技能篇:awk教程-linux命令
Posted 思君,亭亭而立
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技能篇:awk教程-linux命令相关的知识,希望对你有一定的参考价值。
前言
AWK是一门解释型的编程语言。用于文本处理,它的名字来源于它的三位作者的姓氏:Alfred Aho, Peter Weinberger 和 Brian Kernighan
- awk 程序结构
- 运行awk文件脚本
- awk基础语法
- awk 程序常用的内建变量
关注公众号,一起交流,微信搜一搜: 潜行前行
程序结构
awk命令模式:
awk \' BEGIN {awk-commands} /pattern/ {awk-commands} END {awk-commands}\' fileName- 若存在匹配模式pattern,则需要用 / 包含
- awk-commands 程序代码块必须被大括号
- BEGIN语句块
BEGIN {awk-commands},可选,它只执行一次,在这里可以初始化变量。BEGIN是AWK的关键字,必须为大写 - BODY 语句块
/pattern/ {awk-commands},BODY语句块中的命令会对输入的每一行执行,可以通过提供模式来控制这种行为 - END 语句块
END {awk-commands},可选,END语句块在程序的最后执行,END是AWK的关键字,必须为大写
awk工作流程
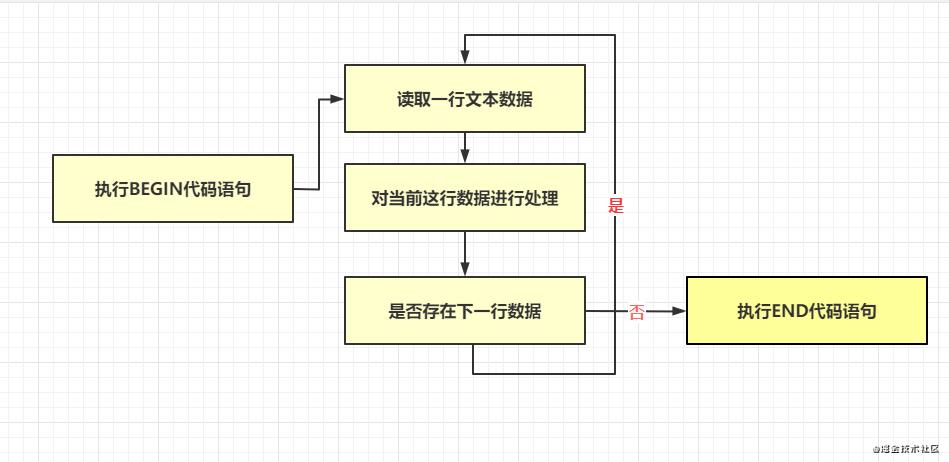
BODY语句块执行解析
脚本命令: awk \'{ [代码语句1][代码语句2] };如果没有 fileName 或其他输入流,且存在BODY语句块,BODY语句块会进入死循环;代码语句表达式以分号结束,也可以用换行符结束
- 1: 读入一行数据,并这一行的数据填入 $0;每一列的数据分别填入 $1, $2.... 等变量当中
- 2: 执行 代码语句
- 3: 若还有后续的行数据,则重复上面 1~2 的步骤,直到每一数据都读完为止
运行awk文件脚本
- awk文件脚本以awk后缀结尾
- 选项 [-f]:
awk -f command.awk marks.txt
awk基础语法
- awk变量不需要提前定义,也不许要指定类型
awk \'BEGIN{sum=1;print sum}\'
1
- 流程控制
#-------- 伪代码 1 ---------
if ({condition})
代码逻辑...
else if({condition})
代码逻辑...
else
代码逻辑...
#-------- 伪代码 2 ---------
for ({初始化}; {condition};{后续逻辑}){
代码逻辑...
}
#-------- 伪代码 3 ---------
while ({condition}){
代码逻辑...
}
#-------- 伪代码 4 ---------
do{
代码逻辑...
