平均负载 启动服务 启动流程
Posted 晨曦007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了平均负载 启动服务 启动流程相关的知识,希望对你有一定的参考价值。
ltrace 跟踪进程调用库函数
ltrace 能够跟踪进程的库函数调用,它会显现出哪个库函数被调用,而strace则是跟踪进程的每个系统调用。
参数选项 解释说明(带※的为重点)
#-c 统计库函数每次调用时间,最后程序退出时打印摘要
#-C 解码低级别名称(内核级)为用户级名称
#-d 打印调试信息
#-e expr 输出过滤器,通过表达式,可以过滤掉你不想要的输出※
#-e printf 表示只查看printf函数调用
#-e !printf 表示查看除printf函数以外的所有函数调用
#-f 跟踪子进程
#-o filename 将ltrace的输出写入文件filename
#-p pid 指定要跟踪的进程pid※
#-r 输出每一个调用的相对时间
#-S 显示系统调用
#-t 在输出中的每一行前加上时间信息。例子:16:45:28
#-tt 在输出中的每一行前加上时间信息,精确到微秒。例子:11:18:59.759546
#-ttt 在输出中的每一行前加上时间信息,精确到微秒,而且时间表示为unix时间戳。
#-T 显示每次调用所花费的时间
#-u username 以username 的UID和GID执行被跟踪的命令
ltrace -o nginx.log /application/nginx/sbin/nginx
#进程管理总结。
1.找出有问题的进程
top ps pstree pgrep
2.调整优先级
nice renice
3.杀进程
kill,killall,pkill
4.进程前后台切换
ctrl+z,bg,fg,jobs,kill %1
& 后台运行
nohup 配合&,让程序放到后台运行,并且打印输出到日志里。
screen #保持操作的会话,使之不中断。运维人员客户端xshell用。
5.进程里面在干什么(nginx php mysql)
strace,ltrace,gdb
平均负载 load average
#平时只看负载查看方式 uptime w top cat /proc/loadavg
cat /proc/cpuinfo可以查看CPU信息。
#平均负载是衡量系统繁忙的一个综合指标,主要是CPU,IO的繁忙程度。工作中非常常用,具体哪个指标繁忙
ps,top,sar看CPU,iostat,iotop看磁盘。
一个进程产生到持续运行要是占用很多资源;1.PID,2.内存。3.文件描述符。4.CPU,5.磁盘。
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数。
系统平均负载被定义为在特定时间间隔内【CPU运行队列中的平均进程数】。如果一个进程满足以下条件则其就会位于运行队列中:
当CPU完全空闲的时候,平均负荷为0;当CPU工作量饱和的时候,平均负荷为1。
三个数分别是1分钟、5分钟、15分钟内系统的平均负荷。
#STAT:该进程目前的状态,主要的状态包括
R :正在运行或者是可被运行。
S :正在中断睡眠中,可被某些信号(signal) 唤醒。
D :不可中断睡眠。
T :正在侦测或者是停止了。
Z :已经终止,但是其父进程无法正常终止他,造成 zombie (僵尸) 进程的状态。
2.可运行状态和不可中断状态是什么***
#1.可运行状态进程:
是指正在被CPU处理或者正在等待CPU处理的进程,
ps命令看到处于R状态的进程。可运行状态: S R 占用cpu
#2.不可中断进程,
系统中最常见的是等待硬件设备的I/O响应,
ps命令中看到的D 状态进程。
平均负载其实就是【单位时间内的活跃进程数】。
#总结:15分钟负载值12,是高是低呢
负载数值/总的核心数=1 #开始慢的临界点,实际上1*70%==关注的临界点。
12/8=1.2 大于1就说明有问题。
负载不要超过5,是临界点。
2颗单颗4核CPU,共8核,负载就是8*70%=5左右。
需要关注负载的值:总的核心数*70%=关注的点
#负荷
系统负荷持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。
当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。
当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。
你不应该让系统达到这个值。
#查看CPU核心数
查看物理CPU个数,uniq是去重的意思:
grep "physical id" /proc/cpuinfo|wc -l
grep -c "physical id" /proc/cpuinfo
# 查看每个物理CPU中core的个数(即核数):
grep "cpu cores" /proc/cpuinfo|wc -l
#查看逻辑CPU的个数(用于计算负载)
grep "processor" /proc/cpuinfo|wc -l
#如何查看Linux系统的cpu核数和颗数?
