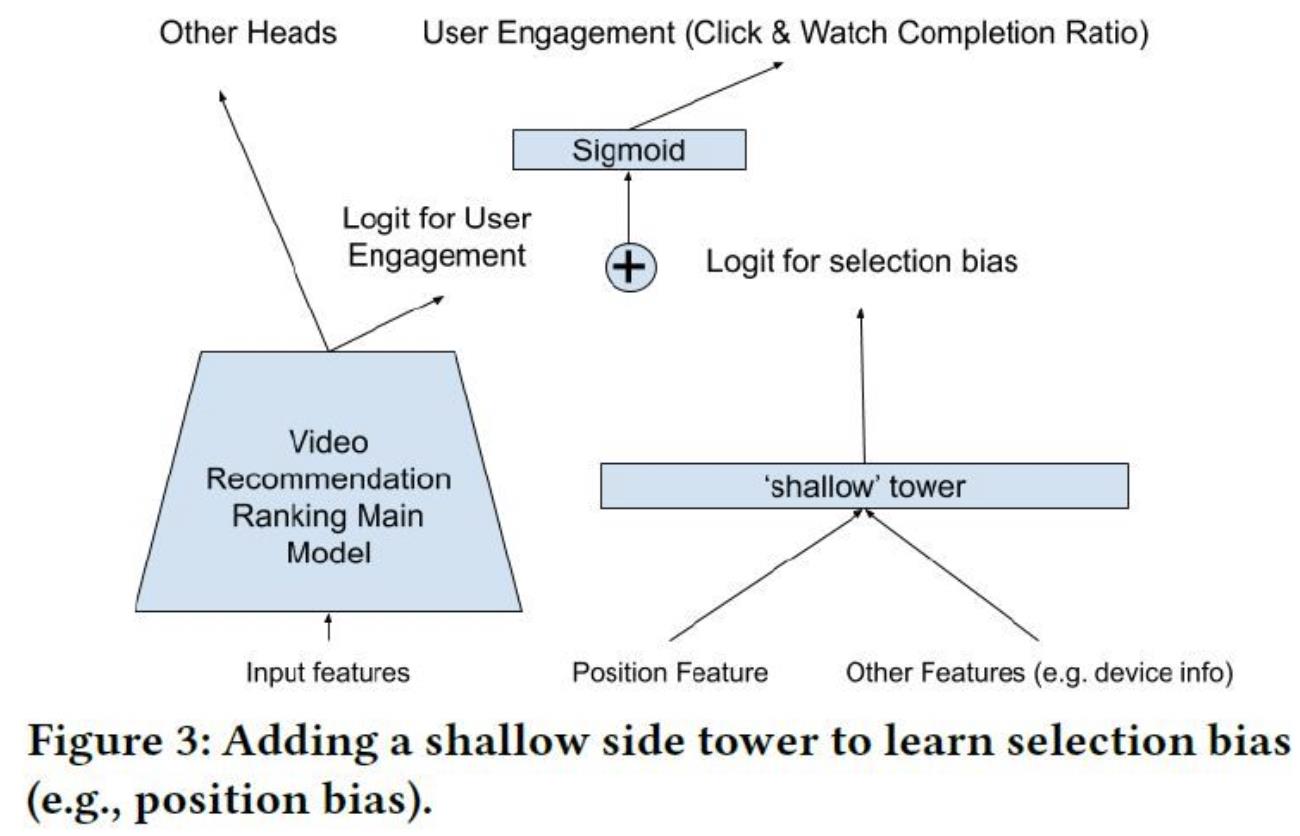
(2)shallow tower
2019.09, Recommending What Video to Watch Next: A Multitask Ranking System
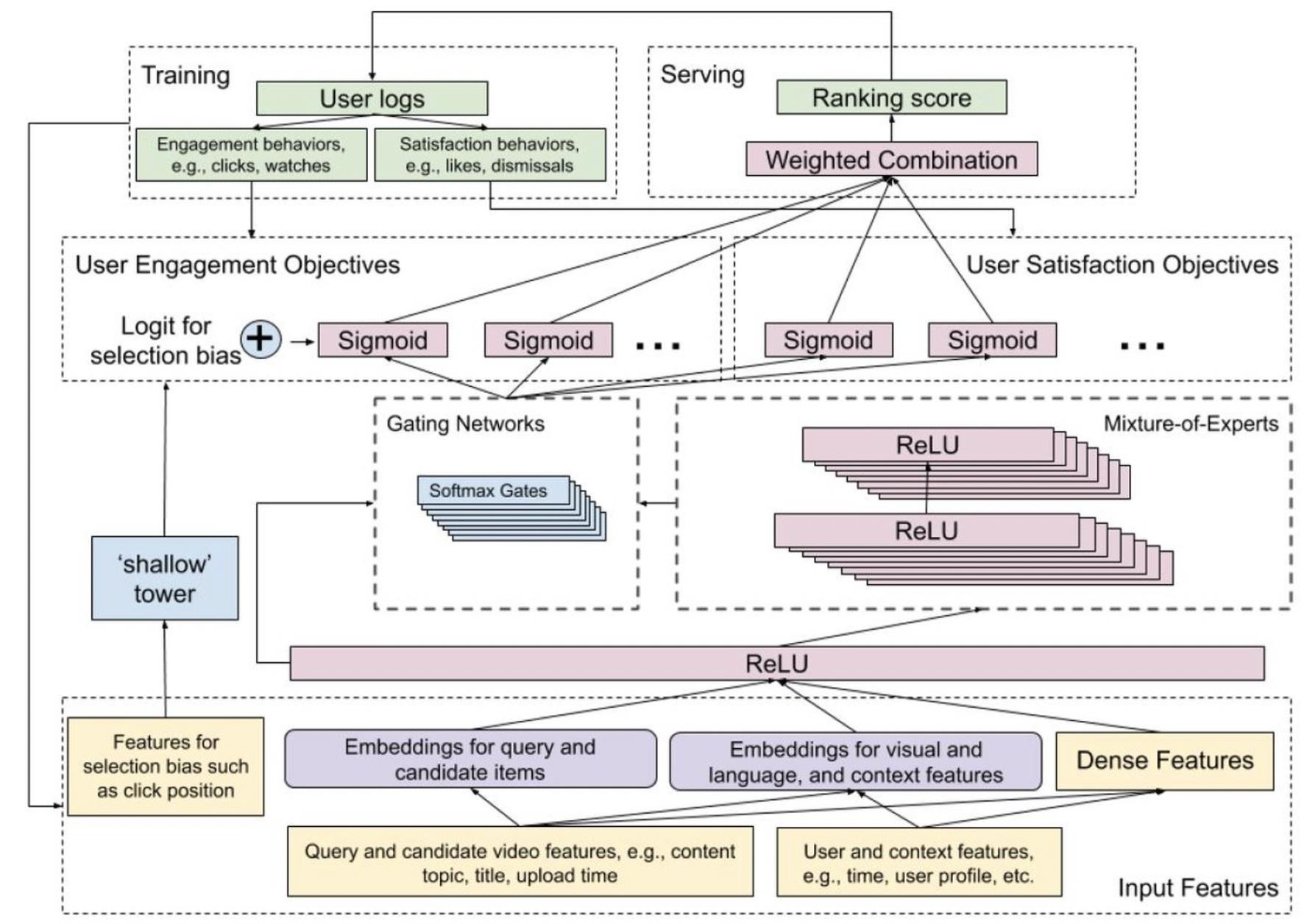
论文提出的方法是如下图所示。在主模型之外,另外添加一个浅层网络或线性网络,输入位置特征,设备特征,以及其他能够带来位置偏差的特征,输出为bias分量。在主模型的输出层,例如CTR预估输出logit,激活函数之前,加上浅层网络的bias分量。训练的时候,每条曝光样本的位置特征都参与训练。文中有提到,随机丢掉10%的特征,防止模型过度依赖位置特征。不过我不确定,这里所说的10%的特征,是位置特征,还是主模型的输入特征。预测的时候,可以丢掉浅层网络,或者将浅层网络的位置特征都置为缺失。另外,需要对位置特征和设备信息做特征组合,原因是在不同的设备上会观察到不同的位置偏差。
