MySQL MHA部署与测试-MySQL 8.0.20-mha4mysql-0.58版本
Posted Serverless和DevOps技术分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL MHA部署与测试-MySQL 8.0.20-mha4mysql-0.58版本相关的知识,希望对你有一定的参考价值。
mysql MHA部署与测试-上篇
1、介绍
1.1 简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司的youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件
1.2 主要特性
MHA的主要特征:
- 从
master的监控到故障转移全部都能自动完成,故障转移也可以手动执行 - 可在秒级单位内实现故障转移
- 可将任意
slave提升到master - 具备在多个点上调用外部脚本(扩展)的技能,可以用在电源
OFF或者IP地址的故障转移上 - 安装和卸载不用停止当前的
mysql进程 MHA自身不会增加服务器负担,不会降低性能,不用追加服务器- 不依赖
Storage Engine - 不依赖二进制文件的格式(不论是
statement模式还是Row模式) - 针对
OS挂掉的故障转移,检测系统是否挂掉需要10秒,故障转移仅需4秒
1.3 组成结构
manager 组件
masterha_manger # 启动MHA
masterha_check_ssh # 检查MHA的SSH配置状况
masterha_check_repl # 检查MySQL复制状况,配置信息
masterha_master_monitor # 检测master是否宕机
masterha_check_status # 检测当前MHA运行状态
masterha_master_switch # 控制故障转移(自动或者手动)
masterha_conf_host # 添加或删除配置的server信息
node 组件
save_binary_logs # 保存和复制master的二进制日志
apply_diff_relay_logs # 识别差异的中继日志事件并将其差异的事件应用于其他的
purge_relay_logs # 清除中继日志(不会阻塞SQL线程)
2、MHA部署
2.1 环境准备
2.1.1 拓扑
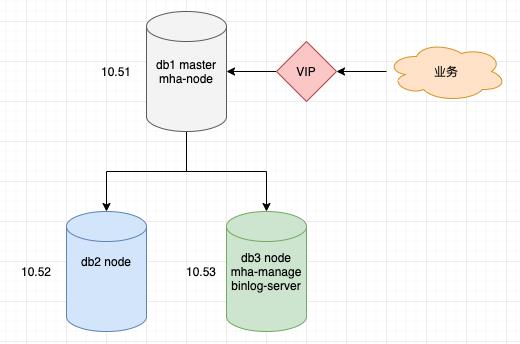
2.1.2 环境准备
需准备Linux环境Mysql1主2从环境,本次部署具体使用软件版本情况如下
操作系统:Linux CentOS 7.6
数据库:MySQL 8.0.20
MHA:mha4mysql-0.58
2.2 环境部署
2.2.1 安装操作系统
操作系统版本:Linux CentOS 7.6
主机名及ip:
db1:192.168.10.51,db2:192.168.10.52,db3:192.168.10.53
2.2.2 安装数据库
分别在三台服务器安装MySQL 8.0.20数据库
配置文件如下:
[mysqld]
user=mysql
basedir=/usr/local/mysql
datadir=/data/3306/data
socket=/tmp/mysql.sock
gtid-mode=on # gtid开关
enforce-gtid-consistency=true # 强制GTID一致
log-slave-updates=1 # 从库强制更新binlog日志
log_bin = mysql-bin
binlog_format = mixed
expire_logs_days = 15
log-error=/data/3306/data/mysql_error.log
server-id = 51 # server-id 三台不同 ,db2为52,db3为53
default_authentication_plugin=mysql_native_password #修改密码加密方式
[mysql]
socket=/tmp/mysql.sock
2.2.3 搭建主从环境
搭建主从环境,确认1主2从运行正常
2.3 MHA部署
2.3.1 节点互信
db01
rm -rf /root/.ssh
ssh-keygen
ssh-copy-id 192.168.10.51
ssh-copy-id 192.168.10.52
ssh-copy-id 192.168.10.53
db02
ssh-keygen
ssh-copy-id 192.168.10.51
ssh-copy-id 192.168.10.52
ssh-copy-id 192.168.10.53
db03
ssh-keygen
ssh-copy-id 192.168.10.51
ssh-copy-id 192.168.10.52
ssh-copy-id 192.168.10.53
2.3.2 下载软件
mkdir -p /data/tools/ && cd /data/tools
wget https://qiniu.wsfnk.com/mha4mysql-node-0.58-0.el7.centos.noarch.rpm --no-check-certificate
wget https://qiniu.wsfnk.com/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm --no-check-certificate
2.3.3 创建软连接
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
2.3.4 安装软件
安装node软件(mha的manager软件是依赖于node软件运行的,所以需要先安装node端)
db1-db3
yum install perl-DBD-MySQL -y
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
安装manager
db3
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
yum install -y mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
2.3.5 创建用户
在db1主库中创建mha用户,此用户用于mha用来确认各节点存活状态、binlog_server拉去binlog日志。
(mysql 8.0之后版本需要单独创建用户后授权。注意密码加密方式)
create user mha@\'192.168.10.%\' identified by \'mha\';
grant all privileges on *.* to mha@\'192.168.10.%\';
2.3.6 创建相关目录
db3
#创建配置文件目录
mkdir -p /etc/mha
#创建日志目录
mkdir -p /var/log/mha/app1
2.3.7 manager配置文件
db3
cat > /etc/mha/app1.cnf <<eof [server="" default]="" manager_log="/var/log/mha/app1/manager" #="" mha的工作日志设置="" manager_workdir="/var/log/mha/app1" mha工作目录="" master_binlog_dir="/data/3306/data" 主库的binlog目录="" user="mha" 监控用户="" password="mha" 监控密码="" ping_interval="2" 心跳检测的间隔时间="" repl_password="123" 复制用户="" repl_user="rep" 复制密码="" ssh_user="root" ssh互信的用户="" [server1]="" 节点信息....="" hostname="192.16.10.51" port="3306" [server2]="" candidate_master="1" 被选主="" [server3]="" no_master="1" 不参与选主="" eof="" ```="" ####="" 2.3.8="" 检查状态="" db3="" ```shell="" 检查ssl互通情况="" [root@db3="" ~]#="" vim="" etc="" mha="" app1.cnf="" masterha_check_ssh="" --conf="/etc/mha/app1.cnf" ...="" tue="" jun="" 1="" 17:01:47="" 2021="" -="" [info]="" all="" ssh="" connection="" tests="" passed="" successfully.="" 检查="" mha配置文件="" masterha_check_repl="" mysql="" replication="" health="" is="" not="" ok!="" 2.3.9="" 启动manager服务="" db03="" nohup="" masterha_manager="" --remove_dead_master_conf="" --ignore_last_failover="" <="" dev="" null=""> /var/log/mha/app1/manager.log 2>&1 &
