pandas(13):数据清洗(重复记录)
Posted 数据の变异
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas(13):数据清洗(重复记录)相关的知识,希望对你有一定的参考价值。
数据源:
df= pd.DataFrame({\'k1\': [ \'s1\']* 3 + [\'s2\']* 5,\'k2\' : [1, 1, 2, 3, 3, 4, 4,4]})
df
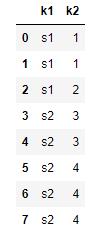
1 重复值判断和查看
df.duplicated(subset=None, keep=\'first\')
功能:
指定列数据重复项判断,返回指定列重复行boolean Series.
参数说明:
- subset=None:列标签或标签序列,可选,只考虑某些列来识别重复项;默认使用所有列。
- keep=\'first\':{\'first\',\'last\',False}
- first:将第一次出现重复值标记为True。
- last:将最后一次出现重复值标记为True。
- False:将所有重复项标记为True。
# 默认判断所有列,只有第一条不标记为true,后面重复出现的都是true
df.duplicated()
# subset=[list],只判断指定列
df.duplicated(subset=[\'k1\'])
# keep=\'last\',只最后一次不标记为true,前面的都标记为true
df.duplicated(keep=\'last\')
# keep=false,所有重复项都标记为true
df.duplicated(keep=False)

# 查看记录重复数量,不包括首次出现那条记录
df.duplicated().value_counts()
# 查看记录重复的所有数量
df.duplicated(keep=False).value_counts()
# 查看所有重复记录
df[df.duplicated(keep=False)]
# 查看除首条外的所有重复记录
df[df.duplicated()]
2 重复值删除
df.drop_duplicates(subset=None, keep=\'first\', inplace=False)

以上是关于pandas(13):数据清洗(重复记录)的主要内容,如果未能解决你的问题,请参考以下文章