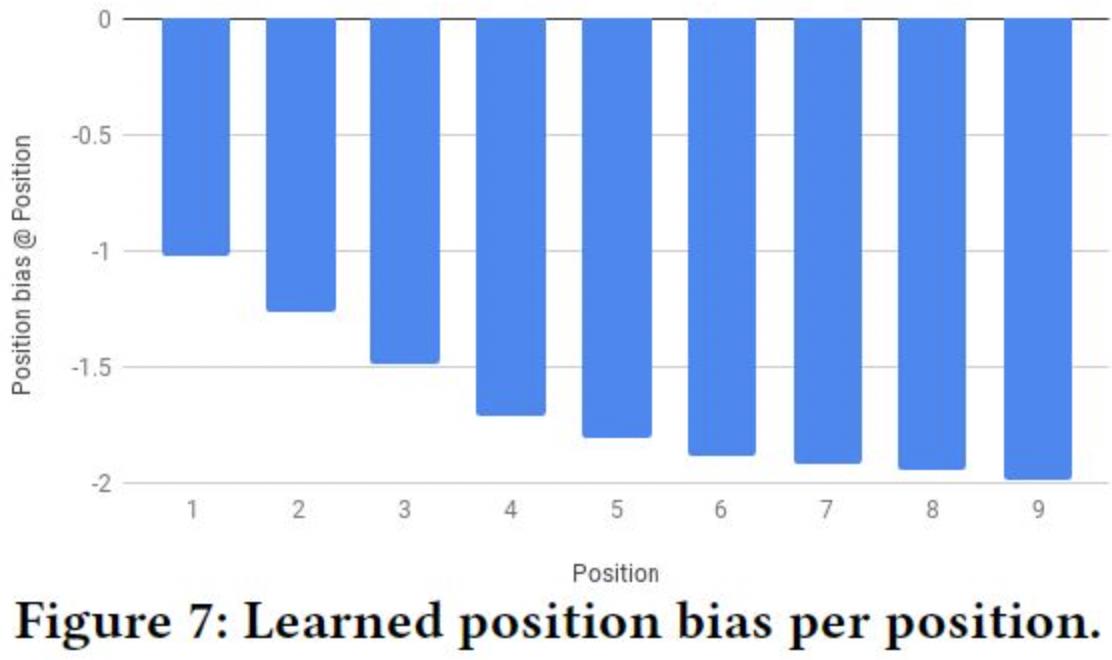
下图反映了不同位置的偏差,位置越靠前,位置带来的偏差越小,位置越靠后,偏差越大,因为越靠后,用户更有可能看不到。
完整的模型结构如下图所示。模型对每一个任务都做预估,最后将所有任务的预估值做加权得到最终的分数,作为排序的依据,比较麻烦的是,权重需要人工调参。训练的时候,消除位置偏差的浅层网络只需要加到CTR预估值即可,因为位置偏差只会影响用户是否看到并点击,对其他行为不影响。相比于一般的embedding+MLP的网络结构,上图模型只是将DNN部分替换为MMoE网络,对embedding部分并不影响。
(3)PAL
2019.09,PAL: A Position-bias Aware Learning Framework for CTR Prediction in Live Recommender Systems
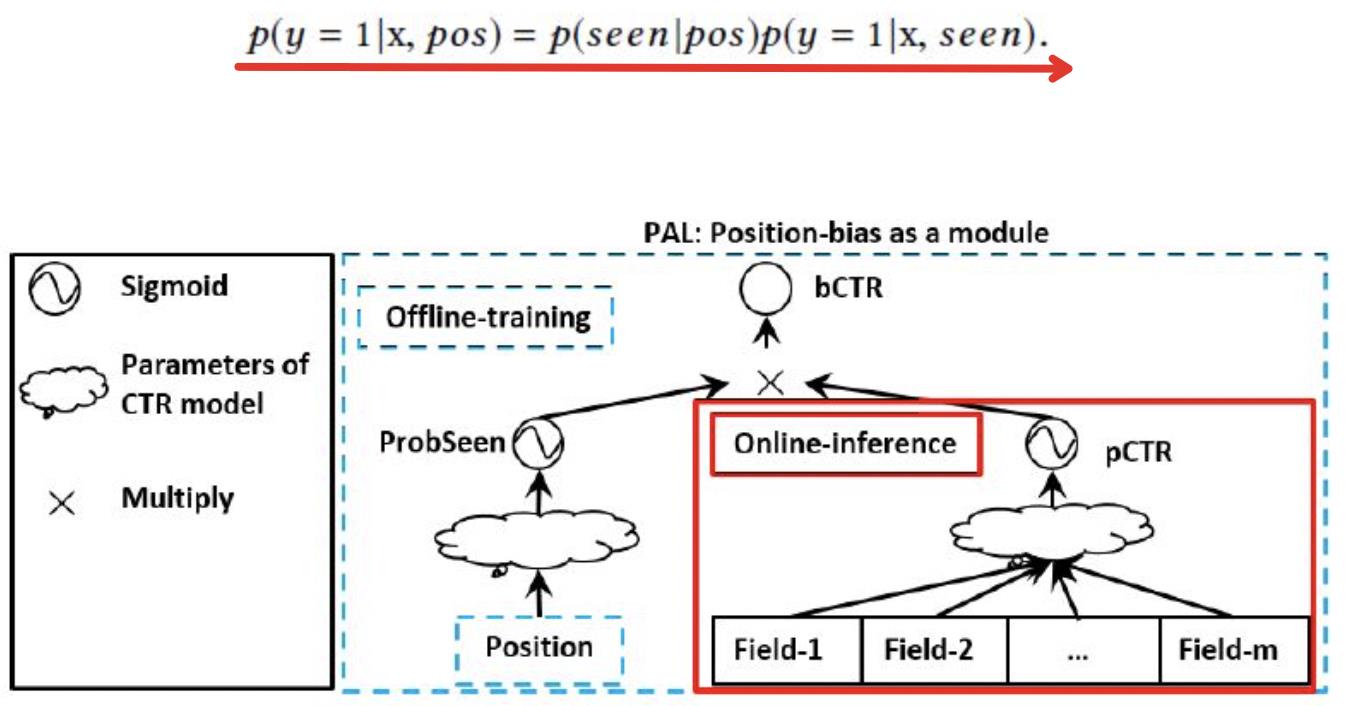