[1] 4406
--conf=/etc/mha/app1.cnf # 指定配置文件
--remove_dead_master_conf # 剔除已经死亡的节点
--ignore_last_failover # 默认不能短时间(8小时)多次切换,此参数跳过检查
2.3.10 查看mha运行状态
[root@db3 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:4406) is running(0:PING_OK), master:192.168.10.51
3、vip、故障提醒、binlog_server
master_ip_failover # vip故障转移脚本
send_report # 故障提醒脚本
3.1 vip 功能部署
vip(eth0:1)网卡日常绑定在主库的网卡上,如主库出现错误导致mha重新选主,也会跟随移动到新主库的网卡上。所以要求各mha节点网卡名称一致
vip网段要求与各节点均在同一网段内
vip实现脚本是根据源码perl脚本重新编写master_ip_failover
3.1.1 准备脚本
#!/usr/bin/env perl
use strict;
use warnings FATAL => \'all\';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = \'192.168.10.49/24\';
my $key = \'1\';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
my $ssh_Bcast_arp= "/sbin/arping -I eth0 -c 3 -A 192.168.10.49";
GetOptions(
\'command=s\' => \\$command,
\'ssh_user=s\' => \\$ssh_user,
\'orig_master_host=s\' => \\$orig_master_host,
\'orig_master_ip=s\' => \\$orig_master_ip,
\'orig_master_port=i\' => \\$orig_master_port,
\'new_master_host=s\' => \\$new_master_host,
\'new_master_ip=s\' => \\$new_master_ip,
\'new_master_port=i\' => \\$new_master_port,
);
exit &main();
sub main {
print "\\n\\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\\n\\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \\n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \\n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\\@$new_master_host \\" $ssh_start_vip \\"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\\@$orig_master_host \\" $ssh_stop_vip \\"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\\n";
}
3.1.2 修改脚本
脚本中以下部分按照要求修改
vim /usr/local/bin/master_ip_failover
my $vip = \'192.168.10.49/24\'; # vip网段,与各节点服务器网段一致。
my $key = \'1\'; # 虚拟网卡eth0:1 的 1
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; # 网卡按照实际网卡名称填写
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; # 网卡按照实际网卡名称填写
my $ssh_Bcast_arp= "/sbin/arping -I eth0 -c 3 -A 192.168.10.49"; # 重新声明mac地址,arp
3.1.3 上传脚本并授权
\\cp -a * /usr/local/bin # 上传脚本文件到/usr/local/bin
chmod +x /usr/local/bin/* # 给脚本增加执行权限
dos2unix /usr/local/bin/* # 处理脚本中的中文字符
3.1.4 修改manager配置文件
在配置文件中增加vip故障转移部分
vim /etc/mha/app1.cnf
master_ip_failover_script=/usr/local/bin/master_ip_failover
3.1.5 重启mha
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
3.1.6 在主库db1增加vip
ifconfig eth0:1 192.168.10.49/24
3.2 故障提醒功能部署
3.2.1 准备脚本
#!/usr/bin/perl
use strict;
use warnings FATAL => \'all\';
use Mail::Sender;
use Getopt::Long;
#new_master_host and new_slave_hosts are set only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body );
my $smtp=\'smtp.qq.com\';
my $mail_from=\'xxxxxx@qq.com\';
my $mail_user=\'xxxxx\';
my $mail_pass=\'xxxxxx\';
#my $mail_to=[\'to1@qq.com\',\'to2@qq.com\'];
my $mail_to=\'xxxxxx@qq.com\';
GetOptions(
\'orig_master_host=s\' => \\$dead_master_host,
\'new_master_host=s\' => \\$new_master_host,
\'new_slave_hosts=s\' => \\$new_slave_hosts,
\'subject=s\' => \\$subject,
\'body=s\' => \\$body,
);
# Do whatever you want here
mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body);
sub mailToContacts {
my ($smtp, $mail_from, $mail_user, $mail_pass, $mail_to, $subject, $msg ) = @_;