#解答
1.top 按1
2.lscpu
3.# 查看物理CPU个数,uniq是去重的意思:
grep "physical id" /proc/cpuinfo|wc -l
# 查看每个物理CPU中core的个数(即核数):
grep "cpu cores" /proc/cpuinfo|wc -l
# 查看逻辑CPU的个数
grep "processor" /proc/cpuinfo|wc -l
1.平均负载和cpu使用率有什么直接的关系?
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在
使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。
2.如何查看平均负载
三个数值都需要关注 综合评估考虑是cpu使用率高,还是cpu的IO等待过多造成过高大量使用cpu
进程造成过高
#平均负载案例分析实战 三种场景
#环境:
yum install stress -y
yum install sysstat -y
用 stress、mpstat、pidstat 等工具,找出平均负载升高的根源。
stress是Linux系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
mpstat是【多核CPU性能分析工具】,用来实时查看每个CPU的性能指标,以及所有CPU的平均指标。
pidstat是一个常用的【进程性能分析工具,用来实时查看进程的CPU、内存、I/O 以及上下文切换等性能指标。
#如果出现无法使用mpstat、pidstat命令查看%wait指标建议更新下软件包
yum install sysstats -y
yum install stress -y
stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s
场景一:CPU 密集型进程
终端一运行stress 命令,模拟一个CPU使用率100%的场景。
#1 stress --cpu 1 --timeout 600
#2 uptime 查看平均负载的变化情况 使用watch -d 参数表示高亮显示变化的区域(注意负载会持续升高)
#3 运行 mpstat 查看 CPU 使用率的变化情况*
# -P ALL 表示监控所有CPU,后面数字5 表示间隔5秒后输出一组数据 #命令:mpstat -P ALL 5
单核CPU,所以只有一个all和0
从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。那么,到底是哪个进程导致了 CPU 使用率为 100% 呢?可以使用 pidstat 来查询
#4 间隔5秒输出一组数据
pidstat -u 5 1
#从这里可以明显看到,stress进程的CPU使用率为100%。
#思路:
- 模拟cpu负载高 `stress --cpu 1 --timeout 100`
- 通过uptime或w 查看 `watch -d uptime`
- 查看整体状态mpstat -P ALL 1 查看每个cpu核心使用率
- 精确到进程: pidstat 1
场景二:I/O 密集型进程
终端一运行 stress 命令,模拟 I/O 压力,即不停的执行 sync
#1 stress -io 1 --timeout 600 #利用sync()
stress --hdd 8 --hdd-bytes 1g # hd harkdisk 创建进程去进程写
#2 运行 uptime 查看平均负载的变化情况
watch -d uptime
#3 运行 mpstat 查看 CPU 使用率的变化情况
显示所有CPU的指标,并在间隔5秒输出一组数据 # mpstat -P ALL 5
会发现cpu的与内核打交道的sys占用非常高
#4用 pidstat 来查询
间隔5秒后输出一组数据,-u 表示CPU指标 # pidstat -u 5 1
#可以发现,还是 stress 进程导致的。
#思路:
- 通过stress 模拟大量进程读写 `stress --hdd 4 `
- 通过w/uptime查看系统负载信息 `watch -d uptime`
- 通过top/mpstat 排查 `mpstat -P ALL 1 或 top 按1`
- 确定是iowati `iostat 1查看整体磁盘读写情况 或iotop -o 查看具体哪个进程读写`
- 根据对应的进程,进行相关处理.
场景三:大量进程的场景 高并发场景
终端一运行 stress 命令,模拟 I/O 压力,即不停的执行 sync
#1 stress -c 4 --timeout 600
#2 top观察 由于系统只有1个CPU,明显比4个进程要少得多,因而,系统的CPU 处于严重过载状态*
#3运行 pidstat 来看一下进程的情况
间隔5秒后输出一组数据 # pidstat -u 5 1
#可以看出,4 个进程在争抢 1 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。*
小结
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源****
系统负载的计算和意义
进程以及子进程和线程产生的计算指令都会让cpu执行,产生请求的这些进程组成"运行队列",等待cpu执行,这个队列就是系统负载, 系统负载是所有cpu的运行队列的总和.
