Mongodb的ReplicaSet实验
Posted Tung Note
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mongodb的ReplicaSet实验相关的知识,希望对你有一定的参考价值。
Mongodb的ReplicaSet实验
标签(空格分隔): MongoDB
本文验证了:要保证mongodb RS集群在宕机情况下的可用性,至少需要三台机器。
目的
本实验的ReplicaSet集群为 1*Primary, 1*Secondary, n*Arbiter。
目的是为了验证:
- 三机环境下,Primary宕机后,是否能通过Aribiter进行auto-failover。
- 两台机器环境下,能否保证一台机器宕机后,仍然保证可用。一台Primary,一台Secondary+Arbiter。或者一台Primary+Arbiter,一台Secondary+Arbiter。
三机环境搭建
使用docker快速生成三个容器模拟三台主机。

| Name | Port | Role(Experted) |
|---|---|---|
| mongo-c1 | 37017 | Primary |
| mongo-c2 | 47017 | Secondary |
| mongo-c3 | 57017 | Arbiter |
在发生故障,且mongo数据节点不能够自身选举出Primary的时候,就需要Arbiter节点介入了,(否则不介入)。
集群配置
添加replSetName
修改三个节点中的配置文件
replication:
replSetName: rep1
重启各个节点
初始化集群
获取各个节点docker容器IP(docker inspect),这里采用宿主机IP和映射端口。
通过客户端连接到任何一个节点。
./mongo
输入:
rs.initiate({
_id:"rep1",members:[
{_id:1,host:"192.16.8.105:37017", priority:10},
{_id:2,host:"192.16.8.105:47017", priority:5},
{_id:3,host:"192.16.8.105:57017", arbiterOnly:true}
]
})
之后将会返回响应:
{ "ok" : 1 }
通过rs.status();命令可以看到集群状态