open my $DEBUG, ">/tmp/mail.log"
or die "Can\'t open the debug file:$!\\n";
my $sender = new Mail::Sender {
ctype => \'text/plain;charset=utf-8\',
encoding => \'utf-8\',
smtp => $smtp,
from => $mail_from,
auth => \'LOGIN\',
TLS_allowed => \'0\',
authid => $mail_user,
authpwd => $mail_pass,
to => $mail_to,
subject => $subject,
debug => $DEBUG
};
$sender->MailMsg(
{
msg => $msg,
debug => $DEBUG
}
) or print $Mail::Sender::Error;
return 1;
}
exit 0;
修改以下部分为个人邮箱内容
#new_master_host and new_slave_hosts are set only when recovering master succeeded
my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body );
my $smtp=\'smtp.qq.com\'; # 发件服务器
my $mail_from=\'xxxxxx@qq.com\'; # 发件地址
my $mail_user=\'xxxxx\'; # 发件用户名
my $mail_pass=\'xxxxxx\'; # 发件邮箱密码
my $mail_to=\'xxxxxx@qq.com\'; # 收件地址
#my $mail_to=[\'to1@qq.com\',\'to2@qq.com\']; # 可设置收件邮箱群组
3.2.2 修改manager配置文件
vim /etc/mha/app1.cnf
# 添加一行:
report_script=/usr/local/bin/send_report
3.2.3 重启mha
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
3.3 binlog_server搭建
binlog_server功能主要是实时拉去主库binlog进行存储,如果主库出现宕机,mha切换主从时,通过binlog_server服务器拿取bin_log日志对新主库进行数据补偿,实现日志补偿冗余
3.3.1 创建相关目录
mkdir -p /data/binlog_server/ # binlog_server存储目录
chown -R mysql.mysql /data/* # 授权
3.3.2 开启binlog_server服务
cd /data/binlog_server/ # 进入binlog_server存储目录
mysql -e "show slave status \\G"|grep "Master_Log" # 确认当前slave的io进程拉取的日志量
## 启动binlog日志拉取守护进程
mysqlbinlog -R --host=192.168.10.51 --user=mha --password=mha --raw --stop-never mysql-bin.000004 & # 注意:拉取日志的起点,需要按照目前从库的已经获取到的二进制日志点为起点
3.3.3 修改manager配置文件
增加以下内容
vim /etc/mha/app1.cnf
[binlog1]
no_master=1
hostname=192.168.10.53
master_binlog_dir=/data/binlog_server/
3.3.4 重启mha
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
4、MHA工作原理介绍
4.1 主要工作流程介绍
- 1、启动MHA-manager
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
- 2、监控
/usr/bin/masterha_master_monitor # 每隔ping_interval秒探测1次,连续4次还没有,说明主库宕机。
- 3、选主
根据各项参数选择新主 - 4、数据补偿
对新主的数据差异进行补偿。 - 5、切换
所有从库解除主从身份。stop slave ; reset slave;
重构新的主从关系。change master to - 6、迁移vip
将vip网卡(eth0:1)绑定至新主服务器。 - 7、故障提醒
发送故障提醒邮件 - 8、额外数据补偿
根据binlog_server 服务器进行额外数据补偿 - 9、剔除故障节点
将故障的主服务器剔除mha环境(配置文件删除) - 10、manager程序“自杀
4.2 mha选主策略
4.2.1 选主依据
1、日志量latest
选取获取binlog最多的slave节点,为latest节点
[root@db3 ~]# mysql -uroot -p123456 -e "show slave status\\G" |grep Master_Log
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 196
Relay_Master_Log_File: mysql-bin.000005
Exec_Master_Log_Pos: 196
2、备选主pref
manager配置文件中指定了candidate_master=1参数
[server2]
hostname=192.168.10.52
port=3306
candidate_master=1 # 备选主
3、不被选主
配置文件中设置no_master=1
[server3]
no_master=1 # 不被选
hostname=192.168.10.53
port=3306
二进制日志没开log_bin
如果从库落后主库100M的日志量(可以关闭) check_slave_delay
4.2.2 节点数组
| alive | 存活 |
|---|---|
| latest | 日志最新 |
| perf | 被选 |
| bad | 不选 |
4.2.3 选主判断
从上至下按条件依次筛选,上条不符合才会选择下一条
1、没有pref和bad,就选latest第一个(根据配置文件server1-2-3)
2、即是latest又是perf,又不是bad
3、perf和latest,都不是bad,选perf
4、第3条也可能选latest,如perf差100M以上binlog
5、如果以上条件都不满足,且只有一个salve可选,则选择此slave
6、没有符合的slave,则选主失败,failover失败
4.3 数据补偿
4.3.1 原主库ssh可连接
各个从节点调用: save_binary_logs脚本,立即保存缺失部分的binlog到各自节点/var/tmp目录
4.3.2 原主库ssh不能连接
从节点调用apply_diff_relay_logs,进行relay-log日志差异补偿
4.3.3 额外数据补偿(主库日志冗余机制)
binlog_server实现数据补偿
MySQL MHA部署与测试-下篇
1、故障测试
1.1 操作流程
# 追踪mha-manager日志
[root@db03 ~]# tail -f /var/log/mha/app1/manager
# 关闭主库
[root@db01 ~]# /etc/init.d/mysqld stop
1.2 日志查看
# 确认主库宕机部分
Wed Jun 2 16:55:42 2021 - [warning] Got error on MySQL select ping: 1053 (Server shutdown in progress)
Wed Jun 2 16:55:42 2021 - [info] Executing SSH check script: exit 0
Wed Jun 2 16:55:42 2021 - [info] HealthCheck: SSH to 192.168.10.51 is reachable.