[root@oldboyedu ~]# w
20:25:48 up 95 days, 9:06, 1 user, load average: 2.92, 0.00, 0.00
#假设当前计算机有4个核心的cpu,当前的负载是2.92
cpu1 cpu2 cpu3 cpu4
2.94/4(个cpu核心) = 73%的cpu资源被使用,剩下27%的cpu计算资源是空想的
#假设当前的计算有2个核心的cpu,当前的负载是2.92
2.92/2 = 146% 已经验证超过了cpu的处理能力
日常故障排查流程
- w/uptime, 查看负载
- ps aux/top 看看 cpu百分比, io wait或者是内存占用的高? (三高 cpu,io,内存)
- top检查具体是哪个进程,找出可疑进程
- 追踪这个进程使用情况,做什么的?
- 看看对应**日志**是否有异常
- 系统日志: /var/log/messages(系统通用日志) /var/log/secure(用户登录情况)
- 服务软件的日志
平均负载为多少时合理***
*最理想的状态是每个CPU核心上都刚好运行着一个进程,这样每个CPU都得到了充分利用。所以在评判平均负载时,首先你要知道系统有几个CPU核心,这可以通过 top 命令获取,或`grep \'model name\' /proc/cpuinfo`*
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用\'wait\')
- 没有被停止(例如:等待终止)
Linux系统服务管理知识
系统的运行级别
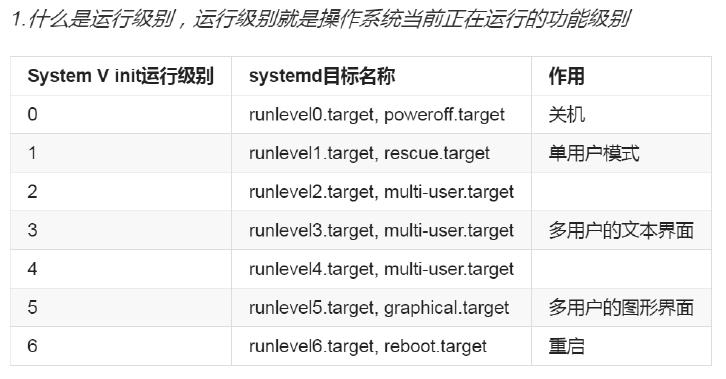
Linux运行级别就是Linux系统启动时处于不同状态标识的集合
startx #切换到桌面
启动时加载的文件(C5)
/etc/inittab
默认运行级别在/etc/inittab里设置。
id:3:initdefault: #<==系统启动时,将Linux设定固定的运行级别的配置行。
Centos 6
0 6 关机 重启
3 5 字符 图形
2 4 没有使用
1 单用户
临时性的操作
runlevel 查看当前运行级别
N 表示上一次是什么级别
init 3 切换到3级别上
永久操作 /etc/inittab
默认运行级别在/etc/inittab里设置。
id:3:initdefault: #<==系统启动时,将Linux设定固定的运行级别的配置行。
Centos 7
# runlevel0.target -> poweroff.target 0 关机
# runlevel1.target -> rescue.target 1 单用户模式 (超级权限 必须面对实体硬件)
# runlevel2.target -> multi-user.target 2 暂未使用(带NFS多用户模式)
# runlevel3.target -> multi-user.target 3 字符界面(黑框)
# runlevel4.target -> multi-user.target 4 暂未使用
# runlevel5.target -> graphical.target 5 图形界面
# runlevel6.target -> reboot.target 6 重启
#查看当前的运行级别
[root@oldboy ~]#runlevel
[root@oldboy ~]#systemctl get-default
[root@oldboy ~]#init 3 切换到3级别上
N/5 3
N 表示上一次是什么级别
startx #切换到桌面
永久操作 /etc/inittab
#修改系统下次启动时候的运行级别
[root@oldboy ~]#systemctl set-default multi-user.target
[root@oldboy ~]#systemctl enable nginx 下一次开机启动nginx,与当前无关
[root@oldboy ~]#systemctl disable nginx 下一次开机不启动nginx,与当前无关
启动状态
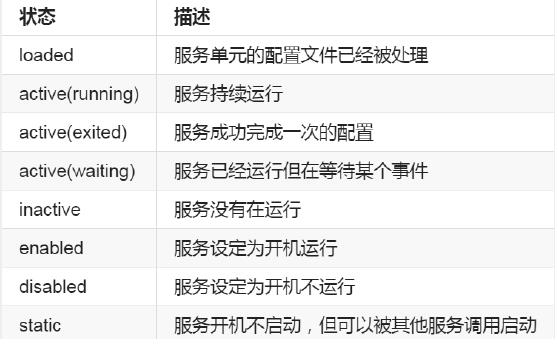
systemd知识
#什么是systemd?
