企业如何高效用云?| 资深运维架构师细说云架构下的运维体系构建
Posted 弹性计算百晓生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了企业如何高效用云?| 资深运维架构师细说云架构下的运维体系构建相关的知识,希望对你有一定的参考价值。
5 月 29 日,阿里云开发者大会的《基础设施的云上管控》分论坛上,Mobvista 资深运维架构师于龙水发表了主题为《云架构下的运维体系构建》的演讲,详细阐述了如何高效地用云以及云上成本优化的五个方向。

Mobvista 资深运维架构师于龙水
本文根据于龙水的演讲整理成文。
为什么要用云?
首先来看一个比较简单的云的原生态架构。相较于传统 IDC 来说,云计算的架构有五大特点:

1. 开发要求变高。上云需考虑单机能力、请求能力、负载能力和转发能力。
2. 服务器数量变化。云上资源可以自由地弹性伸缩,资源不再固定,这对运维人员挑战很高。
3. 资源利用率高。云计算平台最大的特点是高弹性,能根据用户需求提供云资源,提升整体资源利用率。
4. 业务增长不受限。上云后,可以灵活地使用云资源,随时调整云的使用量。不论是当前的业务,还是未来的业务都不受资源限制。
5. 安全性高。像阿里云的公有云,都有一套内置的安全方案。只要用云,就可以免费使用这套安全方案。在云上,安全方案会提醒 DDoS 的触发时间、处理情况与结果。所以,安全性会相应提高。
如何高效地用云为企业服务?
既然相比 IDC,上云更符合企业发展方向,那如何高效地使用云为企业服务?
用云的最常用思路

考虑到每家业务的特殊性,先来看看用云的最常用思路。
1. 先配 VPC。通常网络配置里包含了 VPC 和 Subnet 的选择。
公有云的 Subnet 跟它的可用区有关,一个 Subnet 对应一个可用区。Subnet 需要关联什么样的网关,也都要进行统一设计。
这里,最容易让人忽略的是,设计 Subnet 时 IP 预留不足会导致后续资源在扩容时机器无法铺开。
2. 选择计算资源。注意规划好是否需具备弹性与伸缩能力。
公有云平台的实例计费方式是多样的,比如阿里云平台上有包年、包月、按需和抢占式。采用一种多比例的分配,才能既达到资源的高利用率又享受到低成本。做计算资源时也要计划好负载,云平台一般都会提供相应的负载,像 SLB 或 ELB 等。
3. 存储资源意识。存储资源用的好,可能比计算资源要节省的多。
4. 权限配管。在公有云里,权限配管涉及两个部分:
1. 用户可以申请一个权限对云资源进行操作;
二是资源的 RAM,作为一个用户可以去控制资源,这很容易理解。但很少人理解,可以用一个资源控制一个资源,但这非常有必要。
举一个例子:我有一台 ECS 机器,想操作一个 RDS 或 OSS。我只需要把权限给这个 ECS 即可,不用暴露任何的 access key,只需要从后台授权给他某一个 OSS 或者某一个资源的权限。这部分是很多人会忽略的或不愿去配的,但却相对来说更安全。
监控要有一定的智能化
接着我们来看看智能监控,监控主要分为资源、业务和应用三层。