Wed Jun 2 16:55:44 2021 - [warning] Got error on MySQL connect: 2003 (Can\'t connect to MySQL server on \'192.168.10.51\' (111))
Wed Jun 2 16:55:44 2021 - [warning] Connection failed 2 time(s)..
Wed Jun 2 16:55:46 2021 - [warning] Got error on MySQL connect: 2003 (Can\'t connect to MySQL server on \'192.168.10.51\' (111))
Wed Jun 2 16:55:46 2021 - [warning] Connection failed 3 time(s)..
Wed Jun 2 16:55:48 2021 - [warning] Got error on MySQL connect: 2003 (Can\'t connect to MySQL server on \'192.168.10.51\' (111))
Wed Jun 2 16:55:48 2021 - [warning] Connection failed 4 time(s)..
Wed Jun 2 16:55:48 2021 - [warning] Master is not reachable from health checker!
Wed Jun 2 16:55:48 2021 - [warning] Master 192.168.10.51(192.168.10.51:3306) is not reachable!
# 确认各节点状态
Wed Jun 2 16:55:48 2021 - [warning] SSH is reachable.
Wed Jun 2 16:55:48 2021 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/mha/app1.cnf again, and trying to connect to all servers to check server status..
Wed Jun 2 16:55:48 2021 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Wed Jun 2 16:55:48 2021 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Wed Jun 2 16:55:48 2021 - [info] Reading server configuration from /etc/mha/app1.cnf..
Wed Jun 2 16:55:49 2021 - [info] GTID failover mode = 1
Wed Jun 2 16:55:49 2021 - [info] Dead Servers:
Wed Jun 2 16:55:49 2021 - [info] 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:49 2021 - [info] Alive Servers:
Wed Jun 2 16:55:49 2021 - [info] 192.168.10.52(192.168.10.52:3306)
Wed Jun 2 16:55:49 2021 - [info] 192.168.10.53(192.168.10.53:3306)
Wed Jun 2 16:55:49 2021 - [info] Alive Slaves:
Wed Jun 2 16:55:49 2021 - [info] 192.168.10.52(192.168.10.52:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:49 2021 - [info] GTID ON
Wed Jun 2 16:55:49 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:49 2021 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Jun 2 16:55:49 2021 - [info] 192.168.10.53(192.168.10.53:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:49 2021 - [info] GTID ON
Wed Jun 2 16:55:49 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:49 2021 - [info] Not candidate for the new Master (no_master is set)
Wed Jun 2 16:55:49 2021 - [info] Checking slave configurations..
Wed Jun 2 16:55:49 2021 - [info] read_only=1 is not set on slave 192.168.10.52(192.168.10.52:3306).
Wed Jun 2 16:55:49 2021 - [info] read_only=1 is not set on slave 192.168.10.53(192.168.10.53:3306).
Wed Jun 2 16:55:49 2021 - [info] Checking replication filtering settings..
Wed Jun 2 16:55:49 2021 - [info] Replication filtering check ok.
Wed Jun 2 16:55:49 2021 - [info] Master is down!
Wed Jun 2 16:55:49 2021 - [info] Terminating monitoring script.
Wed Jun 2 16:55:49 2021 - [info] Got exit code 20 (Master dead).
Wed Jun 2 16:55:49 2021 - [info] MHA::MasterFailover version 0.58.
Wed Jun 2 16:55:49 2021 - [info] Starting master failover.
Wed Jun 2 16:55:49 2021 - [info]
Wed Jun 2 16:55:49 2021 - [info] * Phase 1: Configuration Check Phase..
Wed Jun 2 16:55:49 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] GTID failover mode = 1
Wed Jun 2 16:55:51 2021 - [info] Dead Servers:
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Checking master reachability via MySQL(double check)...
Wed Jun 2 16:55:51 2021 - [info] ok.
Wed Jun 2 16:55:51 2021 - [info] Alive Servers:
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.52(192.168.10.52:3306)
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.53(192.168.10.53:3306)
Wed Jun 2 16:55:51 2021 - [info] Alive Slaves:
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.52(192.168.10.52:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:51 2021 - [info] GTID ON
Wed Jun 2 16:55:51 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.53(192.168.10.53:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:51 2021 - [info] GTID ON
Wed Jun 2 16:55:51 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Not candidate for the new Master (no_master is set)
Wed Jun 2 16:55:51 2021 - [info] Starting GTID based failover.