Systemd(System Daemon)是CentOS7系统中的系统管理守护进程、工具和库的集合,
用于取代早期的init进程。Systemd的功能是用于集中管理和配置Linux系统。
systemd是CentOS7系统中启动的第一个进程(PID等于1),其他所有进程都是他的子进程。
#C6:服务启动方式
[root@oldboy ~]# /etc/init.d/network restart
[root@oldboy ~]# service network restart
#systemd相关路径文件
路径 描述
/usr/lib/systemd/system /etc/init.d(启动服务程序所在的路径)
/etc/systemd/system /etc/rc.d(不同运行级别启动文件路径)
/etc/systemd/system/multi-user.target.wants /etc/rc.d/rc3.d(3级别路径),文本模式
#systemd管理服务相关命令
systemctl管理服务的启动、重启、停止、重载、查看状态等常用命令
systemctl命令 作用
systemctl start crond.service 启动服务
systemctl stop crond.service 停止服务
systemctl restart crond.service 重启服务
systemctl reload crond.service 重新加载配置
systemctl status crond.servre 查看服务运行状态
启动状态
状态 描述
loaded 服务单元的配置文件已经被处理
active(running) 服务持续运行
inactive (dead) 服务停止状态
enabled 服务设定为开机运行
disabled 服务设定为开机不运行
systemctl 设置服务开机启动、不启动命令
systemctl命令 作用
systemctl enable crond.service 开机自动启动
systemctl disable crond.service 开机不自动启动
systemctl 设置服务开机启动、不启动命令原理:
#手工设置开机自启动。
在/etc/systemd/system/multi-user.target.wants/下设置快捷方式。
[root@oldboy ~]# ln -s /usr/lib/systemd/system/crond.service
/etc/systemd/system/multi-user.target.wants/crond.service
[root@oldboy ~]# systemctl status crond
Active: inactive (dead)
#手工设置开机停止启动。删除在multi-user.target.wants里的快捷方式。
[root@oldboy ~]# rm -f /etc/systemd/system/multi-user.target.wants/crond.service
[root@oldboy ~]# systemctl status crond
Active: inactive (dead)
systemctl 保留开机启动的服务
====================================
rsyslog.service enabled
sshd.service enabled
sysstat.service enabled
=========================================================
