Python 机器学习避免碰撞课程设计
Posted Neroha
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 机器学习避免碰撞课程设计相关的知识,希望对你有一定的参考价值。
随机森林模型
随机森林(Random Forest)是一种基于分类树的算法。2001年Breiman和Cutler借鉴贝尔实验室的Ho所提出的随机决策森林的方法,把分类树组合成随机森林,即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。随机森林在运算量没有显著提高的前提下提高了预测精度。同时,该方法对多元共线性不敏感,结果对缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用,被誉为当前最好的算法之一。在机器学习的诸多算法中,随机森林因高效而准确而备受关注,在各行各业得到越来越多的应用
该模型是建立在决策树模型和Bagging算法的基础上发展而来的。它具有两重随机性:
- 数据的随机选取。首先,从原始的数据集中釆取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果。
- 待选特征的随机选取。与数据集的随机选取类似,随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随杋选取的特征中选取最优的特征。这样能够使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
随机森林的生成过程分以下4步:
- Bagging过程:假设训练集中有N个样本,利用bootstrap方法有放回地随机抽取n个样本,作为一棵决策树的训练样本
- 分裂属性选择过程:假设特征向量是m维,选取m1维作为子集指定给每个节点,从m1中选择分类效果最佳的一维特征作为接点的分类属性,且保证在随机森林的生长过程中m1保持不变
- 决策树的生长过程:当每个节点的分类纯度达到期望比例或者生长层数达到给定值时,则停止决策树的生长,保证每个决策树都保证最大限度的生长,且没有剪枝情况。
- 生成随机森林过程:重复step1-Step3,生长出多颗决策树,从而生成森林,通过对子决策树的判断结果的投票,得到随机森林的输出结果。
XGBoost模型
极端梯度提升树,是2015年由陈天奇博士提出的一种规模较大的算法,它在Gradient Boosting框架下既实现了提升决策树,又实现了一些广义的线性机器学习算法。
深度森林模型
