R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=22732
原文出处:拓端数据部落公众号
关联规则挖掘是一种无监督的学习方法,从交易数据中挖掘规则。它有助于找出数据集中的关系和一起出现的项目。在这篇文章中,我将解释如何在R中提取关联规则。
关联规则模型适用于交易数据。交易数据的一个例子可以是客户的购物历史。
数据分析的第一件事是了解目标数据结构和内容。出于学习的目的,我认为使用一个简单的数据集更好。一旦我们知道了这个模型,就可以很容易地把它应用于更复杂的数据集。
在这里,我们使用杂货店的交易数据。首先,我们创建一个数据框并将其转换为交易类型。
读取数据
-
n=500 # 交易数量
-
-
trans <- data.frame() # 收集数据的数据框架
创建数据并将其收集到交易数据框中。
-
for(i in 1:n)
-
{
-
count <- sample(1:3, 1) # 从1到3的物品计数
-
如果(i %% 2 == 1)
-
{
-
if(!add_product %in% selected)
-
{
-
tran <- data.frame(items = add_product, tid = i)
检查交易数据框中的数据。

接下来,我们需要将生成的数据框转换为交易数据类型。
-
-
as(split([, "items"], [, "tid"]), "transa")
![]()
为了检查交易数据的内容,我们使用 inspect() 命令。

挖掘规则
sort(rules_1, dby = "confidence")
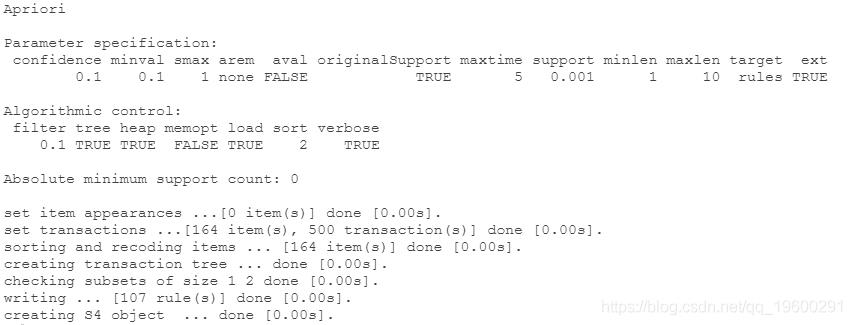
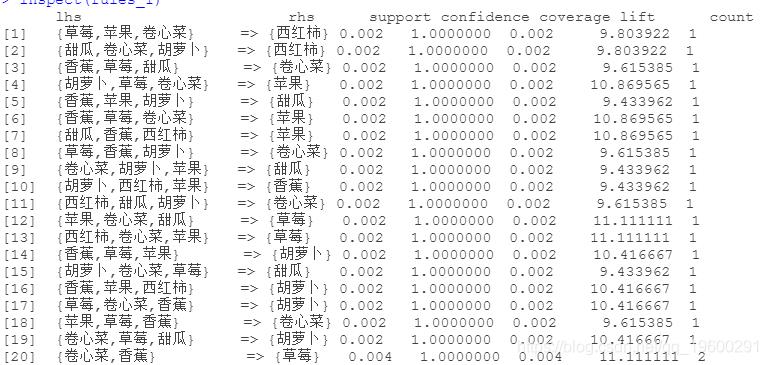
.......