处理方法:
systemctl list-unit-files|egrep -v "network.ta|rsyslog|sshd\\.|sysstat|static"|
awk \'{print "systemctl disable "$1}\'|bash
systemctl list-unit-files|grep enabled
[root@oldboy ~]# systemctl list-unit-files|grep enabled
rsyslog.service (日志系统) enabled
sshd.service (远程连接SSHD) enabled
sysstat.service (性能监控) enabled
network (网络服务),使用chkconfig开启。
还要开启网络服务的开机自启动
systemctl enable network ####
chkconfig network on #23454个级别上开机自启动,centos7以前的设置开机自启动的命令。
[root@oldboy ~]# chkconfig --list|grep network
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
##linux服务器 开机自启动服务优化
rsyslog.service (日志系统) enabled
sshd.service (远程连接SSHD) enabled
sysstat.service (性能监控) enabled
network (网络服务),使用chkconfig开启。
其他的根据需要开启。
systemd文件格式


systemd.unit官方完整说明:
https://www.freedesktop.org/software/systemd/man/systemd.unit.html

自定义服务启动文件
PIDFile=/var/run/nginx.pid #pid文件的绝对路径
ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf #启动命令的绝对路径
ExecStop=/bin/sh -c "/bin/kill -s TERM $(/bin/cat /var/run/nginx.pid)" #停止服务命令的绝对路径
Centos6 Centos7
/etc/init.d/nginx start(纯shell脚本) systemctl start nginx(systemd启动文件)
service nginx start
chkconfig nginx on
chkconfig nginx off systemctl enable nginx
systemctl disable nginx
chkconfig --list|grep 3:on systemctl list-unit-files
/etc/init.d/nginx start
7.自定义nginx的systemd启动文件
编译安装nginx过程略。
#1.修改nginx配置文件的pid为自定义路径
[root@linux ~]# grep pid /application/nginx/conf/nginx.conf
pid /application/nginx/pid/nginx.pid;
#2.写入自定义systemd配置
cat > /usr/lib/systemd/system/oldboy_nginx.service << \'EOF\'
[Unit]
Description=DIY nginx