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] ** Phase 1: Configuration Check Phase completed.
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] * Phase 2: Dead Master Shutdown Phase..
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] Forcing shutdown so that applications never connect to the current master..
Wed Jun 2 16:55:51 2021 - [info] Executing master IP deactivation script:
Wed Jun 2 16:55:51 2021 - [info] /usr/local/bin/master_ip_failover --orig_master_host=192.168.10.51 --orig_master_ip=192.168.10.51 --orig_master_port=3306 --command=stopssh --ssh_user=root
# VIP状态检查,日志补偿(此部分未发现日志缺失)
IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.10.49/24===
Disabling the VIP on old master: 192.168.10.51
SIOCSIFFLAGS: Cannot assign requested address
Wed Jun 2 16:55:51 2021 - [info] done.
Wed Jun 2 16:55:51 2021 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Wed Jun 2 16:55:51 2021 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] * Phase 3: Master Recovery Phase..
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] The latest binary log file/position on all slaves is mysql-bin.000005:196
Wed Jun 2 16:55:51 2021 - [info] Latest slaves (Slaves that received relay log files to the latest):
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.52(192.168.10.52:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:51 2021 - [info] GTID ON
Wed Jun 2 16:55:51 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.53(192.168.10.53:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:51 2021 - [info] GTID ON
Wed Jun 2 16:55:51 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Not candidate for the new Master (no_master is set)
Wed Jun 2 16:55:51 2021 - [info] The oldest binary log file/position on all slaves is mysql-bin.000005:196
Wed Jun 2 16:55:51 2021 - [info] Oldest slaves:
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.52(192.168.10.52:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:51 2021 - [info] GTID ON
Wed Jun 2 16:55:51 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.53(192.168.10.53:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:51 2021 - [info] GTID ON
Wed Jun 2 16:55:51 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Not candidate for the new Master (no_master is set)
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] * Phase 3.3: Determining New Master Phase..
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] Searching new master from slaves..
Wed Jun 2 16:55:51 2021 - [info] Candidate masters from the configuration file:
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.52(192.168.10.52:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:51 2021 - [info] GTID ON
Wed Jun 2 16:55:51 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Jun 2 16:55:51 2021 - [info] Non-candidate masters:
Wed Jun 2 16:55:51 2021 - [info] 192.168.10.53(192.168.10.53:3306) Version=8.0.20 (oldest major version between slaves) log-bin:enabled
Wed Jun 2 16:55:51 2021 - [info] GTID ON
Wed Jun 2 16:55:51 2021 - [info] Replicating from 192.168.10.51(192.168.10.51:3306)
Wed Jun 2 16:55:51 2021 - [info] Not candidate for the new Master (no_master is set)
Wed Jun 2 16:55:51 2021 - [info] Searching from candidate_master slaves which have received the latest relay log events..
# 选主结束,开始切换
Wed Jun 2 16:55:51 2021 - [info] New master is 192.168.10.52(192.168.10.52:3306)
Wed Jun 2 16:55:51 2021 - [info] Starting master failover..
Wed Jun 2 16:55:51 2021 - [info]
From:
192.168.10.51(192.168.10.51:3306) (current master)
+--192.168.10.52(192.168.10.52:3306)
+--192.168.10.53(192.168.10.53:3306)
To:
192.168.10.52(192.168.10.52:3306) (new master)
+--192.168.10.53(192.168.10.53:3306)
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] * Phase 3.3: New Master Recovery Phase..
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] Waiting all logs to be applied..
Wed Jun 2 16:55:51 2021 - [info] done.
Wed Jun 2 16:55:51 2021 - [info] Getting new master\'s binlog name and position..
Wed Jun 2 16:55:51 2021 - [info] mysql-bin.000005:196
Wed Jun 2 16:55:51 2021 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=\'192.168.10.52\', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=\'rep\', MASTER_PASSWORD=\'xxx\';
Wed Jun 2 16:55:51 2021 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: mysql-bin.000005, 196, f4682075-c1b9-11eb-86b2-000c2934cc5a:1-21
Wed Jun 2 16:55:51 2021 - [info] Executing master IP activate script:
Wed Jun 2 16:55:51 2021 - [info] /usr/local/bin/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.10.51 --orig_master_ip=192.168.10.51 --orig_master_port=3306 --new_master_host=192.168.10.52 --new_master_ip=192.168.10.52 --new_master_port=3306 --new_master_user=\'mha\' --new_master_password=xxx
Unknown option: new_master_user
Unknown option: new_master_password
# 切换vip,处理manager配置文件(将db1踢出mha环境)
IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.10.49/24===
Enabling the VIP - 192.168.10.49/24 on the new master - 192.168.10.52
Wed Jun 2 16:55:51 2021 - [info] OK.
Wed Jun 2 16:55:51 2021 - [info] ** Finished master recovery successfully.
Wed Jun 2 16:55:51 2021 - [info] * Phase 3: Master Recovery Phase completed.
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] * Phase 4: Slaves Recovery Phase..
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] * Phase 4.1: Starting Slaves in parallel..