PAL将点击率预估值按照条件概率分解为,在某个位置被用户看到的概率,乘以看到之后物品x被点击的概率,计算公式和网络结构如下图所示。网络结构同样也是在主模型之外添加了一个辅助网络,只输入位置相关特征。训练的时候,将两个模型的输出预估值相乘;预测的时候,只使用主模型的结果,丢掉辅助网络。和youtube的做法有相似之处。
华为提出的PAL框架将广告被点击的概率分为两个因素:广告被用户看到的概率和用户看到广告后点击的概率。论文做了进一步的假设:用户是否看到广告只跟广告的位置有关系;同时,用户看到广告后,是否点击广告与位置无关。因此整个框架也是包含两个部分,如下图所示。在线上预测时,只需要部署右边的网络,所得到的点击率就是消除了位置偏置后的点击率。这种方案的缺点是假设太强,将问题过于简化了,没有充分考虑位置偏置与用户特征、上下文特征以及候选item之间的关系。

(4)DPIN
假设有J个候选广告、K个位置,每次计算的耗时为C,那么预测J个广告在K个位置的整体时间复杂度为O(JKC),这显然是线上扛不住的。因此论文将整个DPIN拆解为了三个模块,分别是base module、deep position-wise interaction module和position-wise combination module,如下图所示。接下来对这几部分module进行分别介绍。
快手推荐方式:
https://www.zvstus.com/article/news/1/4e347ffffe889eece1621f3c43540000.html
学习笔记:https://pnyuan.github.io/blog/recsys/%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0%20-%20DNN%20for%20YouTube%20Recommendations/
https://mp.weixin.qq.com/s/Y3A8chyJ6ssh4WLJ8HNQqw
参考文献:
以上是关于推荐系统(11)—— 消除偏差的主要内容,如果未能解决你的问题,请参考以下文章