}while ({condition})
- 运算符,基本和 java 编程语言一样 下面简单列举几个运算符
| 符号 | 说明 | 示例 |
|---|---|---|
| ^ | 指数操作符 | a = a ^ 2 |
| -/+ | 一元操作符 | a = -10; a = +a; |
| condition ? action : action | 三元操作符 | (a > b) ? max = a : max = b; |
| && / || | 逻辑操作符 | if (num >= 0 && num <= 7) |
| == / != | 等于不等于 | if (a == b) |
awk \'BEGIN{sum=1;sum++; if(sum==2) print sum}\'
2
- 数组,AWK支持关联数组,也就是说,不仅可以使用数字索引的数组,还可以使用字符串作为索引;删除数组元素使用delete语句
delete arr[0]
$ awk \'BEGIN {arr["lwl"] = 1; arr["csc"] = 2; for (i in arr) printf "arr[%s] = %d\\n", i, arr[i]}\'
arr[lwl] = 1
arr[csc] = 2
- 字符串操作
---- 空格拼接字符,则默认使用逗哈作为拼接符 ----
awk \'BEGIN { str1 = "csc, "; str2 = "lwl"; str3 = str1 str2; print str3 }\'
csc, lwl
- 字符串相关的内建函数
index(str, sub) #获取sub在str起始索引
length(str) #获取str长度
match(str, regex) #str是否匹配regex模式
split(str, arr, regex)
sub(regex, sub, string)
substr(str, start, l)
tolower(str)
toupper(str)
正则表达式
- 匹配符:~ 和 !~ 分别代表匹配和不匹配
$ awk \'$0 !~ 9\' marks.txt
1) Amit Physics 80
3) Shyam Biology 87
- 匹配符和正则表达式
# log.txt内容文件
1 csc world
2 lwl hello
----------输出第二列包含lwl的行------------------------------
$ awk \'$2 ~ /lwl/ {print $2,$3}\' log.txt
lwl hello
------输出包含csc的行---------------------------
$ awk \'/csc/ {print $0}\' log.txt
1 csc world
awk 程序常用的内建变量
| 变量 | 描述 |
|---|---|
| $n | 当前记录的第n个字段,字段间由FS分隔 |
| $0 | 完整的输入记录 |
| ARGC | 命令行参数的数目 |
| ARGV | 包含命令行参数的数组 |
| ENVIRON | 环境变量 |
| ERRNO | 最后一个系统错误的描述 |
| FILENAME | 当前文件名 |
| FS | 字段分隔符(默认是任何空格) |
| IGNORECASE | 进行忽略大小写的匹配 |
| NF | 一条记录的字段的数目 |
| NR | 已经读出的记录数,就是行号,从1开始 |
| FNR | 和NR类似,不过如果存在多个输入文件,FNR当前文件的行号 |
| OFS | 输出 字段分隔符 |
| ORS | 输出 行分隔符 |
| RLENGTH | 由match函数所匹配的字符串的长度 |
| RS | 记录分隔符(默认是一个换行符) |
| RSTART | 由match函数所匹配的字符串的第一个位置 |
| ARGIND | 循环处理数据时,当前被处理的ARGV的索引 |
| PROCINFO | 包含进程信息的关联数组,例如UID,进程ID等 |
- ARGV 命令行参数个数
$ awk \'BEGIN {
for (i = 0; i < ARGC - 1; ++i) {
printf "ARGV[%d] = %s\\n", i, ARGV[i]
}
}\' csc lwl
ARGV[0] = csc
ARGV[1] = lwl
- ENVIRON 环境变量
$ awk \'BEGIN { print ENVIRON["USER"] }\'
csc
- FILENAME 当前文件名
$ awk \'END {print FILENAME}\' test.txt
test.txt
- RSTART,由match函数所匹配的字符串的第一个位置
$ awk \'BEGIN { if (match("One Two Three", "Thre")) { print RSTART } }
9
欢迎指正文中错误
参考文章
以上是关于技能篇:awk教程-linux命令的主要内容,如果未能解决你的问题,请参考以下文章