Wed Jun 2 16:55:51 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] -- Slave recovery on host 192.168.10.53(192.168.10.53:3306) started, pid: 48882. Check tmp log /var/log/mha/app1/192.168.10.53_3306_20210602165549.log if it takes time..
Wed Jun 2 16:55:53 2021 - [info]
Wed Jun 2 16:55:53 2021 - [info] Log messages from 192.168.10.53 ...
Wed Jun 2 16:55:53 2021 - [info]
Wed Jun 2 16:55:51 2021 - [info] Resetting slave 192.168.10.53(192.168.10.53:3306) and starting replication from the new master 192.168.10.52(192.168.10.52:3306)..
Wed Jun 2 16:55:51 2021 - [info] Executed CHANGE MASTER.
Wed Jun 2 16:55:52 2021 - [info] Slave started.
Wed Jun 2 16:55:52 2021 - [info] gtid_wait(f4682075-c1b9-11eb-86b2-000c2934cc5a:1-21) completed on 192.168.10.53(192.168.10.53:3306). Executed 0 events.
Wed Jun 2 16:55:53 2021 - [info] End of log messages from 192.168.10.53.
Wed Jun 2 16:55:53 2021 - [info] -- Slave on host 192.168.10.53(192.168.10.53:3306) started.
Wed Jun 2 16:55:53 2021 - [info] All new slave servers recovered successfully.
Wed Jun 2 16:55:53 2021 - [info]
Wed Jun 2 16:55:53 2021 - [info] * Phase 5: New master cleanup phase..
Wed Jun 2 16:55:53 2021 - [info]
Wed Jun 2 16:55:53 2021 - [info] Resetting slave info on the new master..
Wed Jun 2 16:55:53 2021 - [info] 192.168.10.52: Resetting slave info succeeded.
Wed Jun 2 16:55:53 2021 - [info] Master failover to 192.168.10.52(192.168.10.52:3306) completed successfully.
Wed Jun 2 16:55:53 2021 - [info] Deleted server1 entry from /etc/mha/app1.cnf .
Wed Jun 2 16:55:53 2021 - [info]
# 切换完成
----- Failover Report -----
app1: MySQL Master failover 192.168.10.51(192.168.10.51:3306) to 192.168.10.52(192.168.10.52:3306) succeeded
Master 192.168.10.51(192.168.10.51:3306) is down!
Check MHA Manager logs at db3:/var/log/mha/app1/manager for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 192.168.10.51(192.168.10.51:3306)
Selected 192.168.10.52(192.168.10.52:3306) as a new master.
192.168.10.52(192.168.10.52:3306): OK: Applying all logs succeeded.
192.168.10.52(192.168.10.52:3306): OK: Activated master IP address.
192.168.10.53(192.168.10.53:3306): OK: Slave started, replicating from 192.168.10.52(192.168.10.52:3306)
192.168.10.52(192.168.10.52:3306): Resetting slave info succeeded.
Master failover to 192.168.10.52(192.168.10.52:3306) completed successfully.
2、主动切换
故障后进行主动切换,查看主从状态和vip环境确认
主库已切换至db2
[root@db3 ~ ]# mysql -uroot -p123456 -e "show slave status\\G;" |grep Master_Host
mysql: [Warning] Using a password on the command line interface can be insecure.
Master_Host: 192.168.10.52 # 主库已变更
vip`已切换至`db2
[root@db2 ~]# ip a |grep eth0
2: eth0: <broadcast,multicast,up,lower_up> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.10.52/24 brd 192.168.10.255 scope global noprefixroute eth0
inet 192.168.10.49/24 brd 192.168.10.255 scope global secondary eth0:1
3、在线切换
3.1 只切换角色
3.1.1 切换命令
masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=192.168.10.51 --orig_master_is_new_slave --running_updates_limit=10000
master_ip_online_change_script is not defined. If you do not disable writes on the current master manually, applications keep writing on the current master. Is it ok to proceed? (yes/NO): yes
# 命令解析
--conf=/etc/mha/app1.cnf # 指定配置文件
--master_state=alive # 主库在线的情况下进行切换
--new_master_host=192.168.10.51 # 指定新主ip
--orig_master_is_new_slave # 原主库改为从库
running_updates_limit=10000 # 网络延时(ping值)超过1w毫秒不进行切换
3.1.2 注意内容
此命令一般不会在生产环境使用,只用于测试
1、需要关闭mha-manager,不然切换无法执行成功。报错如下:
Tue Jun 8 10:03:54 2021 - [error][/usr/share/perl5/vendor_perl/MHA/MasterRotate.pm, ln143] Getting advisory lock failed on the current master. MHA Monitor runs on the current master. Stop MHA Manager/Monitor and try again.
Tue Jun 8 10:03:54 2021 - [error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln177] Got ERROR: at /usr/bin/masterha_master_switch line 53.