第一,资源层。如 CPU 情况、内存、磁盘、IO、网络流量,这些属于云平台的底层资源,监控好资源状态情况,可以保证资源的稳定运行。
第二,业务层。深入业务内的监控项,比如广告业务会监控召回量、日志情况和广告返回延迟等,保证业务异常能及时捕获并处理。
第三,应用层。只需看应用本身的状态,如端口监控、服务存活等,保证资源正常情况下、应用是正常提供服务的。
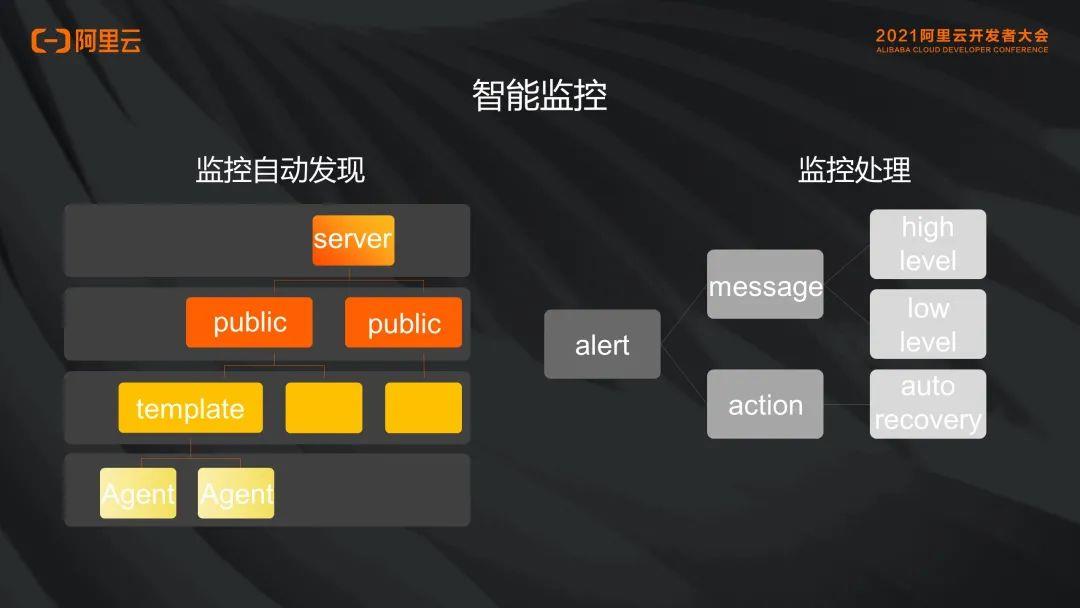
做好监控以后,一定要让这个监控有一定的智能化。监控智能化主要体现在让不同组的机器去监控不同组的项目,这样新起的机器才能进行分组、分类的监控。
在创建监控的云服务器时,会有多个 public 的 template,大家都会用的 CPU、内存、磁盘 IO 等属于公共类,然后基于 public、再根据不同的业务内容创建专有的 template。基于专有的 template,最后是云主机、Agent,Agent 会自动关联不同的 template,这样一组机器都是基于同一个 template 做的监控,最终形成一个比较完善的体系。
监控报警的升级
有了监控就需要进行监控的报警,报警分为两类:
一类如 sent message。有 high level 和 low level 两种情况。
另一类,报警升级情况。比如 5 分钟报警情况下是一个 low level,超过 15 分钟 low level 可以升级为 middle level 或 high level,同时可以扩大报警人的范围。
其中,有一部分服务是可以自动恢复的,那就无需发信息,自己恢复即可。这就涉及一些 action,action 里面要具备一些像 auto recovery 的功能。
运维自动化之工具、发版和部署
云上自动化的必要性要比 IDC 强烈的多,因为云上资源比 IDC 复杂太多,而且机器的数量多、种类会更多一些。怎么做运维自动化管理呢?运维人员可以自己开发或者借助云平台提供的自动化工具来实现。

