我的爬虫随笔
Posted hearme
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我的爬虫随笔相关的知识,希望对你有一定的参考价值。
一.库安装
使用国内的豆瓣源
Beautiful Soup4库
pip3 install bs4 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
lxml库
pip3 install lxml -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
reques库
pip3 install requests -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
二.BS基本方法--find()和find_all()
1. find
只返回第一个匹配到的对象
语法:
find(name, attrs, recursive, text, **wargs)
# recursive 递归的,循环的
2. find_all
返回所有匹配到的结果,区别于find(find只返回查找到的第一个结果)
语法:
find_all(name, attrs, recursive, text, limit, **kwargs)
此篇较为详细
https://blog.csdn.net/weixin_42970378/article/details/83108206
三.简易流程
1.通过页面url下载html文本:
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"}
r = requests.get(url, headers=headers) # 增加headers, 模拟浏览器
return r.text
2.构建beautiful soup实例:
soup = BeautifulSoup(html, \'html.parser\')
3.利用find和findall得到想要的信息:
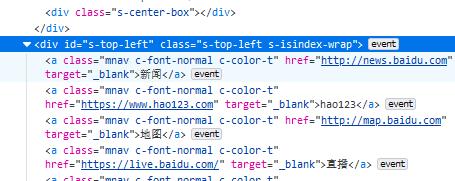
con = soup.find(id=\'s-top-left\') #找到左上角总框
con_list = con.find_all(\'a\', class_="mnav c-font-normal c-color-t") #将框内各元素存入列表
for i in con_list:#对框内每个元素循环
s=i.string
print(s)
以下代码得到了百度的左上角选项信息:

如图为html信息:
import requests from bs4 import BeautifulSoup def download_page(url): headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0"} r = requests.get(url, headers=headers) # 增加headers, 模拟浏览器 return r.text def get_content(html): soup = BeautifulSoup(html, \'html.parser\') con = soup.find(id=\'s-top-left\') #找到左上角总框 con_list = con.find_all(\'a\', class_="mnav c-font-normal c-color-t") #将框内各元素存入列表 for i in con_list:#对框内每个元素循环 s=i.string print(s) def main(): url = \'https://baidu.com/\' html = download_page(url) get_content(html) if __name__ == \'__main__\': main()
以上是关于我的爬虫随笔的主要内容,如果未能解决你的问题,请参考以下文章