故障演练
通过直接关闭Primary所在的容器,来观察Secondary的角色变化。
关闭Primary
docker stop mongo-c1
关闭后通过rs.status()查看,发现mongo已经auto-failover了。
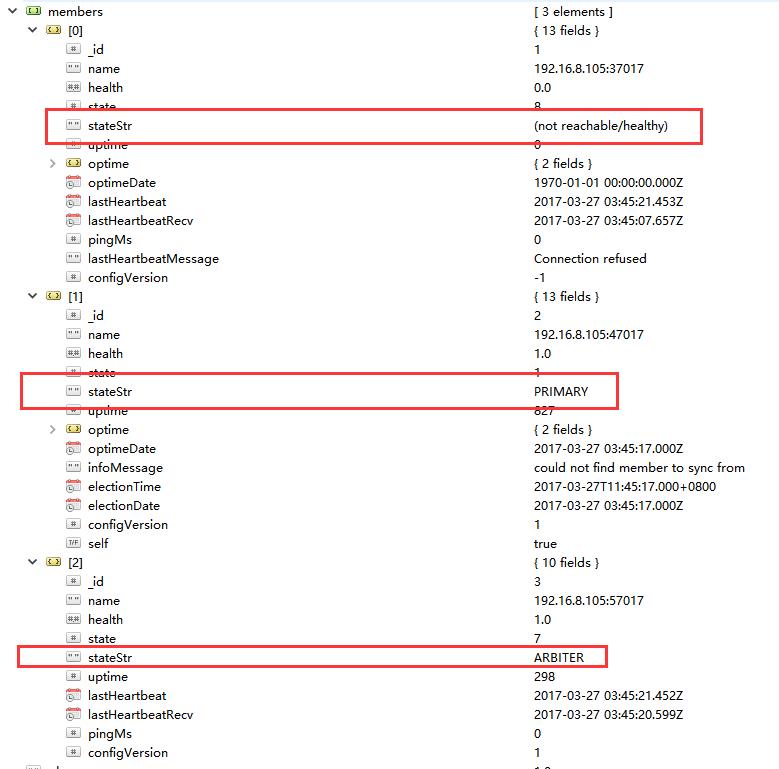
重新启动Primary容器
发现该节点作为Secondary加入。
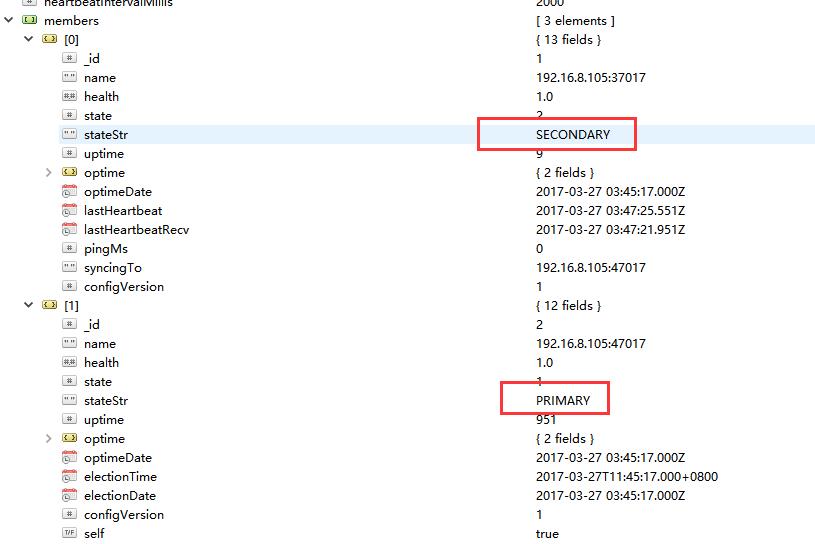
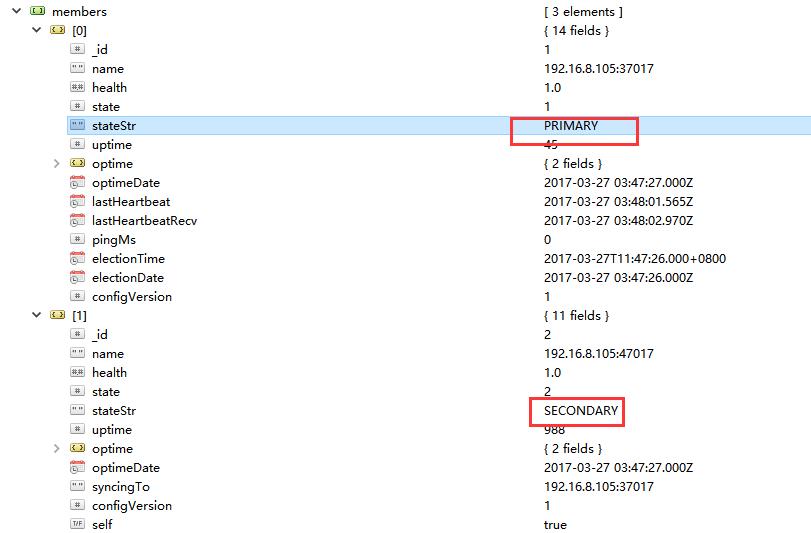
等待一会,发现该节点又变为了Primary。
关闭Secondary
可正常工作。
关闭Arbiter
节点状态无影响,可正常工作。
关闭Secondary和Arbiter
原Primary变为Secondary,无法正常工作。
双机环境(1)(1+1)方案
通过docker,重新生成两个容器模拟两个主机。
| Name | Port | Role(Experted) |
|---|---|---|
| mongo-c1 | 37017 | Primary |
| mongo-c2 | 47017 | Secondary |
| mongo-c2 | 57017 | Arbiter |
也就是在Secondary机器上运行一个Aribiter实例即可。
docker run -d -p 37017:27017 --name mongo-c1 tung/mongo:1.0
docker run -d -p 47017:27017 -p 57017:27018 --name mongo-c2 tung/mongo:1.0
设置replSetName
replication:
replSetName: rep1
配置Arbiter节点
复制一份mongod.conf为mongod2.conf
修改里面的日志路径,数据路径(预先mkdir),端口27018,pid文件路径
/opt/mongo/bin/mongod -f /opt/mongod.conf
/opt/mongo/bin/mongod -f /opt/mongod2.conf
故障演练
关闭Secondary+Arbiter
关闭后,Primary变为了Secondary。无法工作。
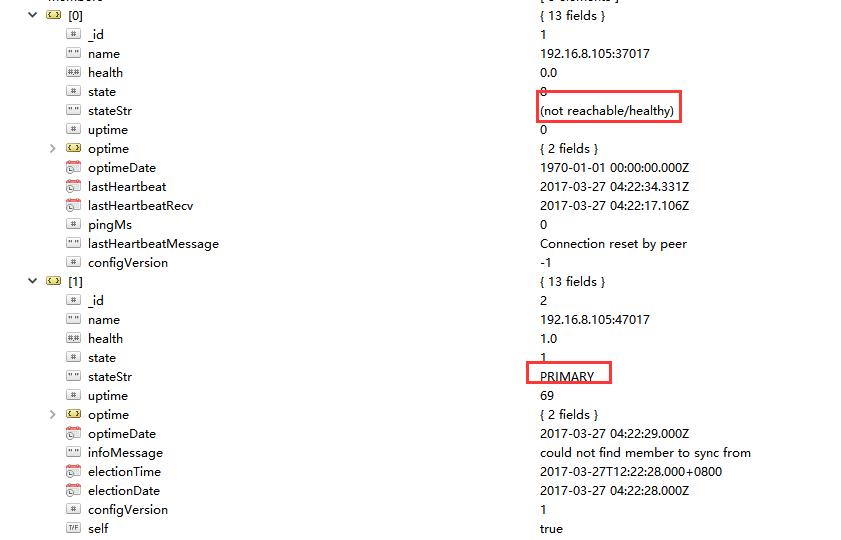
关闭Primary
能够进行auto-failover,可正常工作。
双机环境(1+1)(1+1)方案
1Primary 1Secondary 2*Arbiter
| Name | Port | Role(Experted) |
|---|---|---|
| mongo-c1 | 27017 | Primary |
| mongo-c1 | 37017 | Arbiter |
| mongo-c2 | 47017 | Secondary |
| mongo-c2 | 57017 | Arbiter |
初始化命令:
rs.initiate({
_id:"rep1",members:[
{_id:1,host:"192.16.8.105:27017", priority:10},
{_id:2,host:"192.16.8.105:37017", arbiterOnly:true},
{_id:3,host:"192.16.8.105:47017", priority:5},
{_id:4,host:"192.16.8.105:57017", arbiterOnly:true}
]
})
关闭Arbiter
关闭一个Arbiter, 数据节点没有影响,可正常工作。
再关闭一个Arbiter,也就是关闭所有Arbiter, 数据节点全部变为Secondary,无法正常工作。
关闭Secondary
没有影响,可正常工作。
关闭Secondary+Arbiter
Primary变为Secondary.哪怕仍然有一个Arbiter存活,无法正常工作。
关闭Primary
Secondary进行auto-failover。可正常工作。
结论
在双机环境下,应该无法保证宕机时的HA。至少需要三机。

以上是关于Mongodb的ReplicaSet实验的主要内容,如果未能解决你的问题,请参考以下文章
helm安装mongodb-replicaset遇到的坑及解决方法
关于MongoDb Replica Set的故障转移集群——实战篇
从 Kubernetes 集群中的另一个服务连接到 MongoDB Ops Manager 上的 ReplicaSet,给出 MongooseServerSelectionError