三个运维自动化工具
云平台会提供一些自动化工具,包括各类语言的 SDK 和 CLI 等工具,其中 CLI 是一种命令行的工具,通常运维人员在用命令行的时候是大部分开发人员不能比拟的,运维人员可以用 CLI 的形式来实现部分自动化工作。
同时,云平台还提供了元组数据,提供一个专有的 IP 接口,你在本机上调 IP 接口时,会看到本机上的信息,包括 instance ID、public IP、网卡信息,你可以利用这些信息去做一些事情。
既然用上了工具,就可以进行自动化的管理。
通常情况下,最多用的是如何执行批量、怎么去归组。建立好相应的 CMDB,是所有资源的核心,一定要在 CMDB 里面才能对所有资源核心进行管理。CMDB 的建立有两个提示:
1. 通常云平台会将资源信息提供在 SDK 里,可以直接查询它相应的实例信息,然后将它写入 CMDB。这个方法方式有很多种, Github 开源里面有好多别人已经写好的,你直接调就行了。
2. 尽量选用 Go 语言做 CMDB 的开发, Go 语言的并发能力和亲和性相对来说好很多;Python 的话,并发性比较差,调用 CMDB 接口等待时间比较长。有了 CMDB 后,当用 Ansible 或 salt 调机器时,可以从 CMDB 里进行一些分类归组处理。
运维自动化——发版
相应的 CMDB 创建好了,批量工具也已经做好了,做好批量工具,后面是常规的操作发版。相信每个运维人员都会面临发版的问题,在云发版的情况下,这地方就很有意思了。
假如说,发版的情况下恰好遇到有机器起来了,起来的机器那些发版内容到底是最新的还是旧的?
我提供几个处理技巧。

在发版时因为有版本控制,有的是 gitlab 或 SVN。在发版时,预先将第一份发到一个固定路径,可以是 OSS 或其他托管类目。放到 OSS 下,这是发第一份。发完以后,通过批量工具发你现有的线上当前存活的机器量所有的版本。
这时候如果触发自动伸缩,进行扩容机器时,这时扩容的机器可以在启动时直接从固定路径拉最新的代码,这保证了不论是扩容还是主动发版的内容都保持最新版本。
再看自动化监控,这里指自动注册与自动解注册。由于云的不固定性,可能遇到扩容时机器创建了。作为监控人员不能手动配置把它加到监控里,延时也不固定,在晚上也无法及时处理,所以一定要具备自动监控能力。
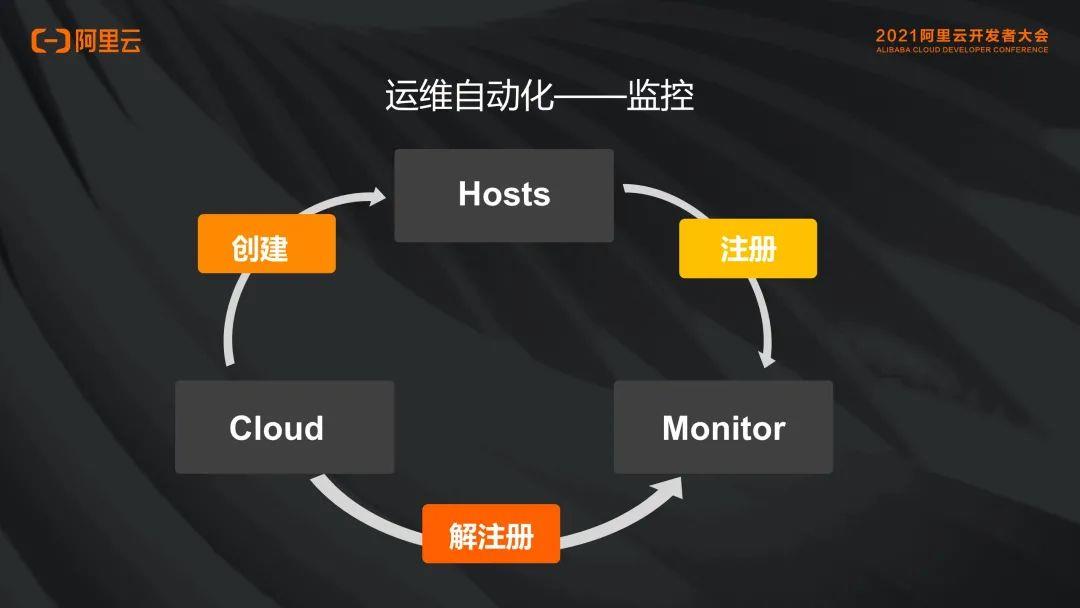
- 自动注册:像最常用的 Zabbix,在启动 agent 时必须要自动注册,注册自己的内容。配置如 matadata,把特征值上报给 Zabbix server,从 matadata 进行归类,找到不同的 template,这样不同的实例会注册到不同的 template 下面去,才能做到自动注册的归组。
- 解注册:最难做的地方还不是注册,最难做的实际上是解注册,建议多利用云平台的云监控。用了云监控,每一个实例或者每一个资源的操作都会有一个事件,只要捕获到那个事件、分析事件的内容,然后进行 Server 端解注册工作。
运维自动化部署
我们要搭建一套广告平台,特别是多 region 部署时,非常繁琐,我可能在新加坡部署了,我可能要去美国部署,可能要去法兰克福部署。所以,在自动化部署工作上,要善用公有云提供的编排工具,阿里云叫 ROS,AWS 叫 CloudFormation。
编排工具属于一类特殊语言,内容是一个 yaml 文件,包含你所有利用的资源,资源内的一些环境处理、镜像和一些网络的创建都可以在里面预先设定好,设定好后可直接实现一键部署基础环境。