多粒度级联森林(multi- Grained Cascade forest, GCForest)是2017年南京大学的周志华教授和冯霁博士提出的一种基于随机森林的集成方法,也是种深度学习模型,周志华教授也将其称作深度森林(Deep Forest)。随机森林是深度森林算法的组成单元,可以说深度森林算法有着随机森林髙效准确和可拓展的优点,在网络结构上又和深度神经网络很相似,具有深度模型逐层加工,特征转换,和结构复杂的特征。更重要的是,同样作为深度模型,深度森林和深度神经网络相比超参数的数量较少,而且对超参数的依赖性也更低,因此深度森林的训练更为便捷,理论分析也更为清晰。该算法不仅可以增强输入特征的差异性,还可以提高输入特征的分类能力。
#导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn import preprocessing
from sklearn.metrics import mean_squared_error
import seaborn as sns
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.decomposition import PCA
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPRegressor #神经网络回归
from sklearn.metrics import mean_absolute_error #平均绝对误差MAE
from sklearn.metrics import mean_squared_error #平均平方误差MSE
from sklearn.ensemble import RandomForestRegressor #随机森林
from xgboost import XGBRegressor #XGBoost
from xgboost import plot_importance #输出权重
from deepforest import CascadeForestRegressor #深度森林
import joblib #保存模型
from tqdm import tqdm #进度条
plt.style.use(\'classic\')
%matplotlib inline
#数据清洗
# train_data.csv数据集来源:开尔文斯 - 避免碰撞挑战 - 数据 (esa.int)
file_path=\'train_data.csv\'
data=pd.read_csv(file_path,parse_dates=True)
# data.drop(columns=[\'c_rcs_estimate\',\'event_id\'],inplace=True) #event_id只记录第几次事件,无效信息。c_rcs_estimate缺失五万多条数据,占比32.49%,所以删去(其余最多缺失九千多条)
key=data.keys()