Documentation=https://www.oldboyedu.com/
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
PIDFile=/application/nginx/pid/nginx.pid
ExecStart=/application/nginx/sbin/nginx -c /application/nginx/conf/nginx.conf
ExecReload=/bin/sh -c "/bin/kill -s HUP $(/bin/cat /application/nginx/pid/nginx.pid)"
ExecStop=/bin/sh -c "/bin/kill -s TERM $(/bin/cat /application/nginx/pid/nginx.pid)"
ExecStartPre=/bin/sh -c "/usr/bin/chown -R www:www /application/nginx/"
[Install]
WantedBy=multi-user.target
EOF
#3.重新加载systemd配置
systemctl daemon-reload
#4.启动我们自定义的服务
systemctl start oldboy_nginx
systemctl status oldboy_nginx
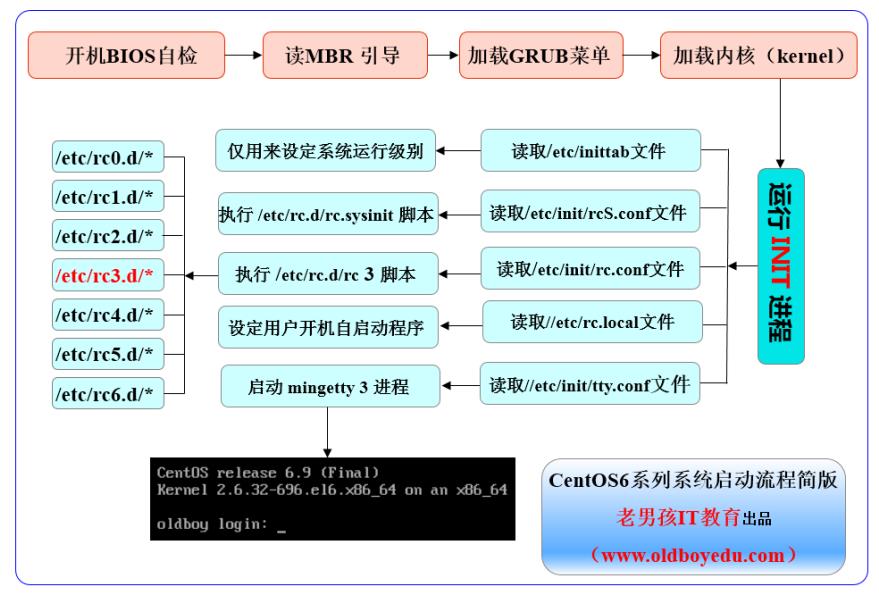
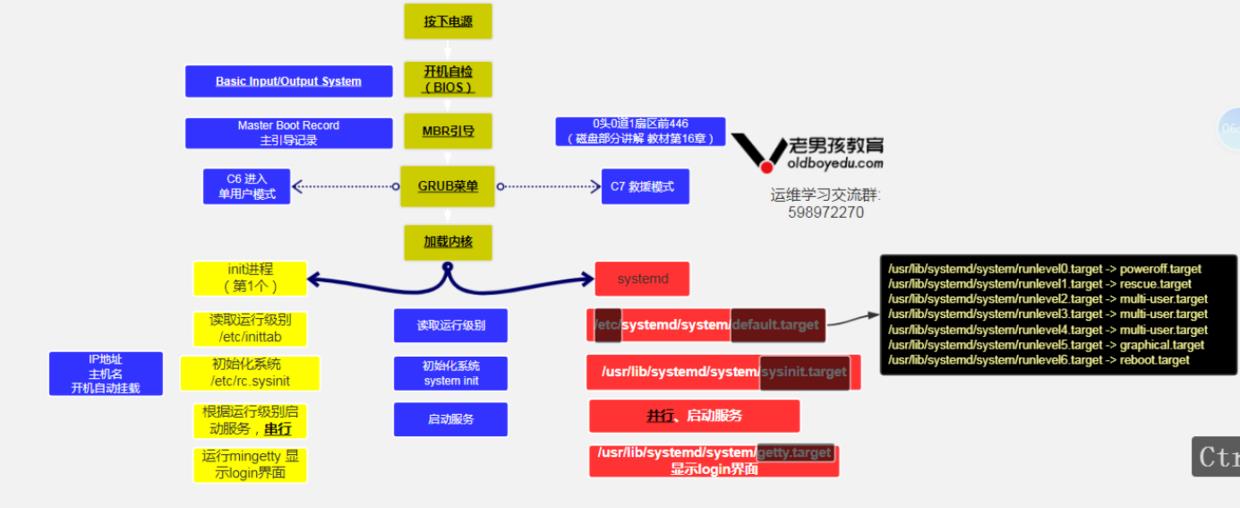
Centos6启动流程
Centos7启动流程
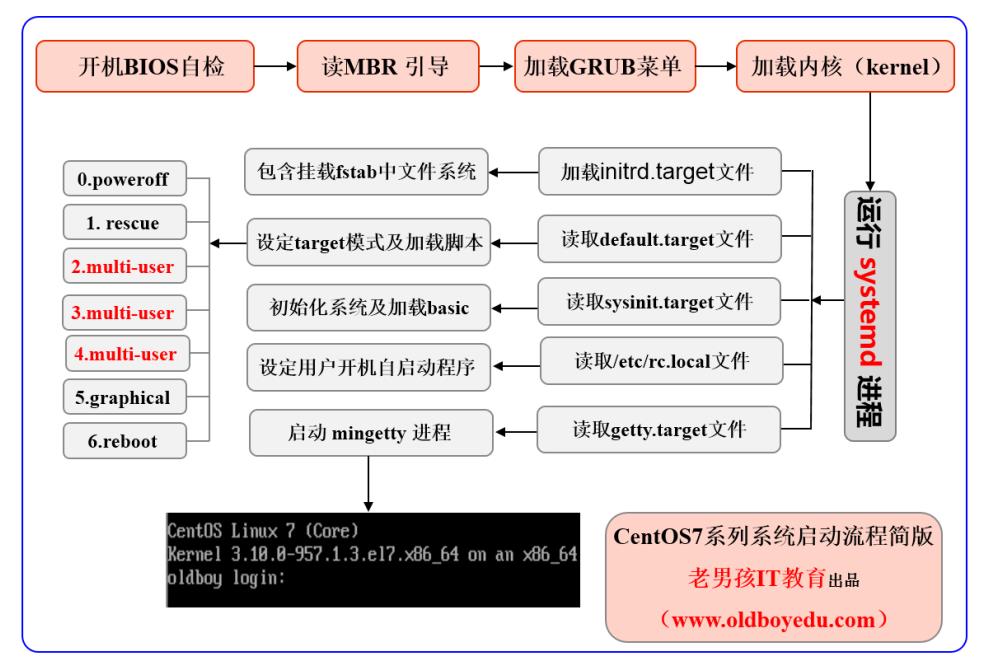
启动流程
1.BIOS开机自检
2.读取MBR信息选择启动设备
3.加载grub菜单,选择操作系统
4.加载内核及驱动程序
5.启动systemd程序加载必要文件,以下操作并行执行
1) 执行initrd.target (/usr/lib/systemd/system/initrd.target)
包含挂载/etc/fstab文件中的文件系统。
2) systemd执行默认的target配置。
3) systemd执行sysinit.target, 初始化系统及加载basic.target准备启动系统。
4) systemd启动multi-user.target (生产工作模式)下的服务程序,即开机自启动的程序,程序目录为/etc/systemd/system和/usr/lib/systemd/system。
5) systemd执行multi-user.target下的/etc/rc.d/rc.local内容。
6) systemd执行multi-user.target下的gtty.target及登录服务。
7) systemd执行graphical所需要的服务(如果安装了图形桌面功能)。
分析启动流程耗时
运行systemd-analyze blame命令可以打印出启动过程的详细流程
[root@linux ~]# systemd-analyze blame
5.043s network.service
2.609s dev-mapper-centos\\x2droot.device
1.694s lvm2-pvscan@8:2.service
1.669s lvm2-monitor.service
1.059s mysqld.service
843ms tuned.service
204ms auditd.service