云上成本优化的五个方向

我们用云是因为它的成本,但如果用不好云,成本反而比 IDC 要高。
在成本节省方面有五个方向和大家分享一下:
1. 成本可以节省最高的一个方案—抢占式实例。抢占式实例是一种按需实例,相对于按量付费实例价格有一定的折扣,充分利用抢占式实例来节约计算成本,最大可节约 90% 的计算成本。

2. 弹性伸缩。用了弹性伸缩后,才能认为我们的业务是上云了,你用了弹性伸缩以后,成本最少可以减少 30% 左右。
3. 多利用 OSS 的特性,不是所有东西都要放在计算节点上作为存储。OSS 其实有标准计费、低访问计费、归档计费和冷存储计费多种计费形式。可以写一个自动化的脚本或者自动化的工具来检查这些数据的访问频率,将他们转化成不同的计费方式,可以很大程度上减少存储费用。
4. 控制资源方面。要定期清理空闲资源,也是一笔不小的费用节省。
5. Tag。合理利用 Tag 做好分组,按照不同 team 进行分组,就可以知道各家的用量,进行成本归类,分析优化点。

最后介绍一下我们自研的一个 SpotMax 工具,它增强了像伸缩组关于 Spot 实例的用法。解决如当遇到 Spot 回收情况下该怎么做或者当遇到资源不足情况下该怎么做的问题。
这个功能最基础的一点是当遇到 Spot 实例回收的情况下,提前补充资源,然后补充到 scaling 里面,这样就不会有一个损失。最基础的功能是,像抢占式实例会提前告知你下线时间,让你有一定时间补充新资源,以替代旧资源。再进阶一点,当想去补充时,可能拿不到抢占式实例 Spot。这时就尝试补充一个按需机器,补完后后再去探测,当能够拿到 Spot 时,再替换按需实例。
同理扩容失败也是一样,扩容用 Spot scaleup。但扩容失败,就补充一些按需实例,按需补进后会继续去轮询,能够拿到 Spot 时再把按需的替回来。这既能够保证这个服务业务的稳定性,也能保证使用的成本是最低的。
基于这种方案,我们自研了 SpotMax。SpotMax 现在可以节省最多 90% 的成本。
当前 Spot 实例支撑了汇量科技全球广告业务的发展,并取得了很不错的成果:广告平台是中国第一,全球排名前十,覆盖的流量国家有 200 多个,广告的日请求大概 1000 亿次以上,一些模型特征都在百亿级以上,但是广告平均响应时间基本上都在 50 毫秒以下。
以上是关于企业如何高效用云?| 资深运维架构师细说云架构下的运维体系构建的主要内容,如果未能解决你的问题,请参考以下文章