data.head(10)
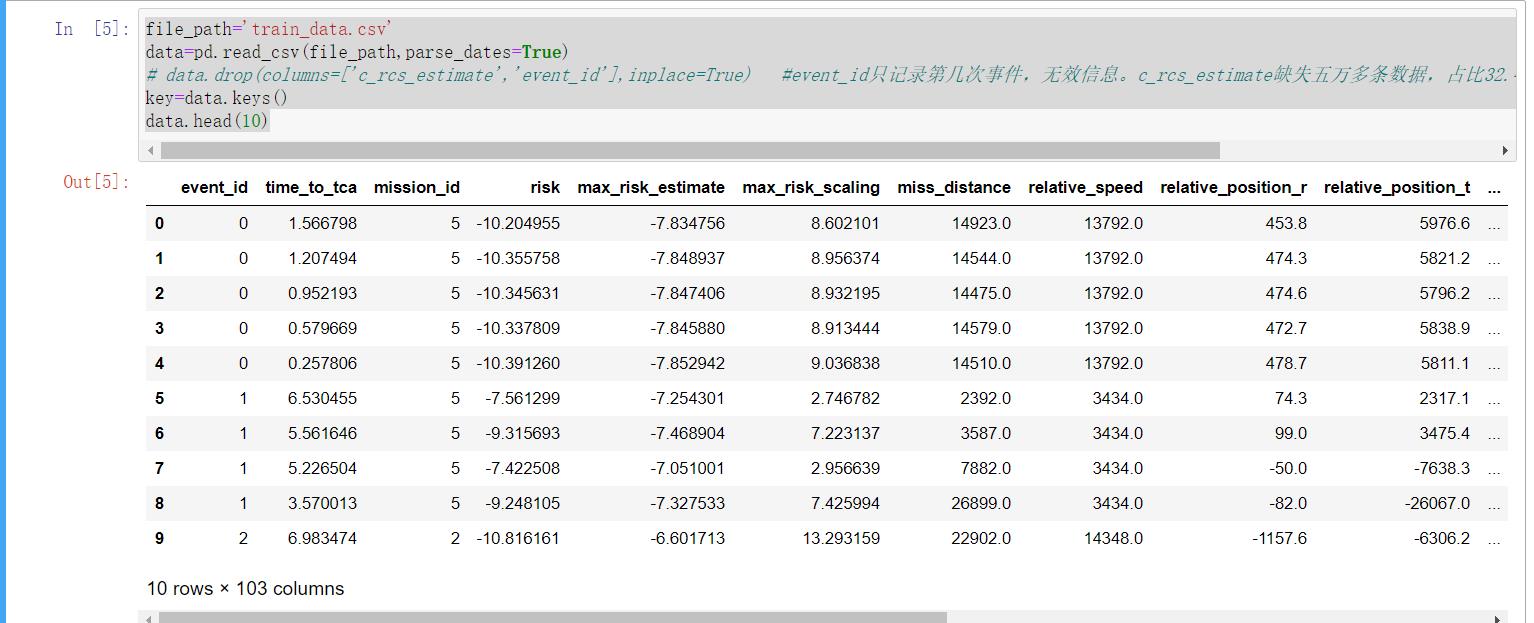
#有100列数值标签 1列字符串标签,需将字符标签转换为数值标签
data.info()
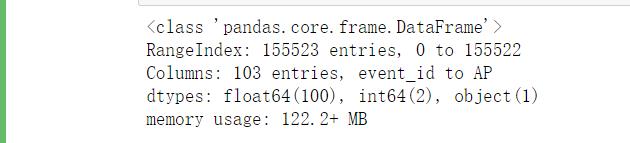
# #event_id只记录第几次事件,无效信息。c_rcs_estimate缺失五万多条数据,占比32.49%,
data.drop(columns=[\'c_rcs_estimate\',\'event_id\'],inplace=True)
# 从数据中划分出预测标签列
y = data.risk
X = data.drop([\'risk\'], axis=1) #预测标签列\'risk\'
# 将数据划分为训练集和测试集
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2)
#选取标签列,独立字符串标签数小于10且dtype格式为object
categorical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].nunique() < 10 and
X_train_full[cname].dtype == "object"]
# 选择数值列
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in [\'int64\', \'float64\']]
# 只保留数值列和标签列
my_cols = categorical_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()
labels=my_cols[1:]+[(my_cols[0]+\'(%i)\')%i for i in range(1,6)]
#处理数值类型数据
# numerical_transformer = SimpleImputer(strategy=\'constant\')
numerical_transformer =Pipeline(steps=[(\'imputer\',SimpleImputer(strategy=\'most_frequent\')), #缺失值处理,用众数填充
# (\'reduce_dim\', PCA()), #PCA降维,已经放弃,加了之后效果更差
(\'scaler\', StandardScaler())]) #这里用zscore标准化方法,即x\'=(x-u)/sigma,也可以考虑用MinMaxScaler,即0-1归一化