171ms polkit.service
164ms rsyslog.service
128ms chronyd.service
102ms systemd-logind.service
94ms rhel-dmesg.service
93ms systemd-vconsole-setup.service
77ms sysstat.service
77ms systemd-user-sessions.service
62ms boot.mount
61ms systemd-udev-trigger.service
58ms rhel-import-state.service
50ms rhel-readonly.service
36ms plymouth-quit-wait.service
35ms plymouth-start.service
34ms systemd-udevd.service
27ms plymouth-read-write.service
26ms systemd-tmpfiles-setup-dev.service
25ms systemd-journald.service
可以将其生成网页查看
systemd-analyze plot > linux.html
Centos6与Centos7有启动什么区别?
单用户模式-->(超级用户权限的模式)
必须面对实体 服务器前
能正常引导进入系统①配置文件错误导致无法启动
忘记ROOT密码 ( 快照 | 单用户修改)
忘记root密码
重新启动或开启CentOS7.x系统后 按“e”进入编辑界面
②按方向键向下键,找到以字符串“Linux16”开头的行,将光标移动到该行的结尾,然后输入“init=/bin/bash”
ctrl +x 退出重启
注:如果系统开了SElinux
重新启动或开启CentOS7.6系统后 按“e”进入编辑界面
按方向键向下键,既在以字符串“Linux16”开头的行,将光标移动到该行的结尾,然后输入“init=/bin/bash enforcing=0”(前者作用让系统登录后加载
bash解释器,后者是且关闭Selinux)
配置完成后,输入“mount-o rw,remount/”命令是重新挂载根目录为可写状态(rw表示可写,remount是重新挂载),在单用户模式下默认根文件系统是处
于只读状态。
也可以在增加内核参数时,把以字符串“Linux16”开头的行中间部分的ro参数改为rw,则可以替代繁琐的“mount-o rw,remount /”命令
配置完后,执行exec /sbin/init命令重启系统
如果selinux已经开启需要“touch /.autorelabel
exec /sbin/init
救援模式(CD光盘-->系统)
没有内核文件,只能使用救援模式进入
把内核文件移走
bios boot CD第一启动
选3 选2
输入1 回车
chroot /mnt/sysimage/
将文件移动到/boot/下
exit reboot
选三
本地启动
系统崩溃, 要保留重要的数据的时候
添加一个硬盘
新建一个目录
格式化这个磁盘
挂载
写数据
在加一个硬盘
进救援模式
1
chroot /mnt/sysimage/
将文件复制到新的硬盘
grub菜单出现问题, linux windows
输入 1 c
chroot /mnt/sysimage/
1.使用grub修复
grub2-install /dev/sda
2.然后退出exit
3.最后重启进入系统reboot
以上是关于平均负载 启动服务 启动流程的主要内容,如果未能解决你的问题,请参考以下文章