我们从上面的列表中获取第一个rhs项(规则后项)来检查该项的规则。但如果你知道目标项目,可以在参数中只写rhs="melon"。
-
inspect(rules_1@rhs[1])
-
![]()
> rhs_item <- gsub("\\\\}","", rhs)
![]()
我们为我们的rhs_item建立规则
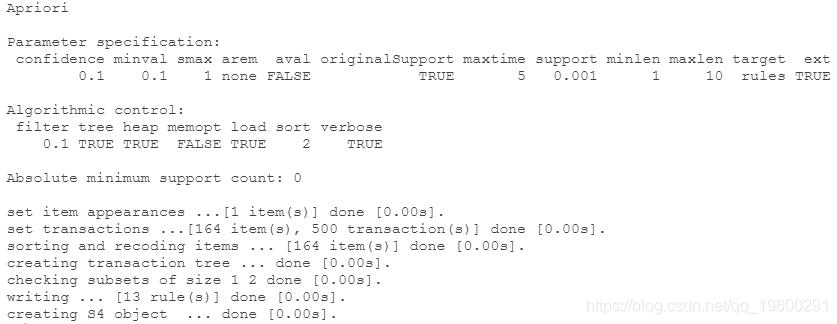
按 "置信度 "排序并检查规则
-
-
sort(rules_2, "confidence")
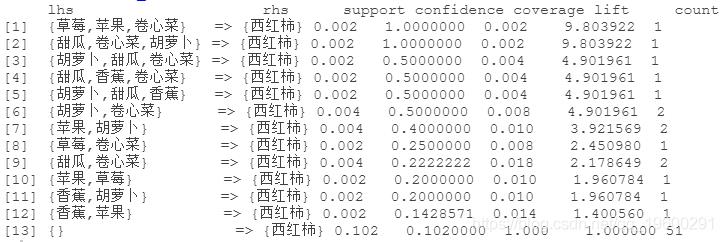
结果可视化
最后,我们从规则集_2中绘制出前5条规则。
> plot(rules_2[1:5])
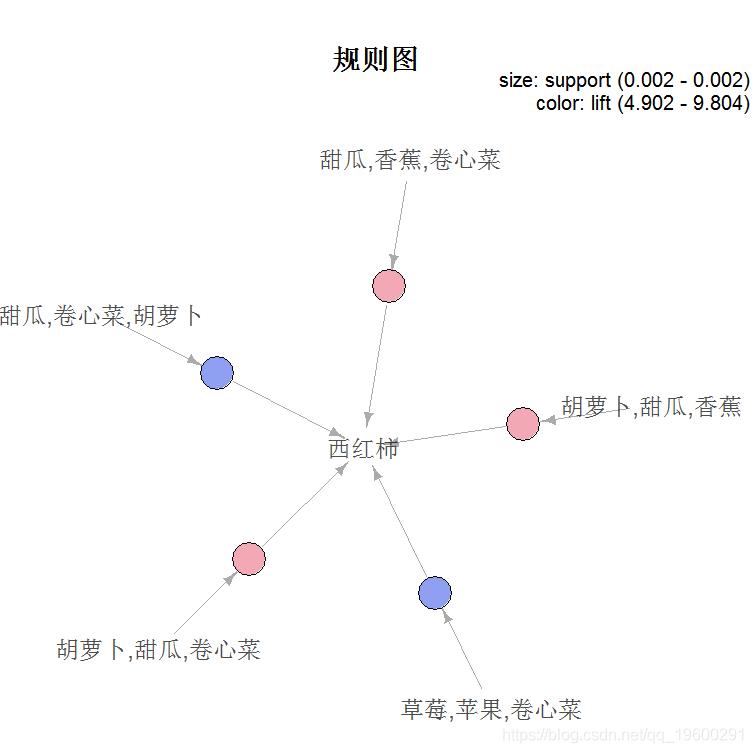
绘制全部规则
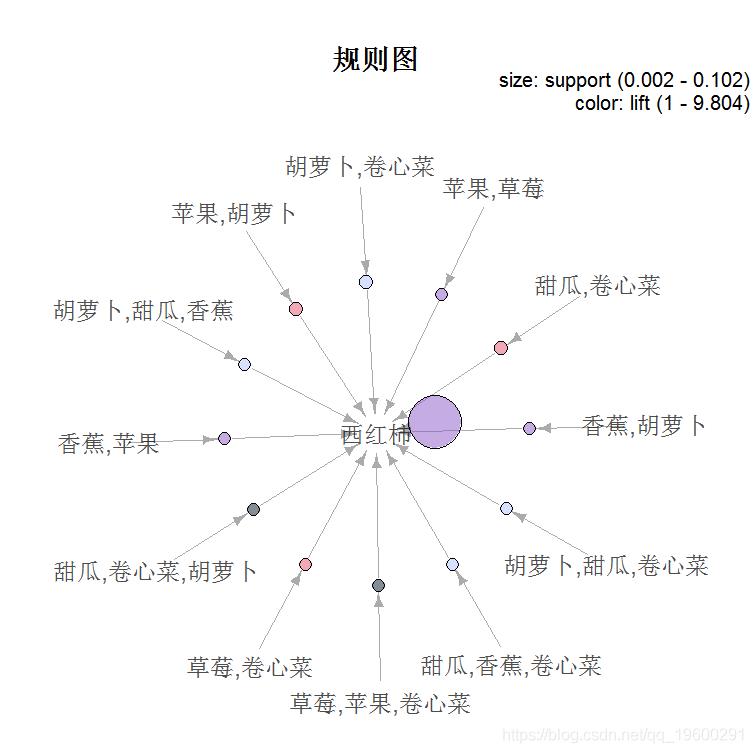
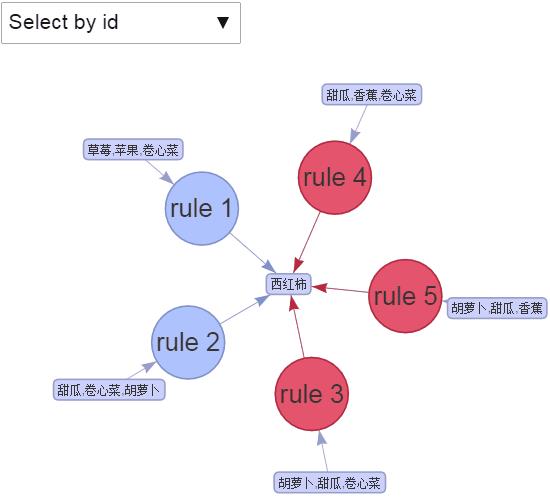