#处理字符串类型数据
categorical_transformer = Pipeline(steps=[
(\'imputer\', SimpleImputer(strategy=\'most_frequent\')), #缺失值处理,用众数填充
(\'onehot\', OneHotEncoder(handle_unknown=\'ignore\')) #忽略未知的分类特征
])
#捆绑数值和分类数据的预处理
preprocessor = ColumnTransformer(transformers=[(\'num\', numerical_transformer, numerical_cols),
(\'cat\', categorical_transformer, categorical_cols)])
preprocessor.fit(X_train)
X_train=preprocessor.transform(X_train)
X_valid =preprocessor.transform(X_valid)
#随机森林模型1-100棵树
#随机森林模型 100个树
# 重要参数 n_estimators 弱学习器个数,默认100 oob_score 是否袋外采样 默认false 建议True
#criterion 评价标准 回归RF有mae,默认mse 不用改
# model = RandomForestRegressor(n_estimators=100, random_state=0,verbose=2)
model2_1 = RandomForestRegressor(n_estimators=100,oob_score=True,verbose=2,n_jobs=4) #100棵树 开启袋外采样 打印状态 4个核心并行
model2_1.fit(X_train,y_train) #训练集拟合
preds2_1 = model2_1.predict(X_valid) #进行预测
# score2_1 = mean_absolute_error(y_valid, preds) #测量平均绝对误差MAE
score2_1 = mean_squared_error(y_valid, preds2_1) #测量均方误差MSE
print(\'MSE:\', score2_1) #0.011356733866017094
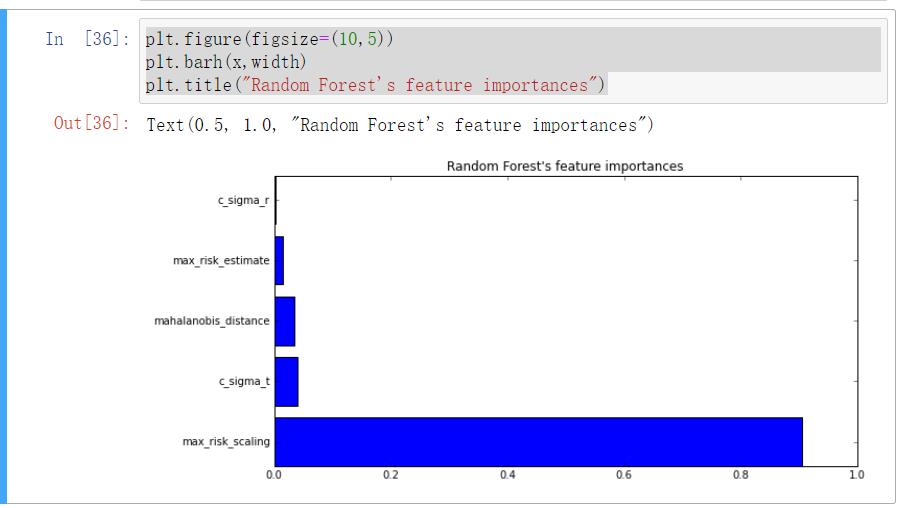
z=zip(model2_1.feature_importances_,labels)
z=sorted(z,reverse=True)[:5]
