spark
Posted 千面鬼手大人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark相关的知识,希望对你有一定的参考价值。
分析计算
hadoop都是计算框架
spark是基于流处理,内存
Mockup
hadoop 不适合循环迭代数据流处理 IO会频繁
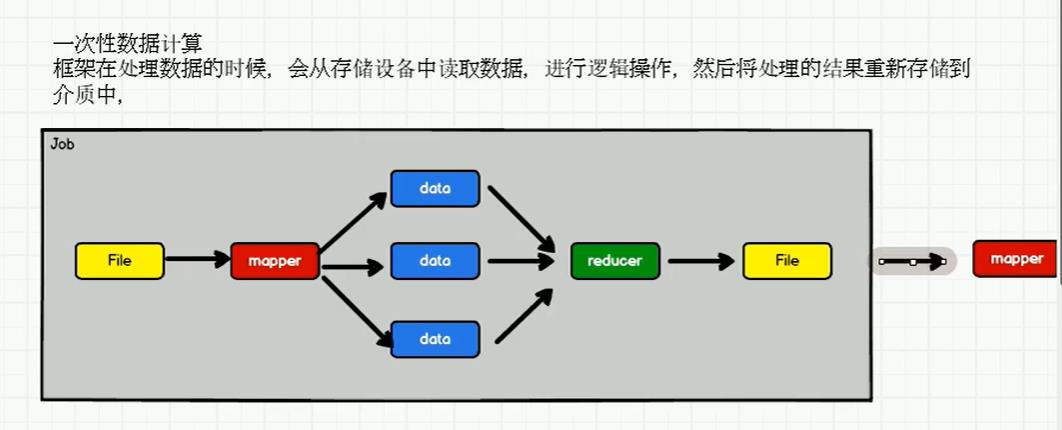
spark,memory会快一些,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型。
可以支持 复杂的数据挖掘算法和 图形计算算法
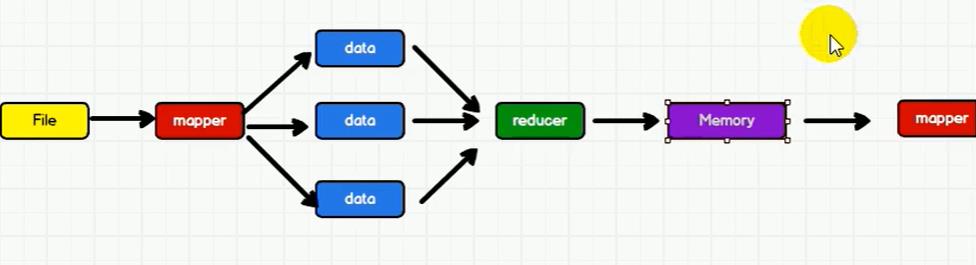
Spark和Hadoop的根本差异是多个作业之间的数据通信问题:
Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘。
Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式。
Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互
Spark的缓存机制比HDFS的缓存机制高效。
由于内存资源不够导致Job执行失败,此时,MapReduce其实是一个更好的选择,所以Spark并不能完全替代MR.
spark核心模块
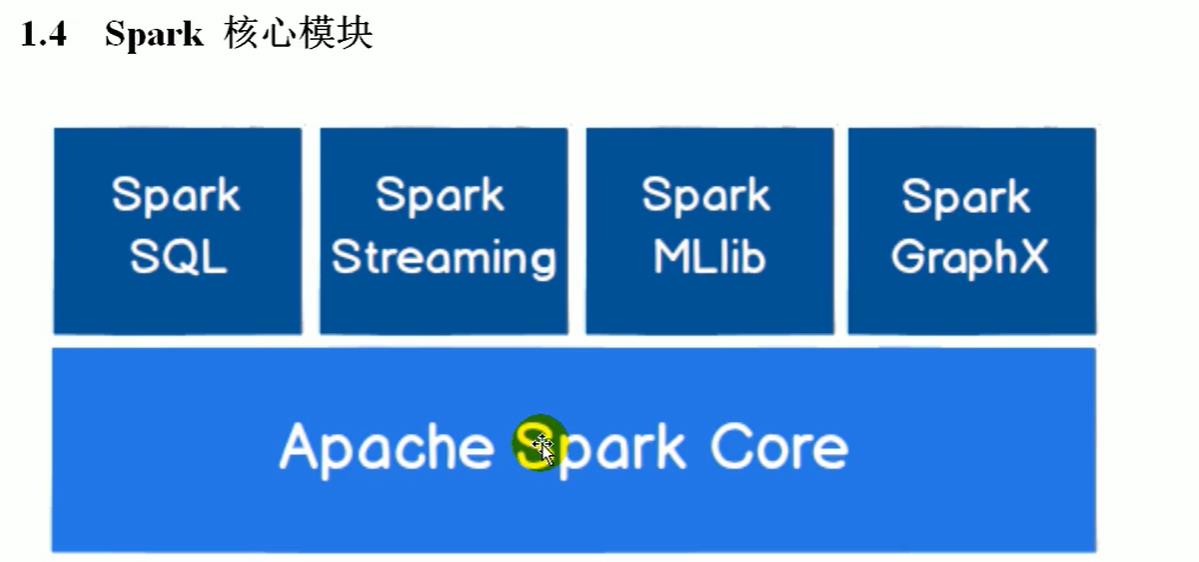
Spark MLlib 机器学习
以上是关于spark的主要内容,如果未能解决你的问题,请参考以下文章