爬虫—lxml提取数据
Posted kannei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫—lxml提取数据相关的知识,希望对你有一定的参考价值。
我们好久不见~
来更新博客啦!最近在学爬虫,scrapy学不下去了,有点难搞啊,学点简单的吧哈哈哈哈
好啦,开始今天的分享~
首先得安装lxml库,pip install lxml
我们使用lxml库对html这样的字符串进行解析,将它还原为一个HTML页面,换句话说,Python里面的lxml库只做了这样一件事:将html字符串进行解析,供Xpath语法进行数据提取。
使用lxml中的etree对html进行处理,将它还原成网页

这里我们也需要先了解一下Xpath的知识,也很简单,我们通过一个具体的例子来演示一下
text = \\ """ <ul class="ullist" padding="1" spacing="1"> <li> <div id="top"> <span class="position" width="350">职位名称</span> <span>职位类别</span> <span>人数</span> <span>地点</span> <span>发布时间</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=33824&keywords=python&tid=87&lid=2218">python开发工程师</a> </span> <span>技术类</span> <span>2</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=29938&keywords=python&tid=87&lid=2218">python后端</a> </span> <span>技术类</span> <span>2</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=31236&keywords=python&tid=87&lid=2218">高级Python开发工程师</a> </span> <span>技术类</span> <span>2</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=31235&keywords=python&tid=87&lid=2218">python架构师</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=34531&keywords=python&tid=87&lid=2218">Python数据开发工程师</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=34532&keywords=python&tid=87&lid=2218">高级图像算法研发工程师</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=31648&keywords=python&tid=87&lid=2218">高级AI开发工程师</a> </span> <span>技术类</span> <span>4</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=32218&keywords=python&tid=87&lid=2218">后台开发工程师</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="even"> <span class="l square"> <a target="_blank" href="position_detail.php?id=32217&keywords=python&tid=87&lid=2218">Python开发(自动化运维方向)</a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> <div id="odd"> <span class="l square"> <a target="_blank" href="position_detail.php?id=34511&keywords=python&tid=87&lid=2218">Python数据挖掘讲师 </a> </span> <span>技术类</span> <span>1</span> <span>上海</span> <span>2018-10-23</span> </div> </li> </ul> """
以上这段是我们今天用到的例子,这是文本格式,以下围绕这个来展开
首先,我们要把他转换为HTML网页形式,那就需要用到etree函数了,使用etree之前需要先导包
from lxml import etree #解析为HTML html = etree.HTML(text) print(html)
这时候打印html会发现不是我们想要的结果:

因为HTML网页是不能直接打印出来的,我们需要把它转换为字符串然后进行输出
#如果想看到HTML里的内容需要转换为字符串类型并解码d = etree.tostring(html,encoding=\'utf8\').decode(\'utf8\')print(d)
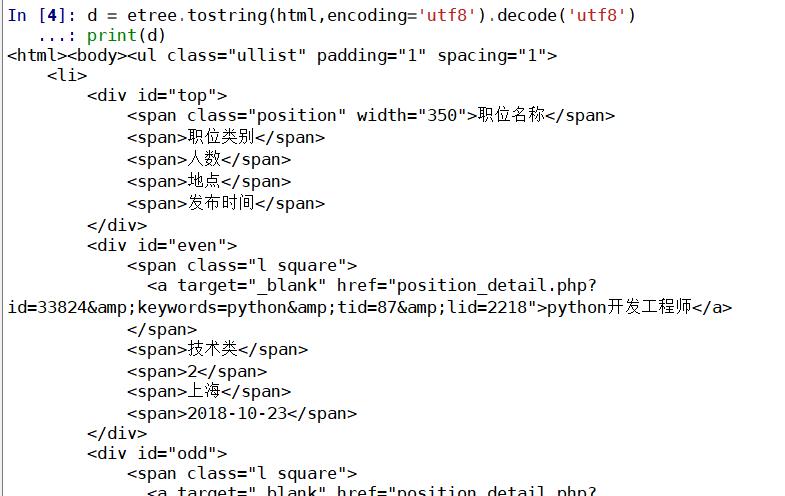
这时候输出的就是我们想看到的,所以如果想要看内容一定要进行上述转换
下面我们来提取一些信息,作为练习
####获取所有的div标签 divs = html.xpath(\'//div\') for div in divs: d = etree.tostring(div,encoding=\'utf8\').decode(\'utf8\') print(d) print(\'*\'*50) ####获取某个指定的div标签 div = html.xpath(\'//div[1]\') [0] print(etree.tostring(div,encoding=\'utf8\').decode(\'utf8\')) ####获取所有id="even"的div标签 divs = html.xpath(\'//div[@id="even"]\') for div in divs: d = etree.tostring(div,encoding=\'utf8\').decode(\'utf8\') print(d) print(\'*\'*50) ####获取所有div的id属性 ###/@可以用来获取属性的值 divs = html.xpath(\'//div/@id\') print(divs) ####获取所有a标签的href属性的值 hrefs = html.xpath(\'//a/@href\') print(hrefs)
经过上述练习,我们来提取一下div中的所有职位信息
####获取div里所有的职位信息 divs = html.xpath(\'//div\')[1:] works=[] for div in divs: work = {}#新建一个空字典 #获取href url = div.xpath(\'.//a/@href\')[0] #获取a标签的文本信息 position = div.xpath(\'.//a/text()\')[0] #获取工作类型 work_type = div.xpath(\'.//span[2]/text()\')[0] #获取职位人数 work_num = div.xpath(\'.//span[3]/text()\')[0] #获取工作地点 area = div.xpath(\'.//span[4]/text()\')[0] #获取发布时间 time = div.xpath(\'.//span[5]/text()\')[0] work = { "url":url, "position":position, "work_type":work_type, "work_num":work_num, "area":area, "time":time } works.append(work) print(works)
上述代码跑完会发现:

works里存放了所有的职位信息
好了,今天的分享结束啦,如果有xpath看不懂的可以留言哦~
以上是关于爬虫—lxml提取数据的主要内容,如果未能解决你的问题,请参考以下文章