x=[i[1] for i in z]
width=[i[0] for i in z]
plt.figure(figsize=(10,5))
plt.barh(x,width)
plt.title("Random Forest\'s feature importances")
#随机森林模型2-200棵树
model2_2 = RandomForestRegressor(n_estimators=200,oob_score=True,verbose=1,n_jobs=4)
#训练集拟合
model2_2.fit(X_train, y_train)
# model2_2= joblib.load("model2_2.m") #如果已经保存模型,可以将上述两行注释掉,直接运行此行读取model2_2 之后类似处同理
#进行预测
preds2_2 = model2_2.predict(X_valid)
#模型评价
# score2_2 = mean_absolute_error(y_valid, preds2_2)
score2_2 = mean_squared_error(y_valid, preds2_2) #测量均方误差MSE
# print(\'MAE:\', score2_2)
print(\'MSE:\', score2_2) #0.011637681219676775
xgboost模型
#xgboost模型-100个预测器
X_train_test=pd.DataFrame(X_train)
X_train_test.columns=labels
X_valid_test=pd.DataFrame(X_valid)
X_valid_test.columns=labels
#XGBRegressor模型 参考文档 https://xgboost.readthedocs.io/en/latest/parameter.html#general-parameters
# XGBClassifier(learning_rate =0.1,n_estimators=1000,max_depth=4,min_child_weight=6,gamma=0,subsample=0.8,colsample_bytree=0.8,reg_alpha=0.005,objective= \'binary:logistic\',
# nthread=4,scale_pos_weight=1,seed=27) #XGBoost的可调参数
evals_result={}
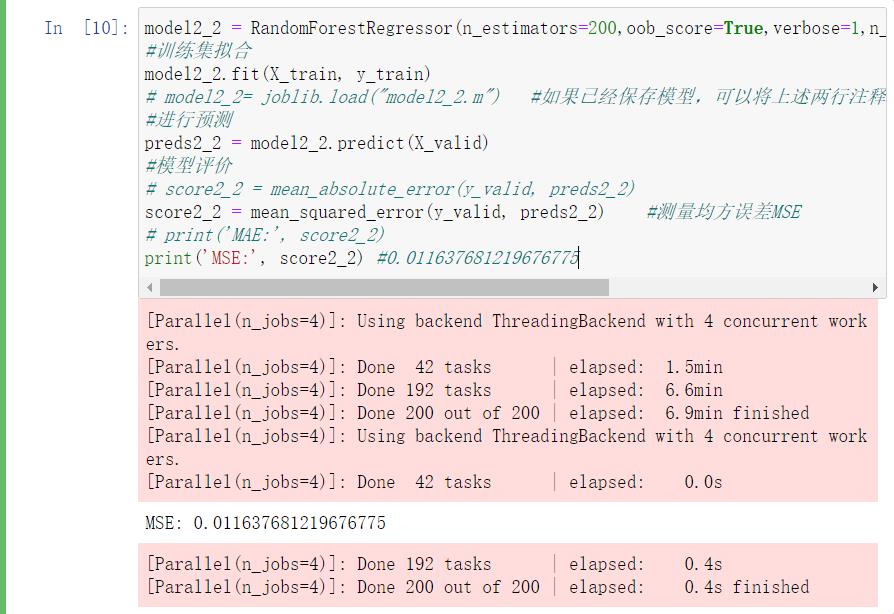