2、需要将原主库锁住Flush table with read lock,使其只读。因为在切换完主从后,vip尚未切换,此段时间数据还会写入到原主库,导致数据不一致。警告如下:
It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 192.168.10.52(192.168.10.52:3306)? (YES/no): yes
3、需要手工切换vip
4、需要重新拉取主库binlog(binlog-server)
3.2 脚本功能实现
功能: 在线切换时,自动锁原主库,VIP自动切换
3.2.1 准备脚本
vim /usr/local/bin/master_ip_online_change
#!/usr/bin/env perl
use strict;
use warnings FATAL => \'all\';
use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
use Time::HiRes qw( sleep gettimeofday tv_interval );
use Data::Dumper;
my $_tstart;
my $_running_interval = 0.1;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user,
);
###########################################################################
my $vip = "10.0.0.55";
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key $vip down";
my $ssh_Bcast_arp= "/sbin/arping -I ens33 -c 3 -A 10.0.0.55";
###########################################################################
GetOptions(
\'command=s\' => \\$command,
\'orig_master_is_new_slave\' => \\$orig_master_is_new_slave,
\'orig_master_host=s\' => \\$orig_master_host,
\'orig_master_ip=s\' => \\$orig_master_ip,
\'orig_master_port=i\' => \\$orig_master_port,
\'orig_master_user=s\' => \\$orig_master_user,
\'orig_master_password=s\' => \\$orig_master_password,
\'orig_master_ssh_user=s\' => \\$orig_master_ssh_user,
\'new_master_host=s\' => \\$new_master_host,
\'new_master_ip=s\' => \\$new_master_ip,
\'new_master_port=i\' => \\$new_master_port,
\'new_master_user=s\' => \\$new_master_user,
\'new_master_password=s\' => \\$new_master_password,
\'new_master_ssh_user=s\' => \\$new_master_ssh_user,
);
exit &main();
sub current_time_us {
my ( $sec, $microsec ) = gettimeofday();
my $curdate = localtime($sec);
return $curdate . " " . sprintf( "%06d", $microsec );
}
sub sleep_until {
my $elapsed = tv_interval($_tstart);
if ( $_running_interval > $elapsed ) {
sleep( $_running_interval - $elapsed );
}
}
sub get_threads_util {
my $dbh = shift;
my $my_connection_id = shift;
my $running_time_threshold = shift;
my $type = shift;
$running_time_threshold = 0 unless ($running_time_threshold);
$type = 0 unless ($type);
my @threads;
my $sth = $dbh->prepare("SHOW PROCESSLIST");
$sth->execute();
while ( my $ref = $sth->fetchrow_hashref() ) {
my $id = $ref->{Id};
my $user = $ref->{User};
my $host = $ref->{Host};
my $command = $ref->{Command};
my $state = $ref->{State};
my $query_time = $ref->{Time};
my $info = $ref->{Info};
$info =~ s/^\\s*(.*?)\\s*$/$1/ if defined($info);
next if ( $my_connection_id == $id );
next if ( defined($query_time) && $query_time < $running_time_threshold );
next if ( defined($command) && $command eq "Binlog Dump" );
next if ( defined($user) && $user eq "system user" );
next
if ( defined($command)
&& $command eq "Sleep"
&& defined($query_time)
&& $query_time >= 1 );
if ( $type >= 1 ) {
next if ( defined($command) && $command eq "Sleep" );
next if ( defined($command) && $command eq "Connect" );
}
if ( $type >= 2 ) {
next if ( defined($info) && $info =~ m/^select/i );
next if ( defined($info) && $info =~ m/^show/i );
}
push @threads, $ref;
}
return @threads;
}
sub main {
if ( $command eq "stop" ) {
## Gracefully killing connections on the current master
# 1. Set read_only= 1 on the new master
# 2. DROP USER so that no app user can establish new connections
# 3. Set read_only= 1 on the current master
# 4. Kill current queries
# * Any database access failure will result in script die.
my $exit_code = 1;
eval {
## Setting read_only=1 on the new master (to avoid accident)
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error(die_on_error)_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
print current_time_us() . " Set read_only on the new master.. ";
$new_master_handler->enable_read_only();
if ( $new_master_handler->is_read_only() ) {
print "ok.\\n";
}
else {
die "Failed!\\n";
}
$new_master_handler->disconnect();
# Connecting to the orig master, die if any database error happens
my $orig_master_handler = new MHA::DBHelper();
$orig_master_handler->connect( $orig_master_ip, $orig_master_port,
$orig_master_user, $orig_master_password, 1 );
## Drop application user so that nobody can connect. Disabling per-session binlog beforehand
$orig_master_handler->disable_log_bin_local();
print current_time_us() . " Drpping app user on the orig master..\\n";
###########################################################################
#FIXME_xxx_drop_app_user($orig_master_handler);
###########################################################################
## Waiting for N * 100 milliseconds so that current connections can exit
my $time_until_read_only = 15;
$_tstart = [gettimeofday];
my @threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_read_only > 0 && $#threads >= 0 ) {
if ( $time_until_read_only % 5 == 0 ) {
printf
"%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\\n",
current_time_us(), $#threads + 1, $time_until_read_only * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_read_only--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Setting read_only=1 on the current master so that nobody(except SUPER) can write
print current_time_us() . " Set read_only=1 on the orig master.. ";
$orig_master_handler->enable_read_only();
if ( $orig_master_handler->is_read_only() ) {
print "ok.\\n";
}
else {
die "Failed!\\n";