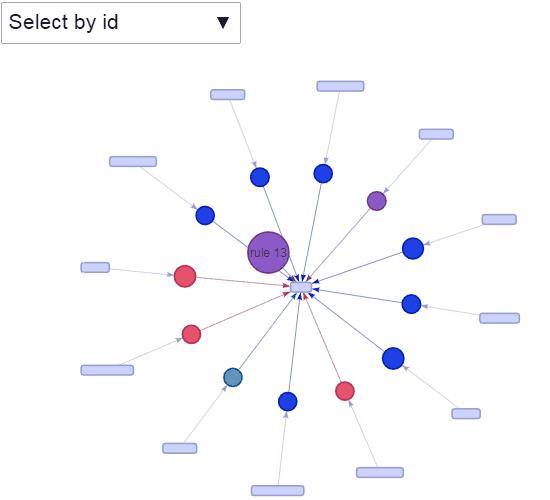
交互可视化
绘制出前5条规则
-
precision = 3
-
igraphLayout = layout_nicely
-
list(nodes = nodes, edges = edges, nodesToDataframe = nodesToDataframe,
-
edgesToDataframe = edgesToDataframe,
-
x$legend <- legend
-
htmlwidgets::createWidget( x, width = width,
-
height = height)
绘制全部规则
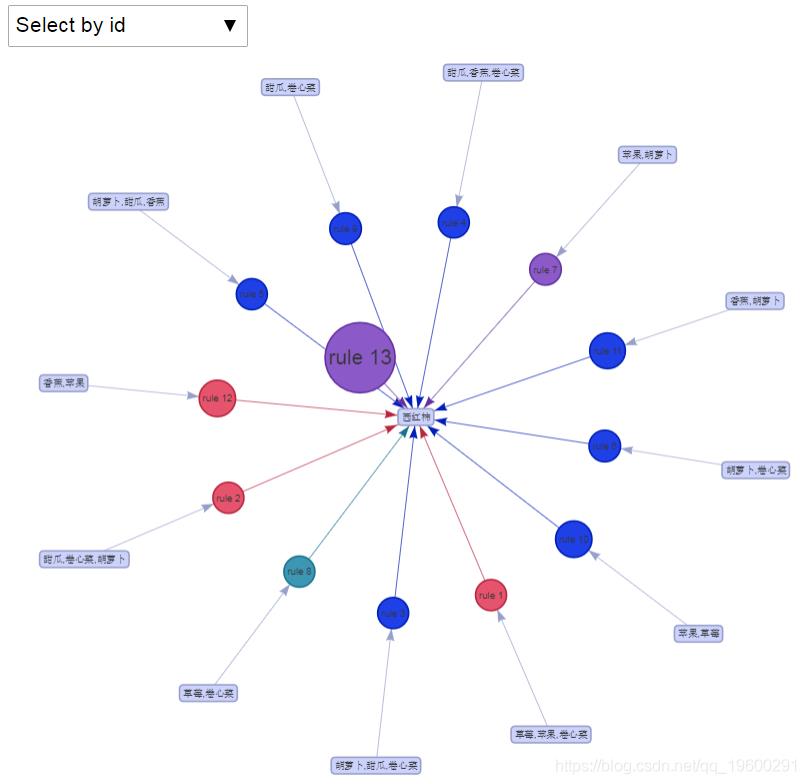

最受欢迎的见解
1.采用spss-modeler的web复杂网络对所有腧穴进行分析
3.R语言文本挖掘NASA数据网络分析,tf-idf和主题建模
以上是关于R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化的主要内容,如果未能解决你的问题,请参考以下文章