model3_1 = XGBRegressor(verbosity=1,evals_result=evals_result) #默认n_estimators=100,XGBoost 默认开启并行,且进程数设置为按当前机器配置的最大核心数
eval_s = [(X_train_test, y_train),(X_valid_test,y_valid)]
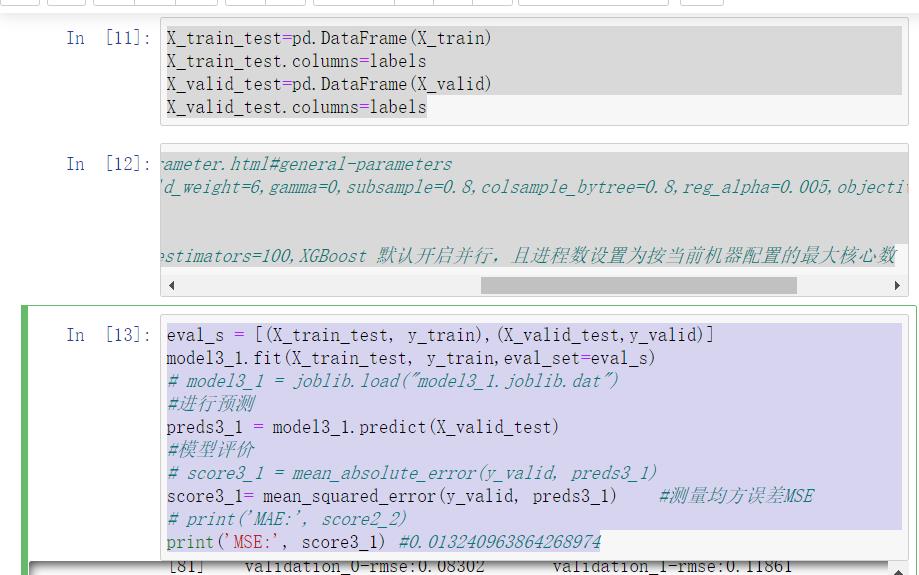
model3_1.fit(X_train_test, y_train,eval_set=eval_s)
# model3_1 = joblib.load("model3_1.joblib.dat")
#进行预测
preds3_1 = model3_1.predict(X_valid_test)
#模型评价
# score3_1 = mean_absolute_error(y_valid, preds3_1)
score3_1= mean_squared_error(y_valid, preds3_1) #测量均方误差MSE
# print(\'MAE:\', score2_2)
print(\'MSE:\', score3_1) #0.013240963864268974
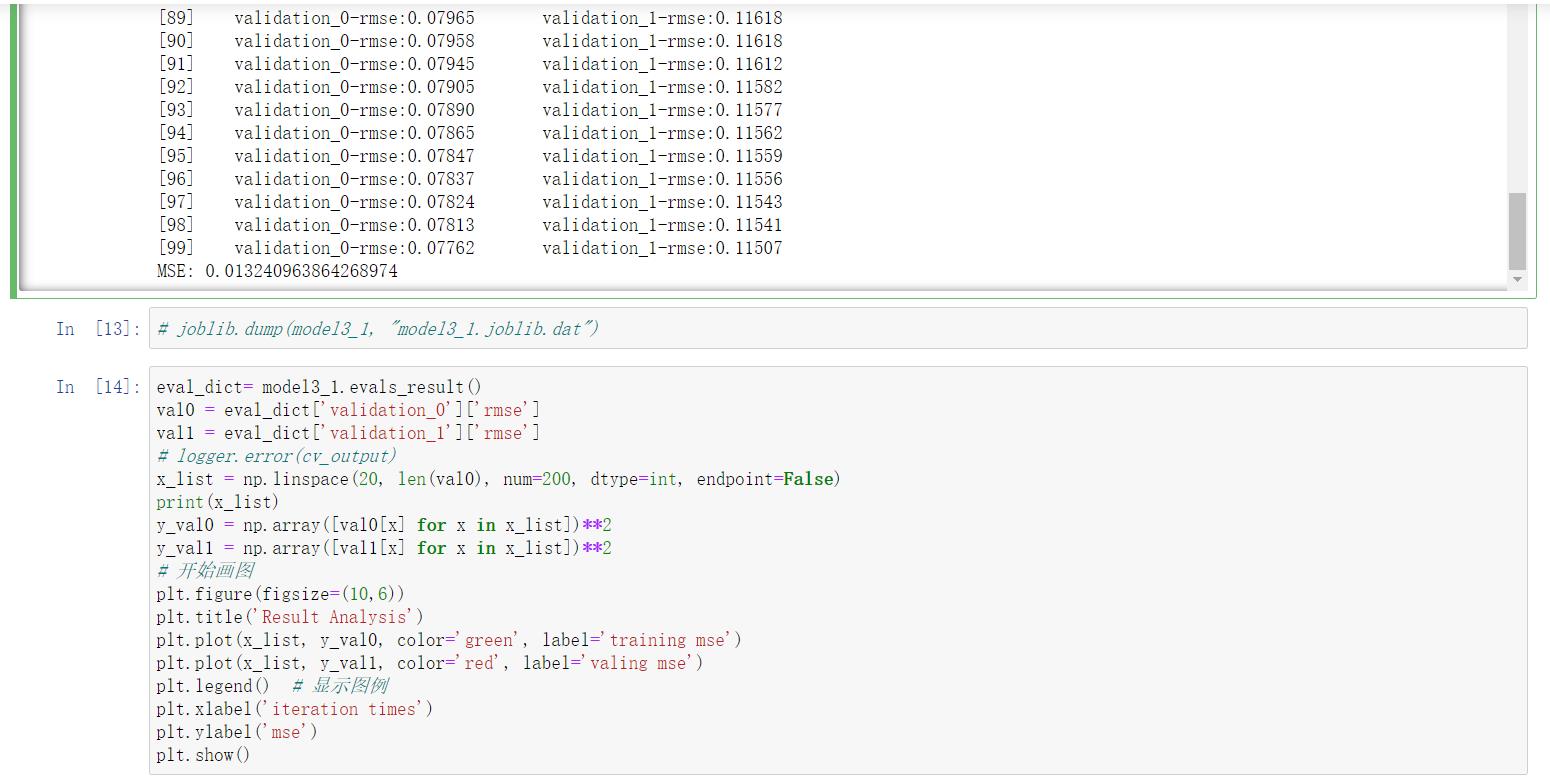
eval_dict= model3_1.evals_result()
val0 = eval_dict[\'validation_0\'][\'rmse\']
val1 = eval_dict[\'validation_1\'][\'rmse\']
# logger.error(cv_output)
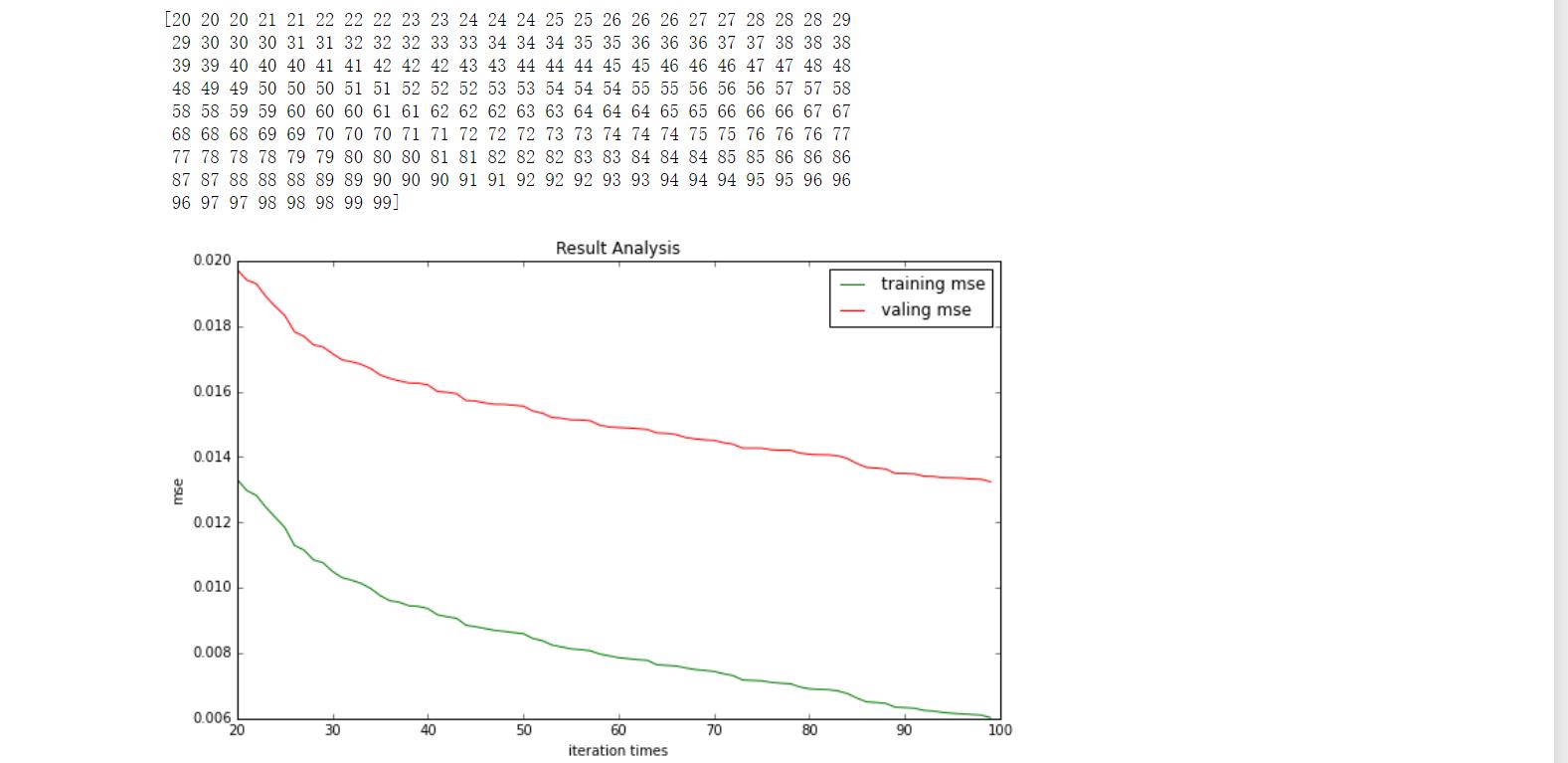
x_list = np.linspace(20, len(val0), num=200, dtype=int, endpoint=False)
print(x_list)
y_val0 = np.array([val0[x] for x in x_list])**2
y_val1 = np.array([val1[x] for x in x_list])**2
# 开始画图
plt.figure(figsize=(10,6))
plt.title(\'Result Analysis\')
plt.plot(x_list, y_val0, color=\'green\', label=\'training mse\')
plt.plot(x_list, y_val1, color=\'red\', label=\'valing mse\')
plt.legend() # 显示图例
plt.xlabel(\'iteration times\')