}
## Waiting for M * 100 milliseconds so that current update queries can complete
my $time_until_kill_threads = 5;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {
if ( $time_until_kill_threads % 5 == 0 ) {
printf
"%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\\n",
current_time_us(), $#threads + 1, $time_until_kill_threads * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_kill_threads--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
###########################################################################
print "disable the VIP on old master: $orig_master_host \\n";
&stop_vip();
###########################################################################
## Terminating all threads
print current_time_us() . " Killing all application threads..\\n";
$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 );
print current_time_us() . " done.\\n";
$orig_master_handler->enable_log_bin_local();
$orig_master_handler->disconnect();
## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
## Activating master ip on the new master
# 1. Create app user with write privileges
# 2. Moving backup script if needed
# 3. Register new master\'s ip to the catalog database
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
## Set read_only=0 on the new master
$new_master_handler->disable_log_bin_local();
print current_time_us() . " Set read_only=0 on the new master.\\n";
$new_master_handler->disable_read_only();
## Creating an app user on the new master
print current_time_us() . " Creating app user on the new master..\\n";
###########################################################################
#FIXME_xxx_create_app_user($new_master_handler);
###########################################################################
$new_master_handler->enable_log_bin_local();
$new_master_handler->disconnect();
## Update master ip on the catalog database, etc
###############################################################################
print "enable the VIP: $vip on the new master: $new_master_host \\n ";
&start_vip();
###############################################################################
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
# do nothing
exit 0;
}
else {
&usage();
exit 1;
}
}
###########################################################################
sub start_vip() {
`ssh $new_master_ssh_user\\@$new_master_host \\" $ssh_start_vip \\"`;
}
sub stop_vip() {
`ssh $orig_master_ssh_user\\@$orig_master_host \\" $ssh_stop_vip \\"`;
}
###########################################################################
sub usage {
print
"Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\\n";
die;
}
根据自身环境修改以下内容(与vip脚本设置一致)
my $vip = \'192.168.10.49/24\'; # vip网段,与各节点服务器网段一致。
my $key = \'1\'; # 虚拟网卡eth0:1 的 1
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; # 网卡按照实际网卡名称填写
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; # 网卡按照实际网卡名称填写
my $ssh_Bcast_arp= "/sbin/arping -I eth0 -c 3 -A 192.168.10.49"; # 重新声明mac地址,arp
3.2.2 mha配置文件
修改mha-manager配置文件,增加一下内容
vim /etc/mha/app1.cnf
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
3.2.3 关停mha服务
masterha_stop --conf=/etc/mha/app1.cnf
3.2.4 检查repl
masterha_check_repl --conf=/etc/mha/app1.cnf
3.2.5 在线切换
masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=192.168.10.51 --orig_master_is_new_slave --running_updates_limit=10000
From:
192.168.10.52(192.168.10.52:3306) (current master)
+--192.168.10.51(192.168.10.51:3306)
+--192.168.10.53(192.168.10.53:3306)
To:
192.168.10.51(192.168.10.51:3306) (new master)
+--192.168.10.53(192.168.10.53:3306)
+--192.168.10.52(192.168.10.52:3306)
Tue Jun 8 10:44:10 2021 - [info] Switching master to 192.168.10.51(192.168.10.51:3306) completed successfully. # 切换成功
3.2.6 确认vip
[root@db1 ~]# ip a |grep eth0
2: eth0: <broadcast,multicast,up,lower_up> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.10.51/24 brd 192.168.10.255 scope global noprefixroute eth0
inet 192.168.10.49/24 brd 192.168.10.255 scope global secondary eth0:1
3.2.7 重构binlog-server
1、查询当前salve当前拿取的binlog日志
[root@db3 ~]# mysql -uroot -p123456 -e "show slave status \\G"|grep "Master_Log"
Master_Log_File: mysql-bin.000006
Read_Master_Log_Pos: 196
Relay_Master_Log_File: mysql-bin.000006
Exec_Master_Log_Pos: 196
2、关停当前binlog-server服务,清除binlog-server目录里拉取的日志文件
[root@db03 bin]# ps -ef |grep mysqlbinlog
root 28144 16272 0 17:50 pts/1 00:00:00 mysqlbinlog -R --host=192.168.10.52 --user=mha --password=x x --raw --stop-never mysql-bin.000005
root 28529 16272 0 18:03 pts/1 00:00:00 grep --color=auto mysqlbinlog
[root@db03 bin]# kill -9 28144
[root@db03 bin]# cd /data/binlog_server/
[root@db03 binlog_server]# ll
total 4
-rw-r----- 1 root root 194 Apr 1 17:50 mysql-bin.000005
[root@db03 binlog_server]# rm -rf *
[1] 28534
3、进入日志目录,重新启动binlog-server守护进程
[root@db03 bin]# cd /data/binlog_server/
[root@db03 binlog_server]# mysqlbinlog -R --host=192.168.10.51 --user=mha --password=mha --raw --stop-never mysql-bin.000009 &
3.2.8 重新启动mha
[root@db03 bin]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
[root@db03 binlog_server]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:28535) is running(0:PING_OK), master:192.168.10.51
</broadcast,multicast,up,lower_up></broadcast,multicast,up,lower_up>
以上是关于MySQL MHA部署与测试-MySQL 8.0.20-mha4mysql-0.58版本的主要内容,如果未能解决你的问题,请参考以下文章