plt.ylabel(\'mse\')
plt.show()
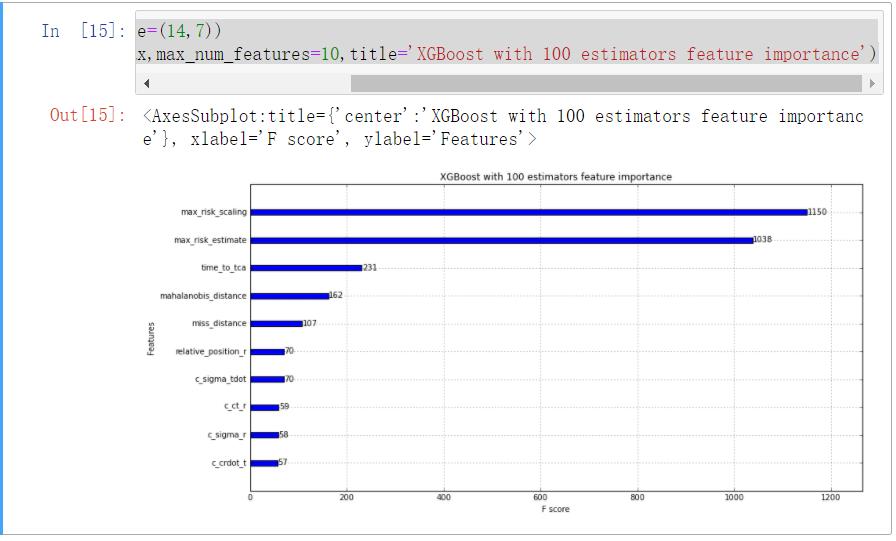
fig, ax = plt.subplots(figsize=(14,7))
plot_importance(model3_1,ax=ax,max_num_features=10,title=\'XGBoost with 100 estimators feature importance\')
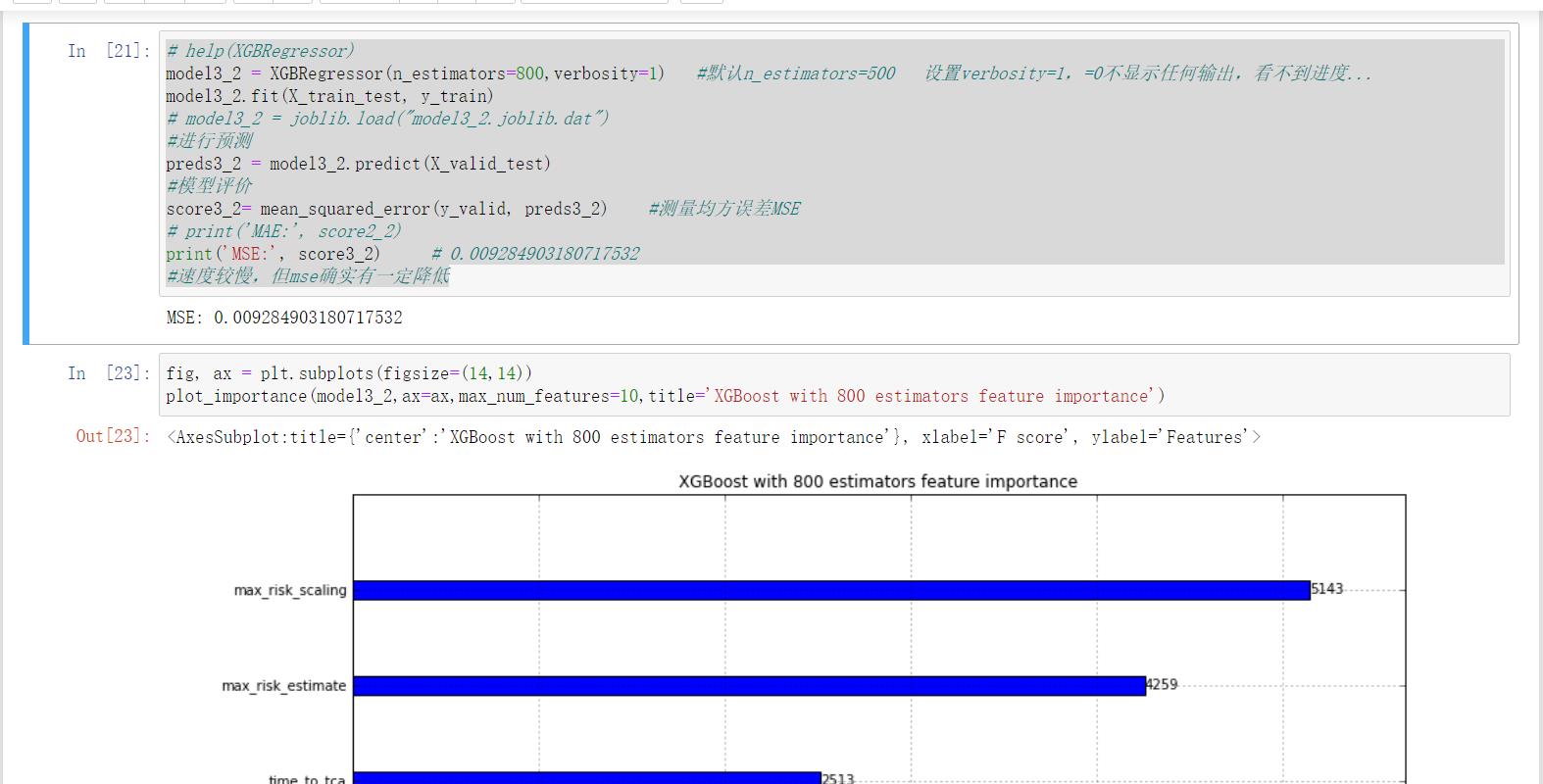
#xgboost模型-800个预测器
# help(XGBRegressor)
model3_2 = XGBRegressor(n_estimators=800,verbosity=1) #默认n_estimators=500 设置verbosity=1,=0不显示任何输出,看不到进度...
model3_2.fit(X_train_test, y_train)
# model3_2 = joblib.load("model3_2.joblib.dat")
#进行预测
preds3_2 = model3_2.predict(X_valid_test)
#模型评价
score3_2= mean_squared_error(y_valid, preds3_2) #测量均方误差MSE
# print(\'MAE:\', score2_2)
print(\'MSE:\', score3_2) # 0.009284903180717532
#速度较慢,但mse确实有一定降低
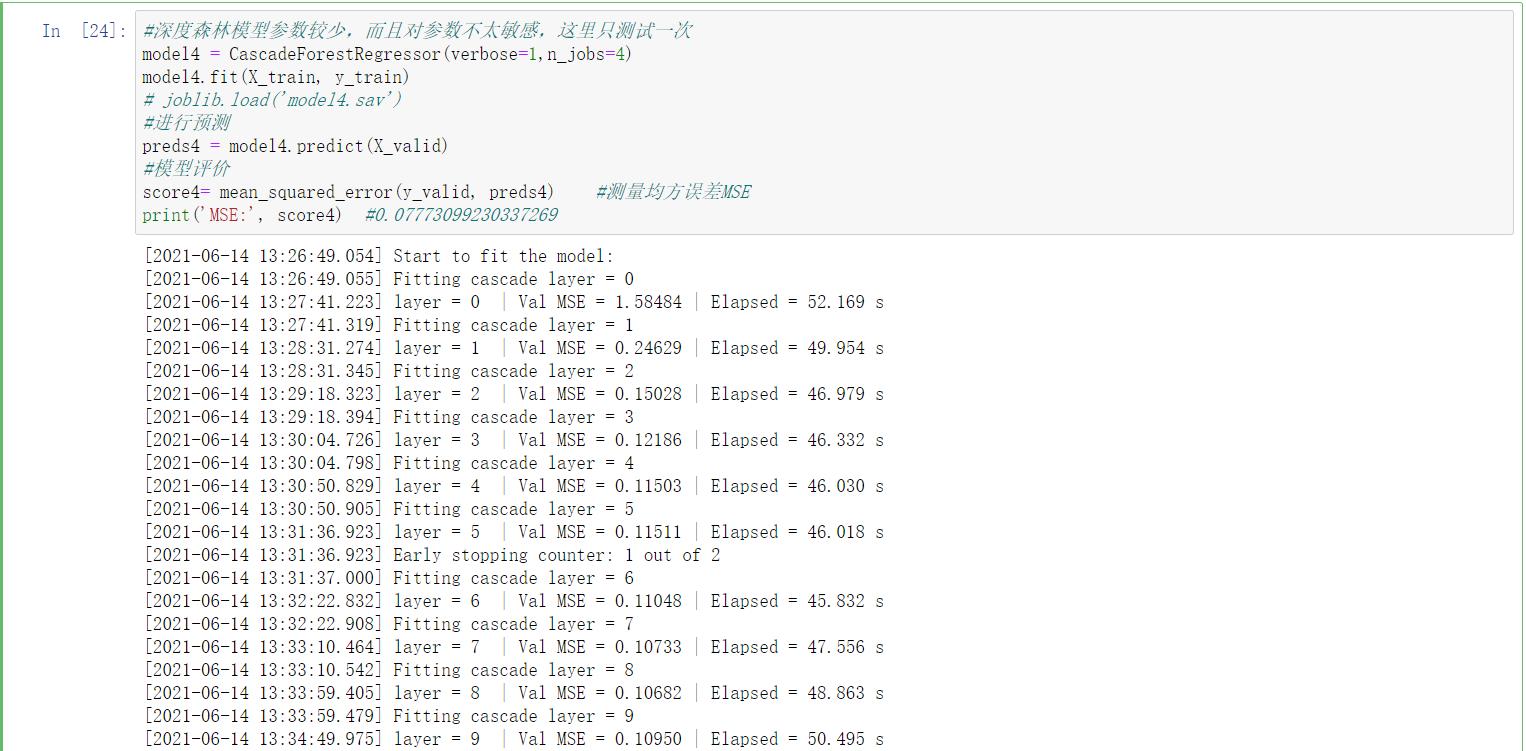
#目前来看XGBoost模型效果最好,可以进一步考虑调整树深度max_depth等参数,对于SVM方法,样本太多,速度极慢,不太适合,已弃用
#深度森林
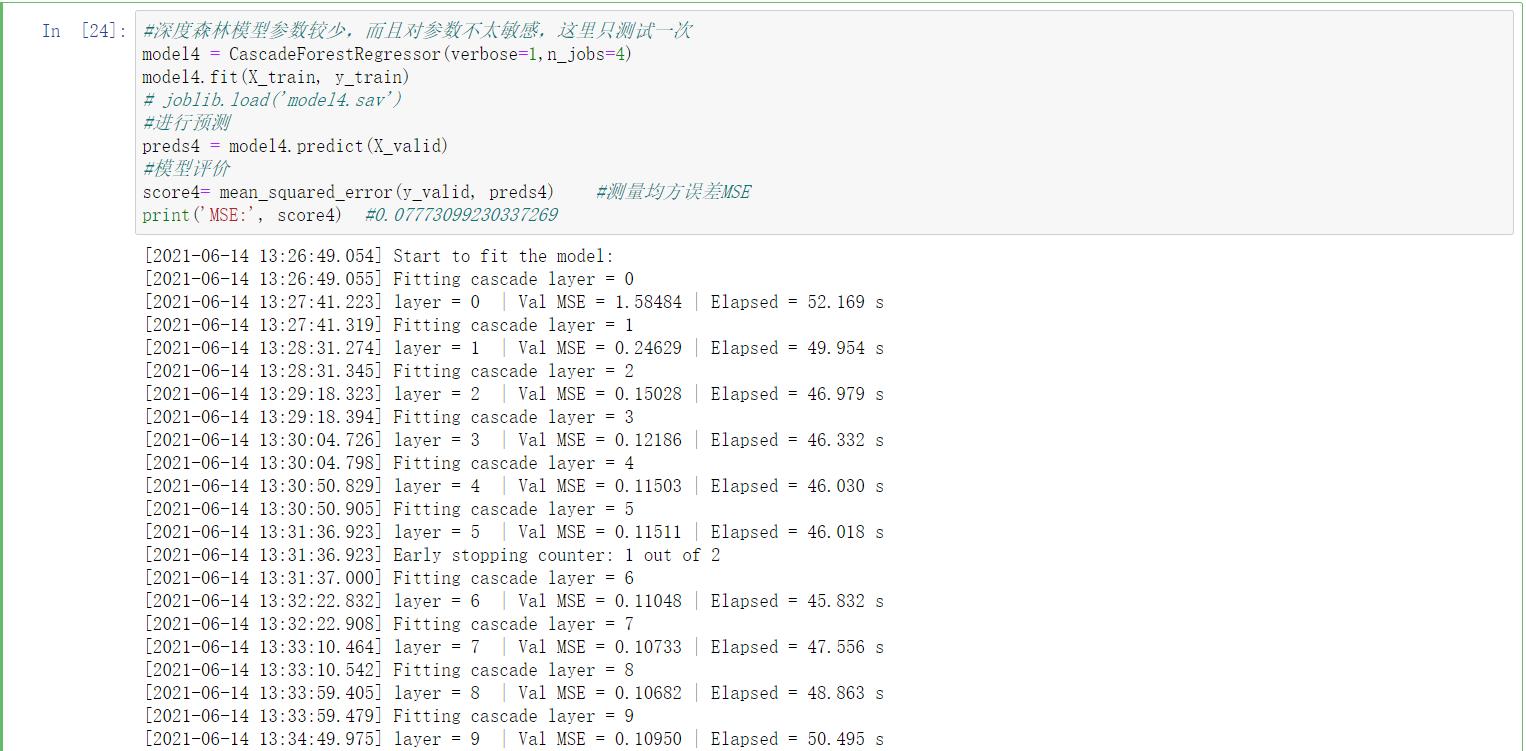
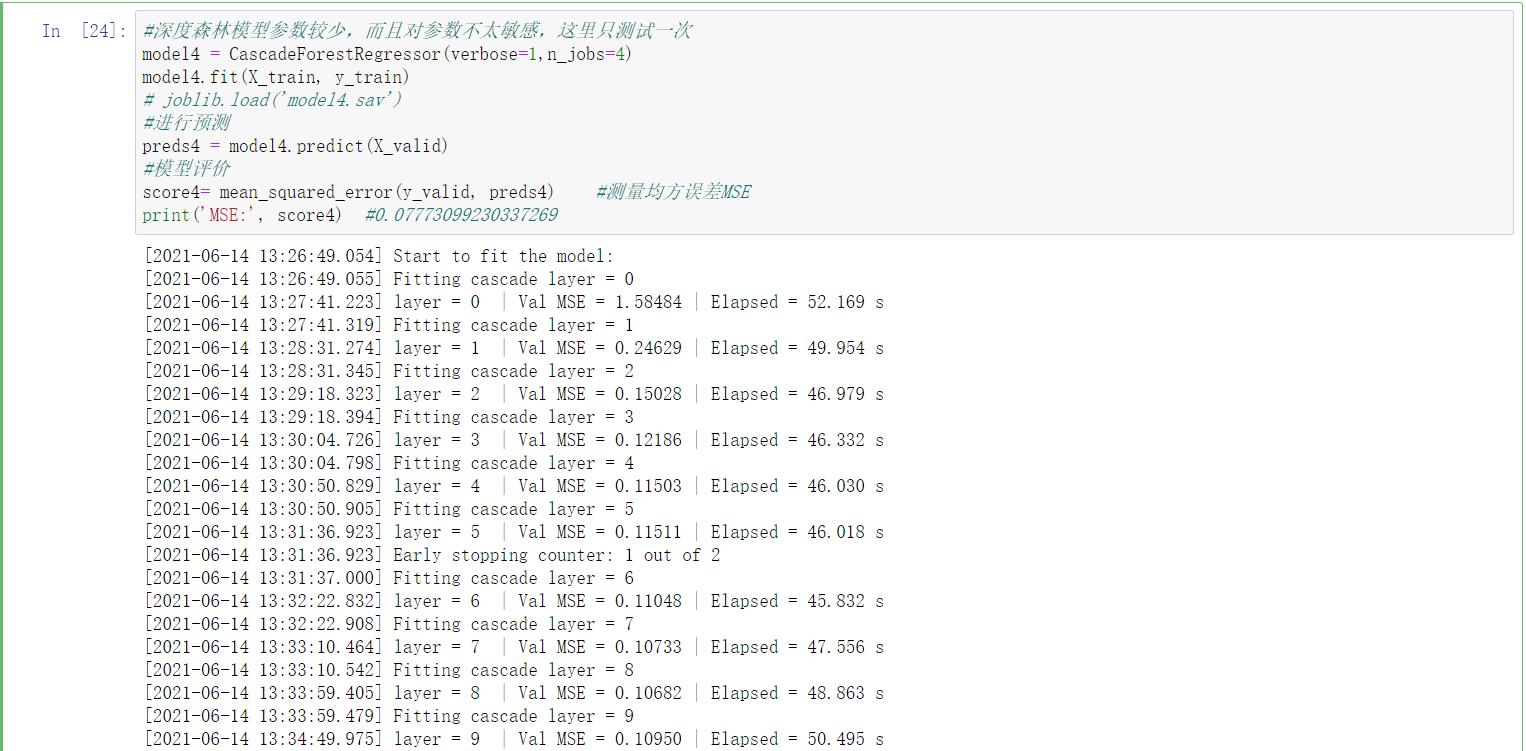
#深度森林模型参数较少,而且对参数不太敏感,这里只测试一次
model4 = CascadeForestRegressor(verbose=1,n_jobs=4)
model4.fit(X_train, y_train)
# joblib.load(\'model4.sav\')
#进行预测
preds4 = model4.predict(X_valid)
#模型评价
score4= mean_squared_error(y_valid, preds4) #测量均方误差MSE
print(\'MSE:\', score4) #0.07773099230337269
#神经网络
#失败品,MSE明显过大
model5= MLPRegressor(hidden_layer_sizes=300,max_iter=500,verbose=False) #默认隐藏层100
model5.fit(X_train, y_train)
# model5= joblib.load("model5.m")
#进行预测
preds5 = model5.predict(X_valid)
#模型评价
score5= mean_squared_error(y_valid, preds5) #测量均方误差MSE
print(\'MSE:\', score5) #18.98249967647298
#KNN回归 失败品 MAE明显过大
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor(n_neighbors=10)
my_pipeline_knn = Pipeline(steps=[(\'preprocessor\', preprocessor),
(\'model\', knn)
])
# Preprocessing of training data, fit model
my_pipeline_knn.fit(X_train, y_train)
# Preprocessing of validation data, get predictions
preds_knn = my_pipeline_knn.predict(X_valid)
# Evaluate the model
score = mean_absolute_error(y_valid, preds_knn)
print(\'MAE:\', score) #MAE 3.5145 耗时一节课
对于训练结果使用随机留空法取平均MSE进行评估。所有模型的结果如下:
| 模型 | 随机森林100棵树 | 随机森林200棵树 | XGBoost100个预测器 | XGBoost800个预测器 | 深度森林 | BP神经网络 |
|---|---|---|---|---|---|---|
| MSE | 0.0113 | 0.0116 | 0.0132 | 0.0092 | 0.0777 | 18.98 |
注:xgboost运行结果受计算机环境与性能影响,在电脑上的最好结果为0.0132与0.0092。
对于深度森林,其可调参数太少,而且其对参数不敏感,结果相对较差,不再对其进行探究。同时对于BP神经网络,其MSE太差,也不再对其进行优化。
以上是关于Python 机器学习避免碰撞课程设计的主要内容,如果未能解决你的问题,请参考以下文章